
技术分享
多年 NLP 从业者对 LLM 和知识图谱的一些看法
关于本文作者 Louis Guitton:曾任德国柏林 OneFootball Labs 的副总裁,在 NLP 领域、推荐系统、MVP 构建和 Flow 区块链方面有丰富的经验。 近一年大家没少被 LLM 相关的新闻刷屏,在本文 Louis Guitton 将同你分享在他这个 NLP 领域多年从业者对 LLM 和知识图谱的看法。
在之前的 Graph + LLM 三部曲中,我们了解到知识图谱可以基于 Graph RAG(图 RAG)为 LLM 提供事实依据,并且成本可能比 Vector RAG(向量 RAG)更低。在本文,你将进一步了解到当中的差异,以及 Graph RAG 的便捷。
*注:本文是作者在 2024 年 2 月 15 日举办的“生产中的 AI”在线会议上的分享,演讲链接: https://home.mlops.community/public/events/ai-in-production-2024-02-15。
回顾 2019 年 spaCy IRL 大会
spaCy 是一个流行的 NLP 工具库,用于执行各种语言处理任务,例如词性标注、命名实体识别、依存句法分析等。
在 LLM 爆火之前,我已经从事自然语言处理(NLP)研究工作好几年,自然也就见证了大型语言模型(Large Language Models)的崛起。我在 NLP 和图谱方面的工作可以追溯到 2018 年,那时我在德国柏林的足球媒体公司 OneFootball 任职机器学习工程师,在那时我开始将相关技术应用到体育媒体领域。
作为一名从业者,我对那段时间记忆犹新,因为那是 NLP 领域发生巨变的时期。我们从基于规则的系统和词嵌入时代进入到深度学习时代,从 LSTM 转向了基于 transformer 架构的一系列模型,如 ELMo 或 ULMFiT。作为少数能参加在柏林举行的 spaCy IRL 2019 会议的幸运儿,我同其他人一起交流了关于 transformer、会话型 AI 助手以及在金融或媒体领域的应用的 NLP 的看法。

图注:Spacy IRL 2019 keynote by Sebastian Ruder

图注:会议现场照
在主题演讲《The missing elements in NLP (spaCy IRL 2019) 》(NLP 缺失的元素)中,Yoav Goldberg 曾预测 NLP 领域下一个重大进步是使非专家能够使用 NLP。某种程度,至少从结果上看,他是对的。他认为我们将通过人类编写规则的方式实现,这些规则有深度学习的辅助,从而产生透明且可调试的模型。但,方式错了。我们仅仅通过聊天就能实现这一点,而且现在的模型透明度更低,以及可调试性差了点意思。现在,我们在他的图表上进一步向右下方移动(见下图),我们到了一个比深度学习更远的地方。至于能否向更透明的模型迈进,领域专家们只用少量数据就能让模型干活,这点我们目前没有一个定论。

回到我之前说到过的 OneFootball 工作,在这家支持 12 种语言、每月有 1,000 万活跃用户的足球媒体公司,我们用 NLP 帮新闻编辑室解锁了新的产品功能:我建立了一套系统,来提取网站文章中的实体和关系、给新闻打上标签,以及向用户推荐相关文章。这块的工作,我在柏林的一次 NLP 聚会上分享过。我们有中等的数据量,不算多。前面提过给新闻打标签工作,其实我们还有部分的标签重打工作,因为我们付不起太多的计算成本,所以只能借助 NLP 来提升效能。
