
技术分享
NebulaGraph 与 Neo4j 选型对比
交流图数据库技术?加入 Nebula 交流群请先填写下「你的 Nebula 名片」,Nebula 小助手会拉你进群~~
关于作者:兰后,平安壹账通,数据产品经理。6 年金融行业咨询工作经验,具备大数据分析挖掘、 数据中台、数据治理等方面专业知识。负责为金融行业客户提供以 AI 产品和数据中台为核心的解决方案和咨询服务,协助客户开展数字化转型规划和设计工作。
两年前,为了给数据资产管理平台构建数据血缘功能,我被前老板“扔”去研究图数据库,熬了几个大夜写完调研报告,以为这事就这么过去了。
没想到,命运的齿轮再次转动。最近在为一家保险巨头做数字化转型时,客户冷不丁地问我:“能不能用图数据库搞点创新,让我们在集团内部的科技比赛里拿个奖?”
于是,我重新翻出这份“压箱底的宝藏”……
一、选型调研
(一)粗筛
结合数据库选型经验,我们先从 DB-Engines 排名中分别筛选出国内外排名第一的 NebulaGraph 和 Neo4j.
(二)细筛
我们从优缺点、使用成本、是否适配信创、性能等方面,对 Neo4j、NebulaGraph 进行进一步选型调研。
综合考虑信创和保险同业案例等方面,建议优先选择 NebulaGraph.
| 维度 | Neo4j | NebulaGraph |
|---|---|---|
| 优缺点 | 1. 优点:成熟的图数据库,功能全面,Cypher 语法友好,生态丰富(Bloom 算法库); 2. 缺点:社区版仅支持单机,企业版扩展受限,写性能依赖主节点,开源受限 | 1. 优点:分布式架构,水平扩展,支持万亿边,性能强劲(导入/查询均为业界领先),对大数据生态兼容; 2. 缺点:生态相对年轻,上手难度略高,高级功能需企业版 |
| 是否开源 | 部分开源:社区版 GPL v3 开源,企业版闭源需商业授权 | 完全开源:源码全开源,企业版增强功能收费 |
| 信创兼容 | 不兼容,无国产平台官方认证,主要支持 x86 Linux 环境 | 已通过华为鲲鹏、飞腾、海光、兆芯等国产 CPU 和操作系统兼容认证,全面支持信创,可自行编译安装包,以确保符合特定的软硬件环境,实现最佳性能 |
