行业科普
别急着写 GQL,先学会 Graph Thinking
交流图数据库技术?加入 Nebula 交流群请先填写下「你的 Nebula 名片」,Nebula 小助手会拉你进群~~
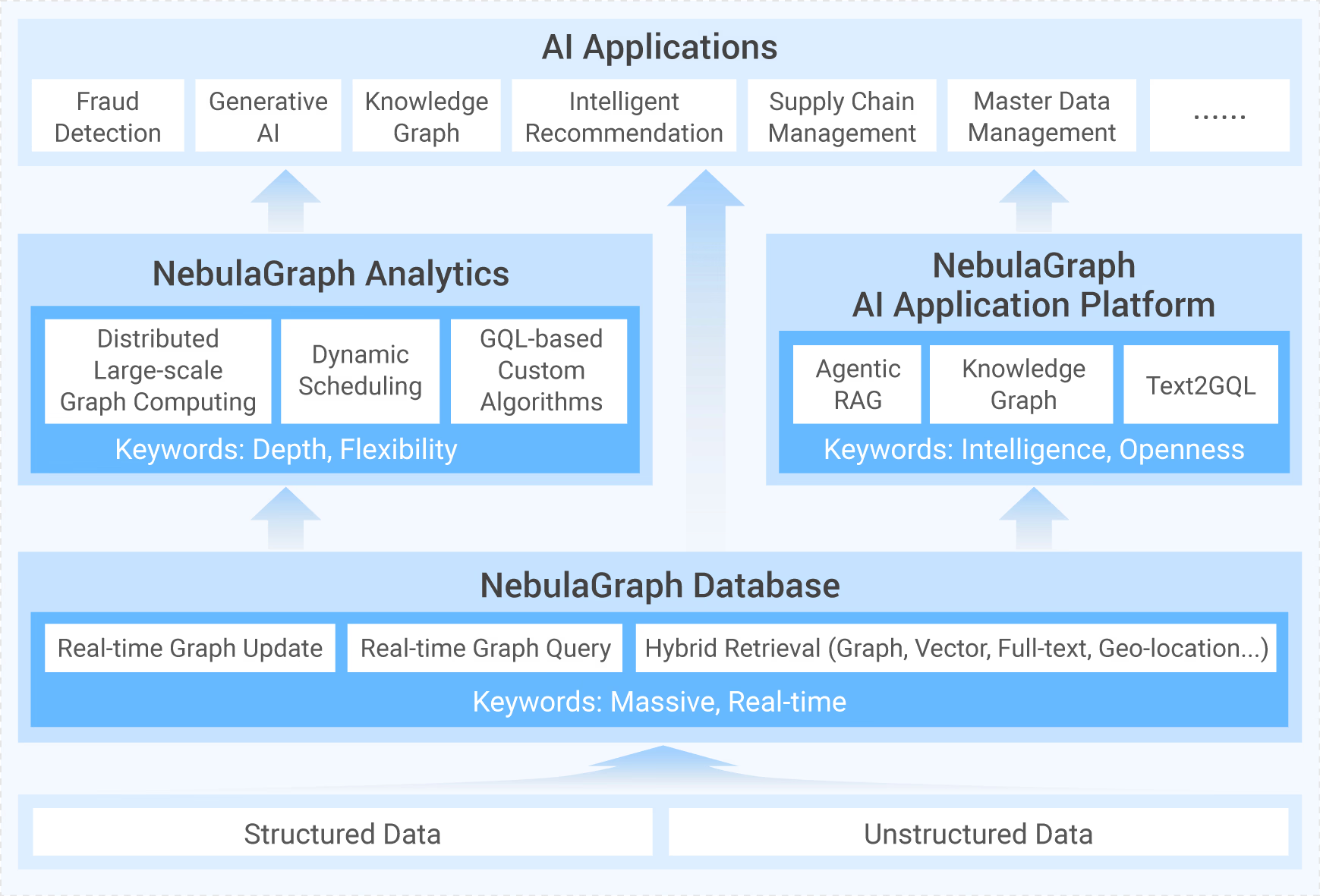
NebulaGraph 作为一款开源分布式图数据库,核心优势是处理千亿点万亿边的海量数据,并能在毫秒级返回查询结果,它在风控、推荐、知识图谱等强关联场景中几乎是标配。 随着 ISO 发布了 GQL 国际标准,NebulaGraph Enterprise v5.0 也成为了首个原生支持 GQL 的分布式图数据库。
很多开发者初次接触 NebulaGraph 时,最常问的问题就是:“ GQL 难学吗?语法复杂吗?”