在深入 NLP 应用的过程中,我无意间了解到了 Graph(图)这个概念。这不得不提下我的朋友 Paco Nathan(多部关于机器学习、自然语言处理、图技术及相关主题的书籍和流行视频教程的作者),以及他的优秀的 PyTextRank 真是帮上大忙了。图,与基于规则的匹配器、弱监督,再加上我多年的 NLP 经验,帮我自动地处理了部分的注释数据工作。此外,在构建系统的同时,系统还融入了领域专家的声明式知识,非专业人士也能使用,甚至是维护这套系统。还有提的一点是,这个系统具备了一定程度的人机合作能力。于是,我们推出了一个更好的标签系统及新的推荐系统。借助图技术来完成这一套的工作,让我觉得太有意思了。
所以,当 LLM 兴起,我看到图和 LLM 二者结合的潜力,我一定要和你分享下下面的事情。
事实归因与图 RAG
微调 vs 检索增强生成
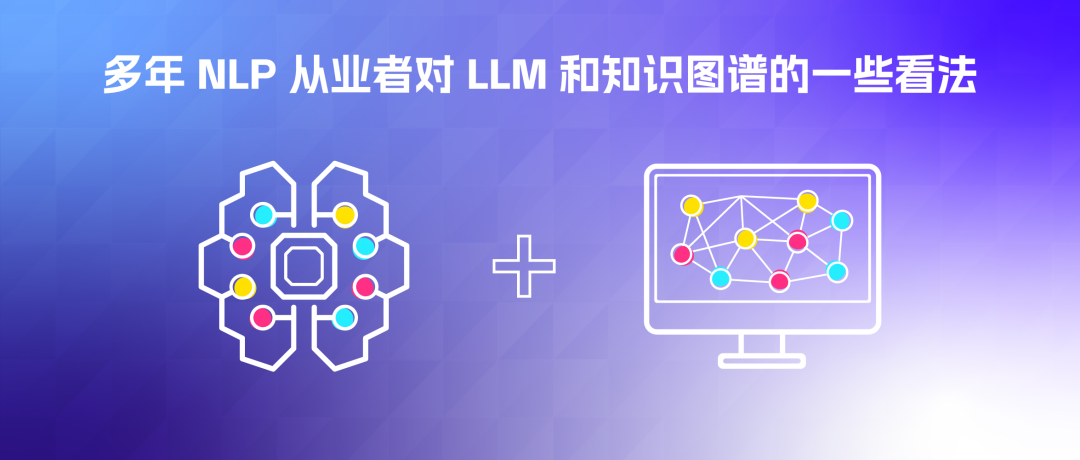
图和 LLM 第一个交集便是事实归因。大家都知道,LLM 目前存在一些问题,比如:幻觉、知识截断、偏见和失控。为了绕开这些问题,人们开始转向可用(可信) 的领域数据。尤其是在两种技术:微调(Fine Tuning)和检索增强生成(Retrieval-Augmented Generation, RAG)出来之后。
在三个月前的 AI 大会上,Anyscale 首席科学家 Dr. Waleed Kadous 在他的演讲 LLMs in Production 中,对这两种方式的抉择权衡提供了一些见解。他说:“微调是针对形式而非事实的。”、“而 RAG 是针对事实的。”
像是 OpenAccess-AI-Collective/axolotl、huggingface/trl 之类的开源库的存在,让微调变得更容易、更便宜。虽然难度和成本都降低了,但微调还是那个资源密集的工作,而且要以此为生的话,NLP 技术得更成熟才行。与此同时,另一边的 RAG 也变得更容易获取了。2 个月前,Hacker News 上有个咨询贴《2023 年 12 月了,有哪些方式来基于文档定制我的 LLM/ChatGPT?》,里面大多数的回复(从业者)都在用 RAG 而非微调。
Vector RAG vs Graph RAG
一说到 RAG,一般人们指代是基于向量数据库的检索系统,即 Vector RAG。但是在 NebulaGraph(一个开源的图数据库)的博客和教程中,介绍了一种称之为 Graph RAG 的替代方法,这是一种基于图数据库的检索系统。他们展示了不同的架构中 RAG 系统检索的事实是如何的不同。
在 LlamaIndex 的 KnowledgeGraph vs VectorStoreIndex vs 混合 Index 结果对比中,提到与 Vector RAG 相比,Graph RAG 更简洁,在 token 开销方面更加便宜。
RAG 概览
为了方便你理解不同的 RAG 架构,这里放出了我绘制的图表:
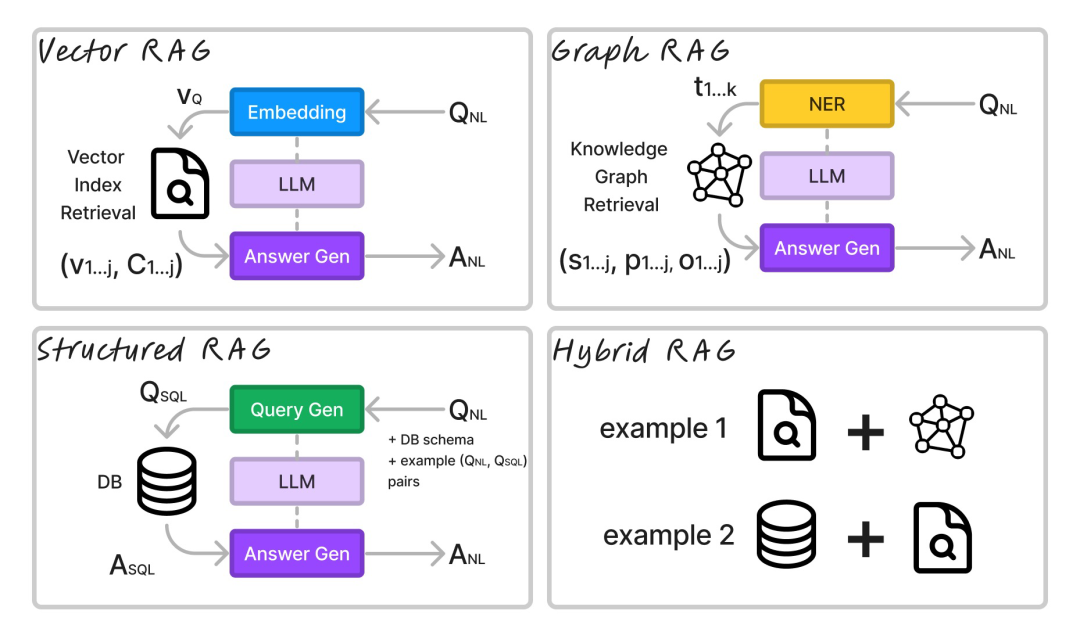
图注:Differences and similarities of the RAG architectures
在绝大多数情况下,我们会以自然语言问问题 ,再得到一个自然语言的回复 。而系统这边的处理流程就是,编码模型提取问题的结构后,同生成模型(答案生成器)一起生成对应的答案。
Vector RAG 将查询嵌入到向量 VQ中,通常它会使用比 LLM 小的模型,像是 Flag Embedding 或者是 Huggingface 这些嵌入排行榜上主流的小型模型。然后,从向量数据库里检索出与VQ最相近的 TOP K 个文档块,并将这些作为向量和块(vj,cj)返回。这些块连同Qnl 一起作为上下文传给 LLM 生成答案ANL 。
Graph RAG 从查询中提取关键词kj,并检索与关键词匹配的图中的三元组。然后,它将这些三元组(Sj, pj, 0j)连同 QN 一起传递给 LLM 生成答案 ANL。