| 保险行业案例 | 1. 国外保险公司构建理赔知识图谱检测欺诈; 2. 国内案例较少 | 1.众安保险:风控反欺诈(手机号异常热点检测) 2.泰康在线:构建客户关系图用于精准推荐。支持理赔反欺诈、客户画像、裂变营销 (主要参考了两大保险行业案例,更多用户案例请查看本文文末链接) |
| 权威性能测评 | 1. 在 LDBC SNB 基准测试中表现优异 2. 小规模图查询较优 | 1. 在 10 亿边测试中,单跳查询2ms(Neo4j 需数十秒);多跳查询延迟低于 5 秒(Neo4j 数百秒) 2. 导入性能和扩展性均优于 Neo4j |
| 适用场景 | 1. 深度图分析:Cypher 语言对复杂路径表达更简洁 2. 开发测试场景:社区版免费且生态成熟 3. 事务一致性要求极高:如金融交易反欺诈 | 1. 需支持 10 亿+ 级节点规模:如全国级供应链网络 2. 信创改造强需求:国产芯片/0S全栈认证 3. 高并发实时查询:如 IoT 设备状态追踪 |
1. 架构与扩展能力
| 维度 | Neo4j | NebulaGraph |
|---|---|---|
| 架构类型 | 单机/因果集群(企业版支持水平扩展) | 分布式存储计算分离架构(支持 10 亿+ 节点) |
| 扩展能力 | 垂直扩展为主,企业版支持读写分离集群 | 水平扩展(存储/计算节点独立扩容) |
| 信创适配 | 需手动验证 JDK/0S 兼容性(如达梦适配) | 完成鲲鹏/麒麟/统信全栈兼容认证 |
2. 数据模型与查询能力
| 维度 | Neo4j | NebulaGraph |
|---|---|---|
| 核心模型 | 原生属性图,Schema 可选 | 属性图模型,支持多跳索引与动态 Schema |
| 查询语言 | Cypher,专为图设计,复杂路径表达更灵活 | nGQL,类 SQL 语法,支持图遍历 + SQL 混合查询 |
| 事务支持 | 单机强一致,企业版支持分布式事务 | 支持 ACID,Raft 协议保障分布式事务 |
3. 大数据生态集成