GQL 是 ISO 继 1987 年发布数据库国际标准 SQL 之后,颁布的第二个数据库查询语言标准。作为 Linked Data Benchmark Council 成员,NebulaGraph 积极参与 GQL 标准的制定和推广,并且 NebulaGraph Enterprise v5.0 是第一个原生支持 GQL 的分布式图数据库。
其实在真实业务场景中,真正决定能不能把图数据库用好的,从来不是语法,而是:是否真的完成了从关系型思维到图思维(Graph Thinking)的转变。
⚠️本文的 GQL 完全遵循 NebulaGraph 5.x,与 3.x 存在一定区别喔~
一、为什么 SQL 很难描述多跳关系?
我们先从一个简单场景开始。
“用户 A,在 3 层关系以内,是否和用户 B 存在潜在关联?”
在传统关系型数据库中,常见做法是:
- 一张用户表。
- 一张关系表。
- 如果关系复杂,还得加中间映射表。
- 然后,疯狂地 JOIN.
你的 SQL 往往长这样:
SELECT *
FROM user u1
JOIN relation r1 ON u1.id = r1.src
JOIN relation r2 ON r1.dst = r2.src
JOIN relation r3 ON r2.dst = r3.src
WHERE u1.id = 'A' AND r3.dst = 'B';
这种写法的痛点显而易见:
- 硬编码: JOIN 的层数被死死地写在代码里。如果业务想查 5 跳、10 跳,SQL 会长到让你怀疑人生。
- 语义缺失: SQL 只负责把表拼起来,它并不理解这层 JOIN 到底是“关注”、“转账”还是“亲属关系”。
- 性能瓶颈: 关系是查询时,临时“算”出来的结果,而不是数据本身。
总之,关系在 SQL 里,是被拼出来的结果,而不是模型的一部分。
二、关系是图数据库的核心
图数据库的核心逻辑很简单:数据由点(Vertex)和边(Edge)组成,分别是实体与关系的代表,属性可以挂在任何一边。
因此,在图数据库中,还是上述同样的问题,但建模从一开始就不同。
“用户 A,在 3 层关系以内,是否和用户 B 存在潜在关联?”
(一)建模即连接
在图数据库里,不再是把数据往表里塞,查询时才去拼凑的逻辑映射,而是直接构建关系网络。
对于图数据建模,你只需要简单的三步。
1. 创建 Graph Type
CREATE GRAPH TYPE IF NOT EXISTS fans_t AS {
NODE User (LABELS User {id INT PRIMARY KEY, name STRING}),
EDGE FOLLOW (User)-[{strength INT}]->(User)
}
2. 创建 Graph
CREATE GRAPH IF NOT EXISTS fans TYPED fans_t
3. 插入点(Vertex)和 关系 (Edge)
USE fans INSERT
(u1@User{id:1, name: "A"}),
(u2@User{id:2, name: "C"}),