Structured RAG 使用生成模型(LLM 或更小的经过微调的模型)来生成数据库查询语言中的查询。它可以为关系型数据库生成一个 SQL 查询,或者为图数据库生成一个 Cypher 查询。例如,我们想查询一个关系数据库:模型将生成QSQL,再传给数据库来检索答案。如果留意AsQz 的话,都是从数据库运行 QSQL得到的数据记录。答案 ASQL 以及QNL 都会传给 LLM 来生成ANL 。
在混合 RAG 情况下,系统会结合了上述所有方法。因为混合技术不在本文的讨论范畴,总之记住有很多种混合技术。当中最简单的是,传递更多上下文给 LLM 用于答案生成,并让它利用摘要能力强化生成的答案。
LlamaIndex 中的 Graph RAG 实现
现在,来看下使用当前的框架,10 行 Python 代码构建出来的 Graph RAG 系统。
`
from llama_index.llms import Ollama
from llama_index import ServiceContext, KnowledgeGraphIndex
from llama_index.retrievers import KGTableRetriever
from llama_index.graph_stores import NebulaGraphStore
from llama_index.storage.storage_context import StorageContext
from llama_index.query_engine import RetrieverQueryEngine
from llama_index.data_structs.data_structs import KG
from IPython.display import Markdown, display
llm = Ollama(model='mistral', base_url="http://localhost:11434")
service_context = ServiceContext.from_defaults(llm=llm, embed_model="local:BAAI/bge-small-en")
graph_store = NebulaGraphStore(space_name="wikipedia", edge_types=["relationship"], rel_prop_names=["relationship"], tags=["entity"])
storage_context = StorageContext.from_defaults(graph_store=graph_store)
kg_index = KnowledgeGraphIndex(index_struct=KG(index_id="vector"), service_context=service_context, storage_context=storage_context)
graph_rag_retriever = KGTableRetriever(index=kg_index, retriever_mode="keyword")
kg_rag_query_engine = RetrieverQueryEngine.from_args(retriever=graph_rag_retriever, service_context=service_context)
response_graph_rag = kg_rag_query_engine.query("Tell me about Peter Quill.")