| 维度 | Neo4j | NebulaGraph |
|---|---|---|
| Hive对接 | 需通过 ETL 工具(如Apache NiFi)同步数据 | 提供 Spark Connector 实现 Hive 联邦查询 |
| 实时计算 | Spark Connector 需额外转换图结构 | 原生集成 Flink CDC,支持毫秒级数据同步 |
| 数据质量 | 依赖外部工具实现 ETL 质量校验 | 支持 Schema 约束与数据版本控制 |
4. 性能与适用场景
| 维度 | Neo4j | NebulaGraph |
|---|---|---|
| 写入性能 | 单机批量导入优化(约10kTPS) | 分布式批量导入(TPS 可达 100k+) |
| 查询场景 | 深度递归查询(如社交传播链挖掘) | 高并发多跳查询(如供应链 5 层路径分析) |
| 适用场景 | 实时推荐系统、知识图谱构建 | 金融风控、工业物联网、国产化替代 |
5. 成本与运维
| 维度 | Neo4j | NebulaGraph |
|---|---|---|
| 授权费用 | 社区版免费,生产环境需商业授权 | Apache 2.0开源协议(无商业授权限制) |
| 运维寒杂度 | 单机部詈简单,集群需专业DBA支持 | 依赖Kubernetes管理分布式集群 |
| 国产化成本 | - | 预置信创适配清单(含JDK/0S兼容脚本) |
二、产品简介
(一)Neo4j(3.4 版本)
Neo4j 是由 Neo4j Inc. 开发的原生图数据库,基于 Java 实现,采用事务型存储引擎和图数据模型。社区版仅支持单机部署,企业版支持多节点集群(需多数节点参与写入)。
1. 架构
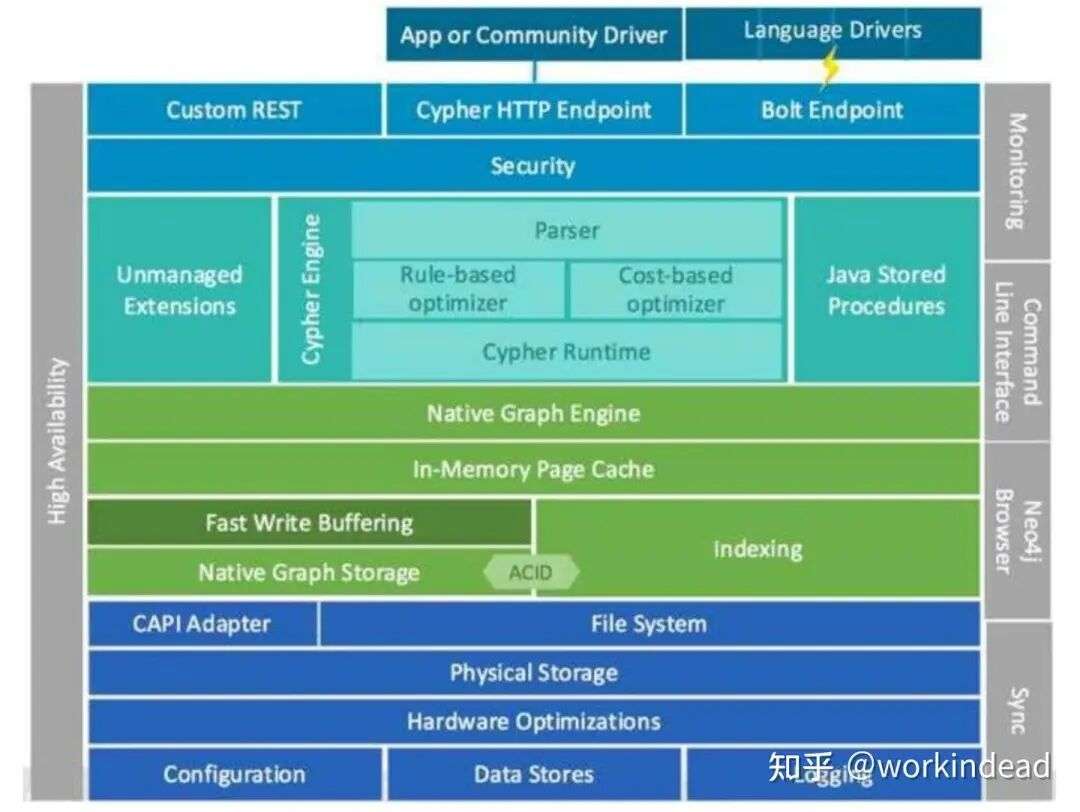
2. 原生图存储引擎
基于节点-关系连接,支持无索引邻接访问(index-free adjacency),极大提高图遍历性能。
3. 产品特性
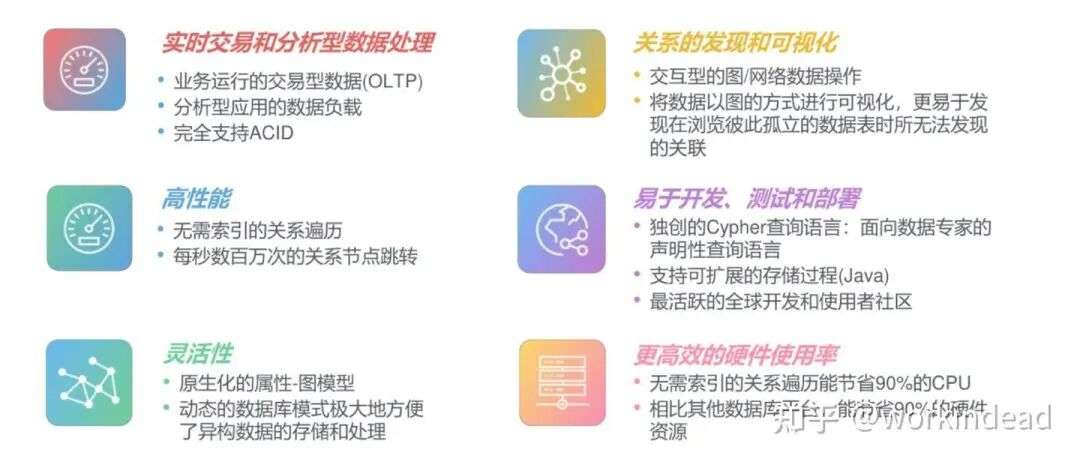
4. 数据模型