(u3@User{id:3, name: "B"}),
(u1)-[l1@FOLLOW{strength:100}]->(u2),
(u2)-[l2@FOLLOW{strength:60}]->(u3),
(u1)-[l3@FOLLOW{strength:110}]->(u3)
无需转换业务逻辑,直接依据业务语义建模。
(二) 查询语句 = 业务语言
回到刚才的 3 跳关联问题,在 GQL 中,你只需要:
USE fans
MATCH (s:User{name:"A"})-[e1]->(t)-[e2]->(r:User{name:"B"})
RETURN s, r
这段代码几乎就是业务白话,没有 JOIN,没有中间表,查询路径就是业务逻辑。
(三)边自带业务语义
SQL 很难优雅地处理关系的属性,但在图里,边可以承载非常丰富的信息。比如我们要找出“关注强度 > 70”的关系:
USE fans
MATCH (s)-[e1]->(t)
WHERE e1.strength > 70
RETURN e1
这里的 strength 是直接存在边上的。在 SQL 中,你可能得去中间表查字段,但在图中,过滤直接发生在路径扫描的过程中。
三、路径查询天然可解释
在风控或合规审计中,系统仅仅判定“A 和 B 有风险关联”是不够的,必须给出证据链。
SQL 很难直接吐出整条链路,而在 GQL 中,你可以直接返回路径。
例如,在金融风控场景中,从 ID 为 0 的账户出发,查询通过 10 次转账到达 ID 为 10 的节点的所有路径:
USE finance_trace_graph
MATCH p=(s:Account{id: 0})-[e@TRANSFER]->{10}(t:Account{id: 10})
RETURN p
⚠️此处省略图数据建模相关步骤
运行结果如下:
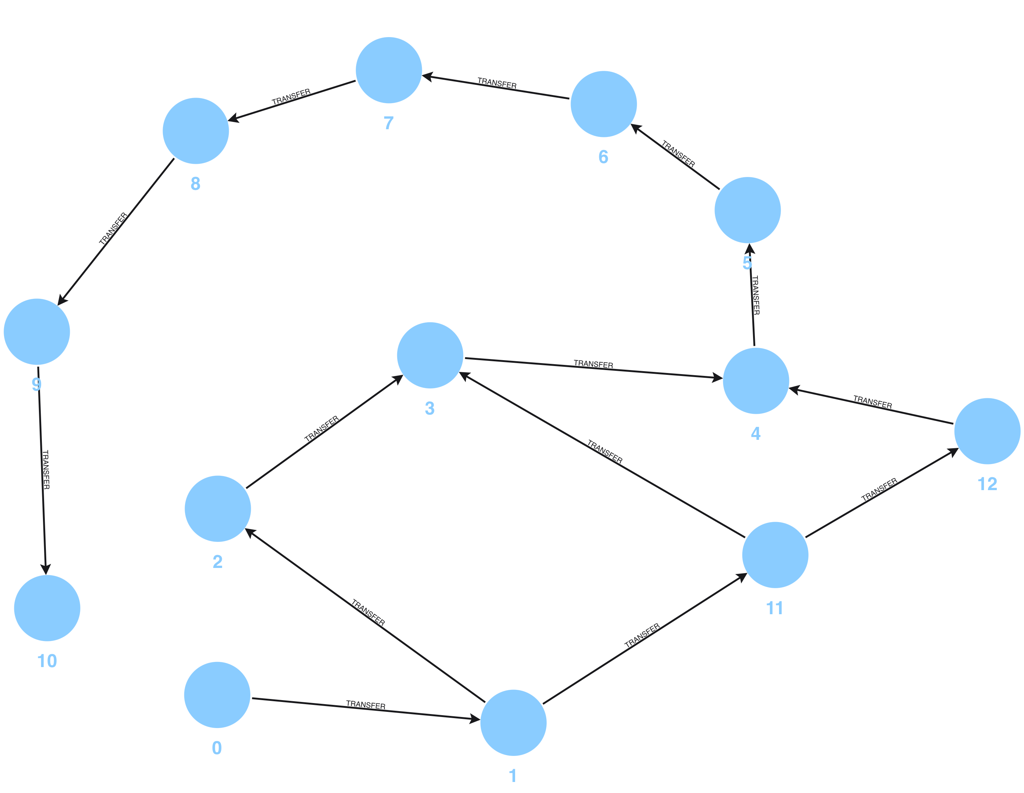
返回的结果是一个完整的图路径:经由了哪些节点、通过了什么动作、每一跳的权重是多少。 这种天然的可解释性,是关系型数据库无法比拟的。
四、写 GQL 的正确姿势
很多习惯了 SQL 的开发者,刚转到 NebulaGraph 时会习惯性地:
- 把 GRAPH 当成 MySQL 的表
- 把 MATCH 当成普通的 SELECT
- 忽视图语义,当一个不用写 JOIN 的关系数据库用
结果往往是图的优势没用上,性能和可维护性都不稳定。
写 GQL 的正确姿势永远是:
- 先画出关系
- 再定义 Edge 的语义:明确边代表什么动作(如关注、交易、授权)。
- 最后才是写查询:思考从哪个点出发,走几步,止于何处。
四、Ending
GQL 改变的不只是语法,它迫使我们把“关系”放进数据模型的第一行。这是从其它数据库转型图数据库后,最需要学习并强化的图思维。
当你开始重视关系,开始思考,谁和谁有关系,关系如何被链接,在多远的范围内有关联,你会发现,GQL 并不神秘,图数据库也不再抽象~
交流图数据库技术?加入 Nebula 交流群请先填写下「你的 Nebula 名片」,Nebula 小助手会拉你进群~~