display(Markdown(f"<b>{response_graph_rag}</b>"))`
这段代码假设你已经在 Ollama 上部署了 mistral 模型,并在本地运行了一个 nebula 实例。此外,它还假设 NebulaGraph 中已加载了一个知识图谱。如果你没有知识图谱的话,在下一节中我们将介绍如何构建一个知识图谱。
这里,你可以使用 Docker 桌面的 NebulaGraph Extension 来快速启动一个 nebula 实例。
首次启动(v3.6.0)版本之前,你可能需要添加下 storage 的信息:
`ADD HOSTS "storaged0":9779,"storaged1":9779,"storaged2":9779`
在使用 NebulaGraph 进行查询之前,你可能需要创建相关索引
`创建图空间
CREATE SPACE wikipedia(vid_type=FIXED_STRING(256), partition_num=1, replica_factor=1);
使用图空间
USE wikipedia;
创建实体
CREATE TAG entity(name string);
创建关系边
CREATE EDGE relationship(relationship string);
创建实体类型对应的索引
CREATE TAG INDEX entity_index ON entity(name(256));`
知识图谱的搭建
构建一个知识图谱
在进行推理之前,你需要在向量数据库或图数据库中对数据进行索引构建。
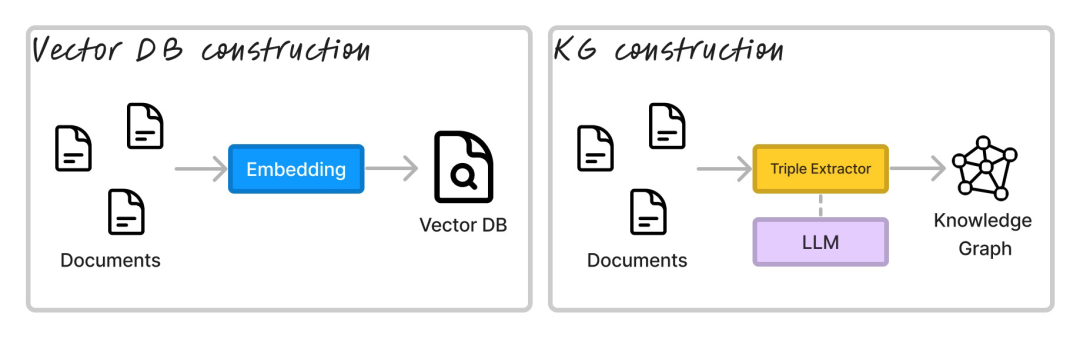
图注:Indexing architectures for RAG
对于 Graph RAG 来说,与 Vector RAG 的文档分块、嵌入等操作对等的是,提取三元组。三元组的形式一般是(s, p, o),其中 s 是主体,p 是谓词,o 是客体。主体和客体是实体,谓词是关系。
从文本中提取三元组有多种方式,但最常见的方法是使用命名实体识别器(NER)和关系提取器(RE)的组合。NER 提取像“Peter Quill”和“银河护卫队第 3 卷”这样的实体,RE 提取像“在…中扮演角色”和“由…导演”这样的关系。
虽然市面上有专门用于 RE 的微调模型,比如:REBEL,但人们开始使用 LLM 来提取三元组了。下面是 LlamaIndex 的 RE 默认提示词:
`Some text is provided below. Given the text, extract up to
{max_knowledge_triplets}
knowledge triplets in the form of (subject, predicate, object). Avoid stopwords.
---------------------
Example:
Text: Alice is Bob's mother.