原生图数据库,采用属性图模型(Property Graph),节点(Node)、关系(Relationship)、属性(Property)构成核心元素。
5. 查询语言
使用 Cypher,语法简洁、强语义,有 OpenCypher 项目支持。
可视化与工具链。
提供 Neo4j Bloom 可视化工具、Graph Data Science 库、Neo4j Aura 云服务支持等。
(二)、NebulaGraph(通用)
NebulaGraph 是在 2019 年推出的图数据库产品,底层数据模型是属性图,基于C++ 语言编写。采用 Apache 2.0 开源授权,强调性能、横向扩展与国产兼容特性。
1. 架构
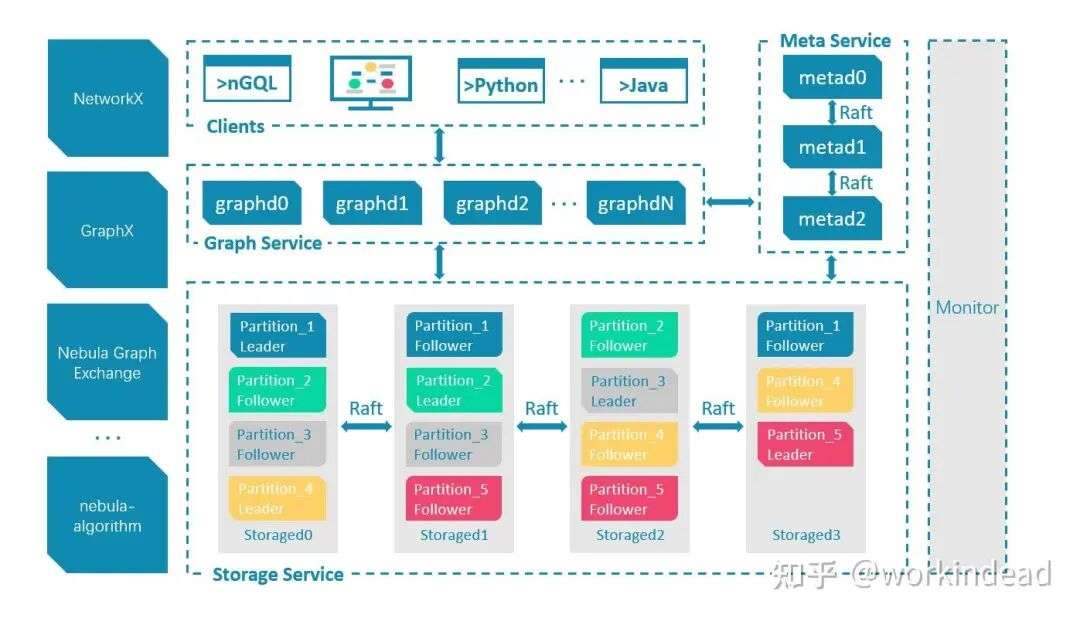
采用存储计算分离的设计,包括三个核心组件:
Meta Service:管理集群元数据和 schema 等。
Storage Service:有状态节点负责持久存储,支持 RocksDB,使用 Raft 共识确保一致性。
Graph (Query) Service:无状态节点处理查询请求,支持水平扩展。
2. 产品特性
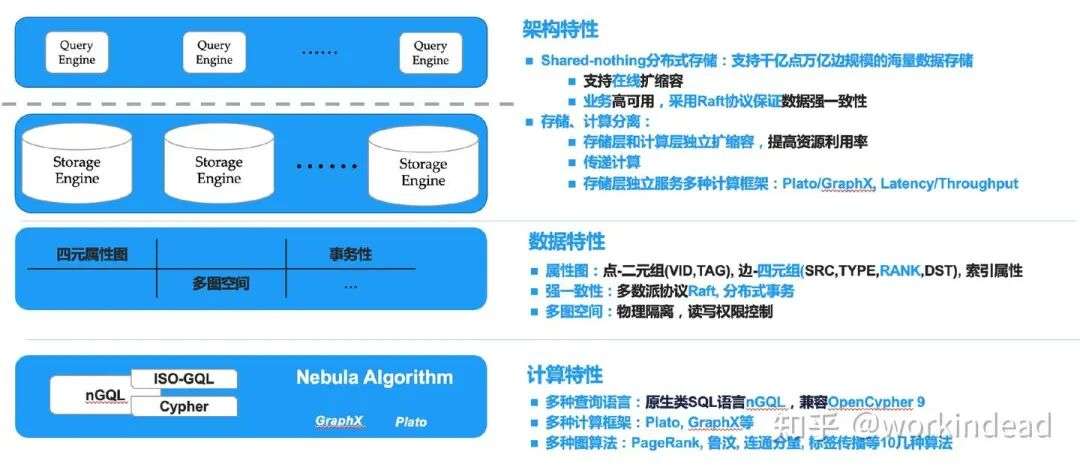
数据模型:采用属性图模型(Property Graph),兼容图计算和图存储分离。
查询语言:使用 nGQL,类 SQL/Cypher 结构,并部分兼容 OpenCypher,方便 Neo4j 用户迁移。
生态系统:集成 Nebula Dashboard(可视化管理)、Nebula Studio(交互查询)、Nebula Algorithm(图算法库)。
参考资料
1、DB-Engines 图数据库排名
2、Neo4j 官方使用文档
3、NebulaGraph 官方使用文档
4、LDBC-SNB 数据集:关联数据基准委员会提供的评测数据集,包含 26 亿顶点、177 亿关系
5、NebulaGraph 同花顺选型测评
相关阅读
交流图数据库技术?加入 Nebula 交流群请先填写下「你的 Nebula 名片」,Nebula 小助手会拉你进群~~