Triplets: (Alice, is mother of, Bob)
Text: Philz is a coffee shop founded in Berkeley in 1982.
Triplets:
(Philz, is, coffee shop)
(Philz, founded in, Berkeley)
(Philz, founded in, 1982)
---------------------
Text: {text}
Triplets:
`
使用这种方法的问题在于,你必须用正则表达式解析聊天输出,而且你还无法控制提取的实体或关系的质量。
LlamaIndex 中的知识图谱
但是,有了 LlamaIndex,用以下的代码片段,10 行 Python 代码就完成了一个知识图谱的构建工作:
`from llama_index.llms import Ollama
from llama_index import ServiceContext, KnowledgeGraphIndex
from llama_index.graph_stores import NebulaGraphStore
from llama_index.storage.storage_context import StorageContext
from llama_index import download_loader
llm = Ollama(model='mistral', base_url="http://localhost:11434")
service_context = ServiceContext.from_defaults(llm=llm, embed_model="local:BAAI/bge-small-en")
graph_store = NebulaGraphStore(space_name="wikipedia", edge_types=["relationship"], rel_prop_names=["relationship"], tags=["entity"])
storage_context = StorageContext.from_defaults(graph_store=graph_store)
loader = download_loader("WikipediaReader")()
documents = loader.load_data(pages=['Guardians of the Galaxy Vol. 3'], auto_suggest=False)
kg_index = KnowledgeGraphIndex.from_documents(
documents,
storage_context=storage_context,
service_context=service_context,
max_triplets_per_chunk=5,
include_embeddings=True,
kg_triplet_extract_fn=None,
kg_triple_extract_template=None,
space_name="wikipedia",
edge_types=["relationship"],
rel_prop_names=["relationship"],
tags=["entity"],
)`
基于 LLM 构建知识图谱的失败示例
如果我们查看电影“银河护卫队第 3 卷”所生成的知识图谱,我们可能会发现一些问题: 这里有个问题的汇总表:

图注:问题汇总表格
将它同与手工标记的 Wikidata 图谱对比是这样的:
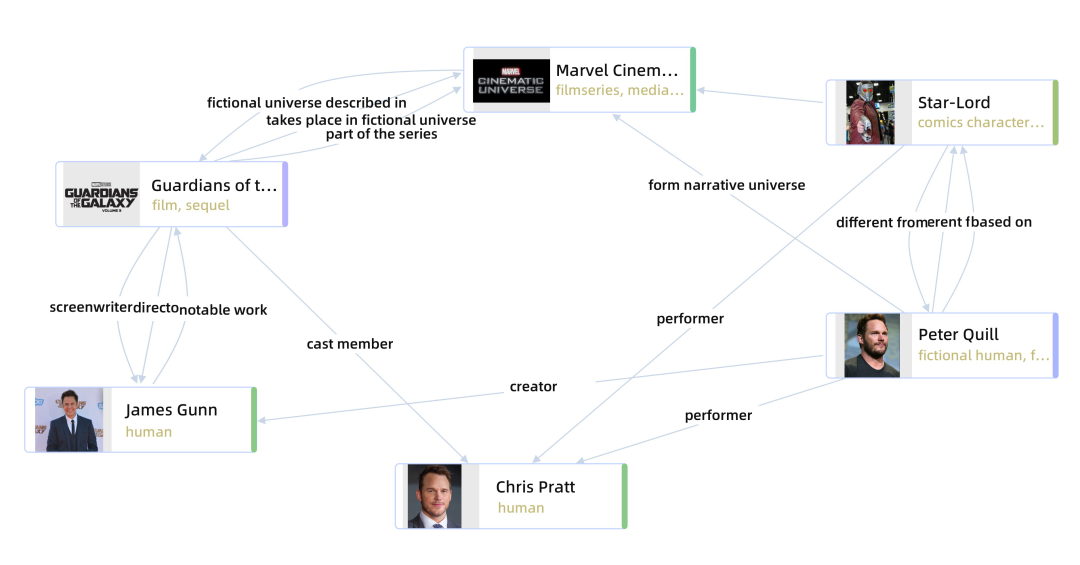
图注:Human-labelled KG in Wikidata generated with metaphacts
为了更好地构建知识图谱
所以,我们的前进方向在哪里呢?本质上,知识图谱的构建优化要自然演进的话,其实目前有一些技术挑战需要解决:构建知识图谱的方法需要新的事实和表示未见过的知识。论文《统一大语言模型和知识图谱:路线图(Unifying Large Language Models and Knowledge Graphs: A Roadmap)》 很好地概述了当前的技术现状以及未来的挑战。
构建知识图谱涉及在特定领域内创建知识的结构化表示,包括识别实体及其之间的关系。知识图谱构建过程通常包括多个阶段,包括:1) 实体发现;2) 共指消解;3) 关系提取。论文的 Fig.19 展示了在知识图谱构建的每个阶段应用大型语言模型(LLM)的一般框架。最近,还探索了 4) 端到端的知识图谱构建,涉及一步构建完整的知识图谱,或者直接从大型语言模型(LLM)中提炼知识图谱。
这篇论文可以用下图总结下:
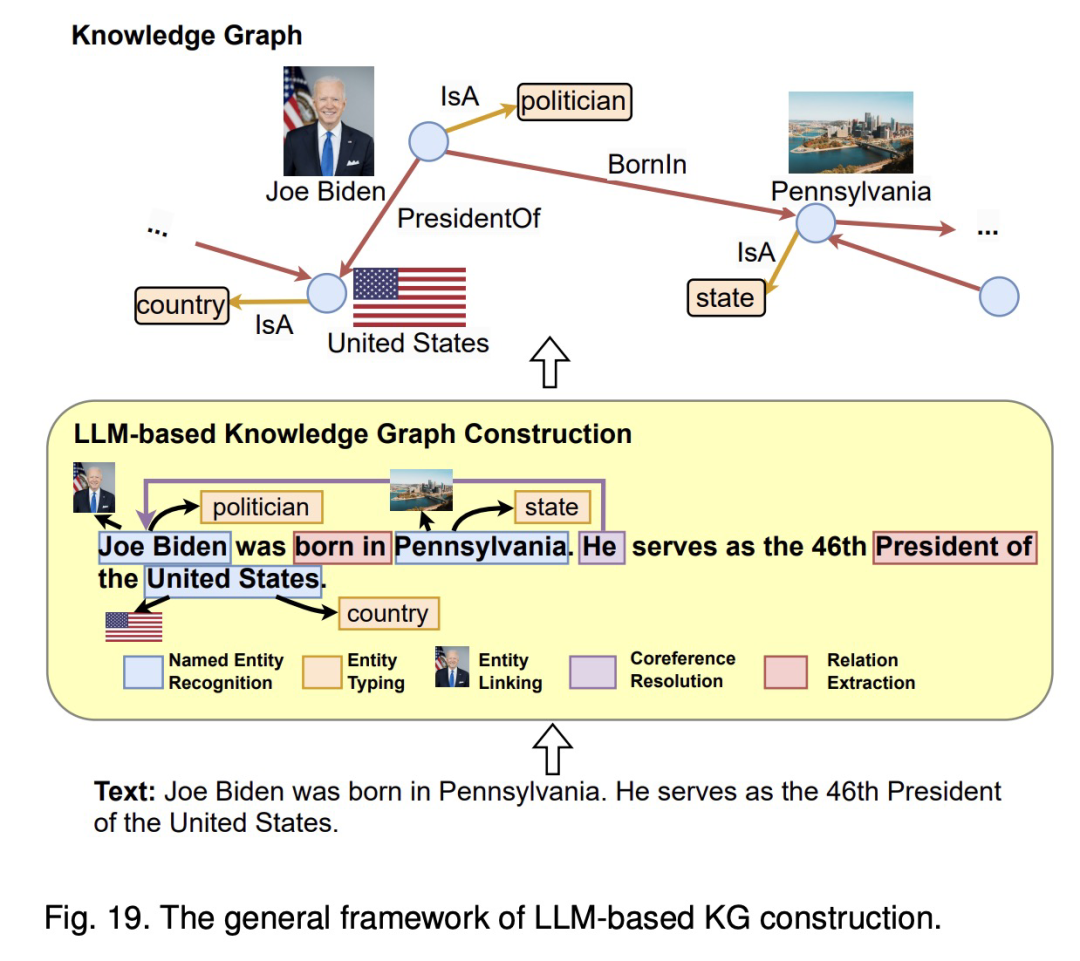
图注:Fig.19 The general framework of LLM-based KG construction
我只看到过少数几个尝试解决上述问题的项目:DerwenAI/textgraphs 和 IBM/zshot.。
解锁 AI 专业技能
Human vs AI
图谱和 LLM 相遇的尽头是人机合作。谁不喜欢“人类与 AI”的故事呢?毕竟,现在关于“AGI”或是“ChatGPT 通过资格考试”的新闻遍地都是。
图注:Human vs AI
我建议阅读本文的你读一读 AI Snake Oil 报道中的这个回答。他们提出了一个好观点,即:像 ChatGPT 这样的模型只是记住了解决方案而不是推理它们,这让考试成为比较人类和机器的一个糟糕方式。
超越存储记忆,还有一个围绕所谓的泛化、推理、计划、表示学习的研究领域,图能帮上忙。
人机合作:可视化
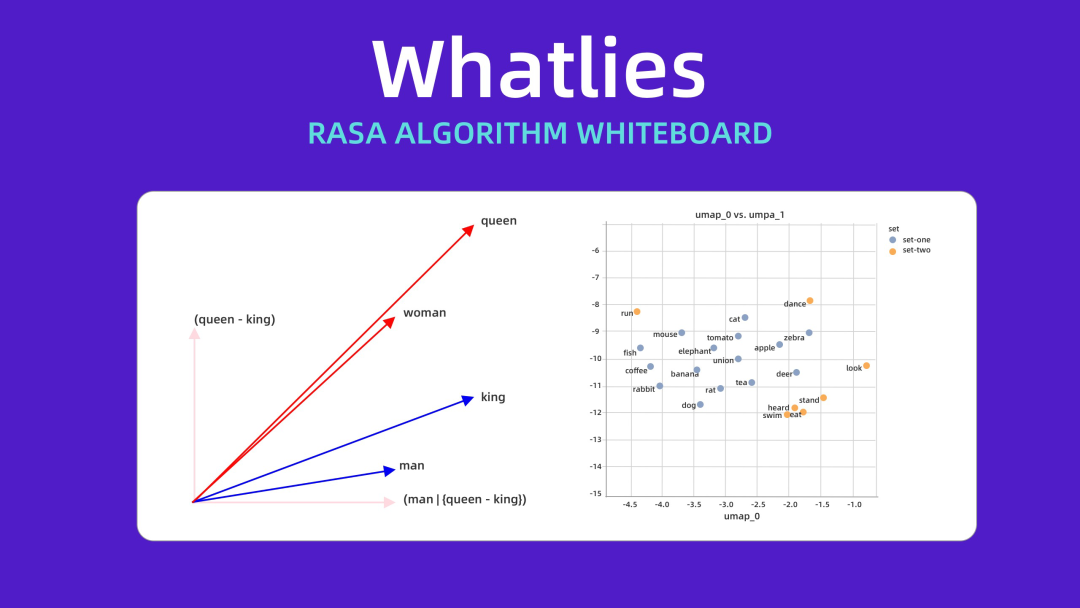
人机的关系,我更认同人机合作的观点,而不是彼此对抗。这就要求人类得知道,如何解释和优化那些内部工作机制不透明的机器学习模型。
一个关键项目推动了这块的发展,那就是 Vincent Warmerdam 在 2020 年发表的 whatlies 论文。他用 UMAP 对嵌入进行了可视化,来揭示 LLM 中的质量问题,并建立了一个框架,供其他人审计他们的嵌入,而不是盲目信任它们。
同样,图数据库提供了许多开箱即用的可视化工具。例如,它们会通过颜色、元数据和不同的布局算法(基于力导向图)添加上下文。
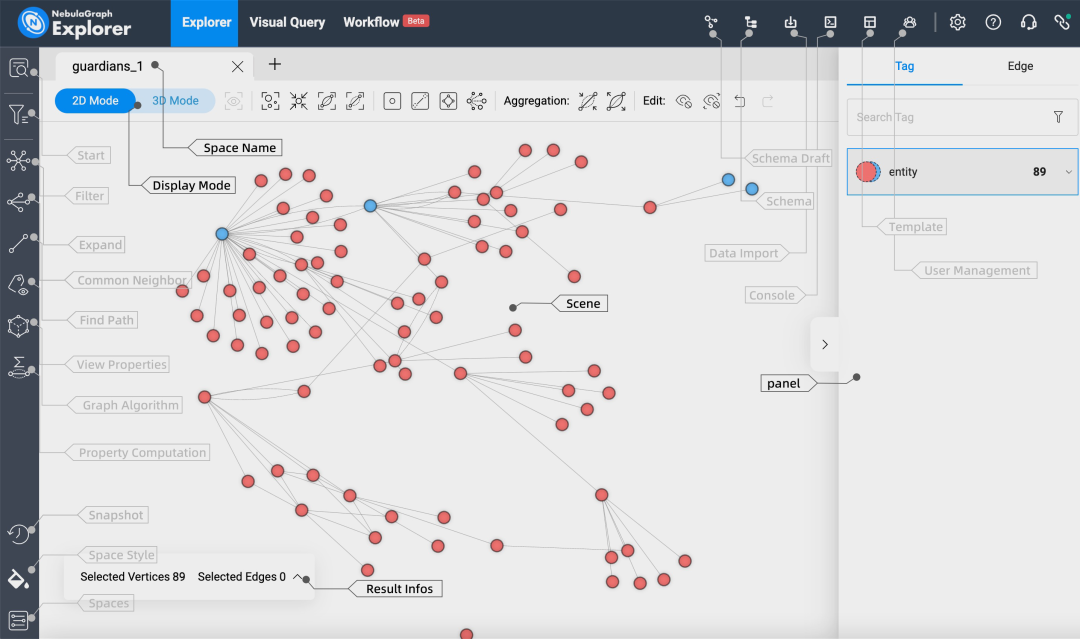
人机合作:Human in the Loop
最后一件事,我们如何解决深度学习模型缺乏控制的问题,以及我们如何将领域专家的声明性知识结合起来?
我喜欢引用“真理在于实践”的说法,我的意思是,技术的价值必须基于其在生产中的结果来判断。当我们观察生产系统时,我们看到 LLM 或深度学习模型不是孤立使用的,而是与人类一起共同进步的。
在两周前的一个项目和论文中,谷歌开始使用语言模型来帮助它在 C/C++、Java 和 Go 代码中找到和发现错误。更让人兴奋的是,Google 最近开始使用基于 Gemini 模型的 LLM 来“成功修复单元测试期间发现的 15% 的sanitiser bug,修补了数百个问题”。尽管 15% 的接受率听起来相对较小,但在谷歌这个规模上却有很大的影响。这个错误修复的处理流程、结果优于人类——谷歌说道:“大约 95% 的代码提交被代码所有者在没有讨论的情况下就接受了。这是一个比人类生成的代码变更更高的接受率,后者通常会引发问题和评论”。
对我来说,关键的收获与他们的架构有关:

图注:AI-powered patching at Google
他们用 LLM 构建了它,但他们还将 LLM 与更小的、更具体的 AI 模型结合起来,更重要的是在顶层加上了双重人类过滤器,从而与机器协同工作。
小结
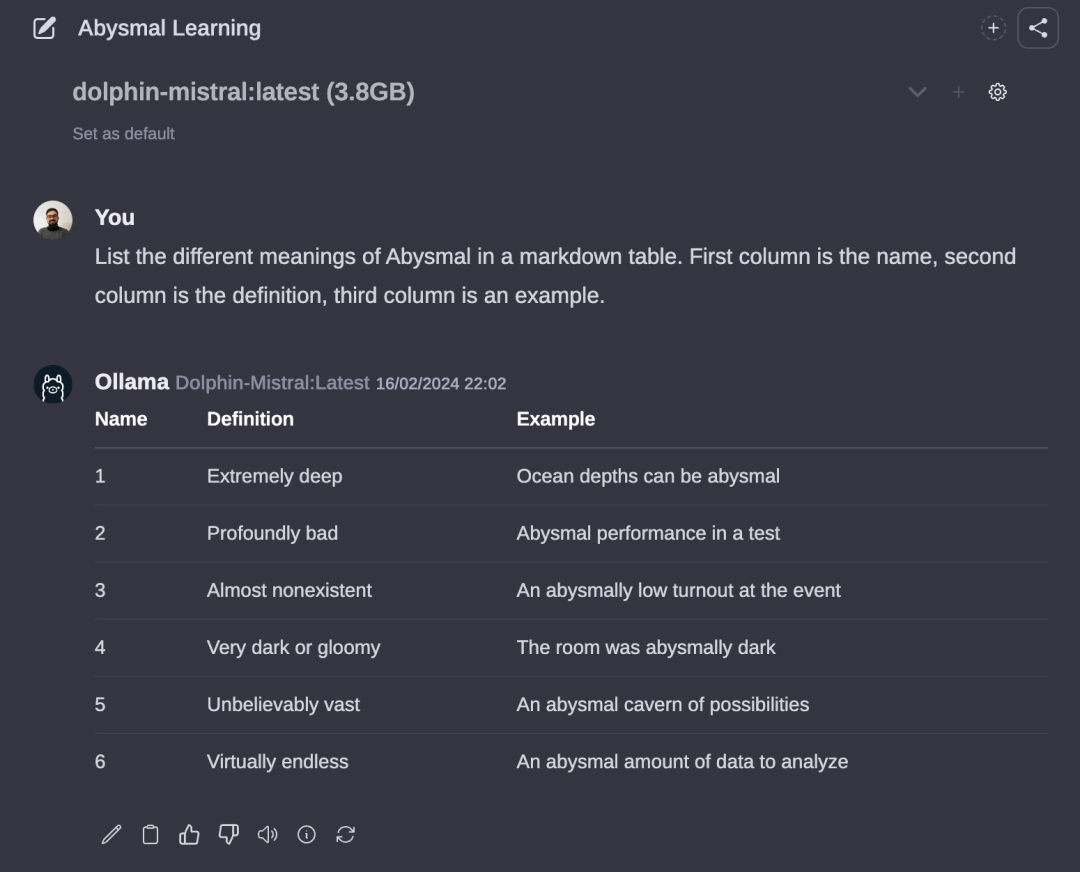
我还清晰地记得 2019 年那些日子,从 LSTM 转向 Transformers,我们认为那就是深度学习。现在,有了 LLM,我们达到了我所描述的 Abysmal Learning(深渊学习)。我喜欢 Abysmal Learning,因为它既可以意味着“极其深远”,也可以意味着“极其糟糕”。
比以往任何时候都更需要更多的控制、更多的透明度,以及人类与机器合作的方式。在这篇博客文章中,我们看到了一些图谱和 LLMs 可以如何合作来帮助实现这一目标的方式,我很兴奋地期待着未来会带来什么。
参考资料
Language, Graphs, and AI in industry - Paco Nathan - Jan, 2024
Graph ML meets Language Models - Paco Nathan - Oct 25, 2023
[2306.08302] Unifying Large Language Models and Knowledge Graphs: A Roadmap
GitHub - RManLuo/Awesome-LLM-KG: Awesome papers about unifying LLMs and KGs - Jun 14, 2023
Evaluating LLMs is a minefield
GPT-4 and professional benchmarks: the wrong answer to the wrong question - AI Snake Oil - Oct 4, 2023
AI-powered patching: the future of automated vulnerability fixes - Google Security - Jan 31, 2024
Graph & Geometric ML in 2024: Where We Are and What’s Next (Part II — Applications) | by Michael Galkin - Jan 16, 2024
[2312.02783] Large Language Models on Graphs: A Comprehensive Survey - Dec 5, 2023
ULTRA: Foundation Models for Knowledge Graph Reasoning | by Michael Galkin | Towards Data Science - Nov 3, 2023
Fine Tuning Is For Form, Not Facts | Anyscale - July 5, 2023
GenAI Stack Walkthrough: Behind the Scenes With Neo4j, LangChain, and Ollama in Docker - Oct 05, 2023
NebulaGraph Launches Industry-First Graph RAG: Retrieval-Augmented Generation with LLM Based on Knowledge Graphs - Sep 6, 2023
RAG Using Unstructured Data & Role of Knowledge Graphs | Kùzu - Jan 15, 2024
Constructing knowledge graphs from text using OpenAI functions | by Tomaz Bratanic - Oct 20, 2023
Knowledge graph from unstructured text | by Noah Mayerhofer | Neo4j Developer Blog - Sep 21, 2023
关于 NebulaGraph
NebulaGraph 是一款开源的分布式图数据库,自 2019 年开源以来,先后被美团、京东、360 数科、快手、众安金融等多家企业采用,应用在智能推荐、金融风控、数据治理、知识图谱等等应用场景。GitHub 地址:https://github.com/vesoft-inc/nebula



