
社区动态
VLDB 2024|NebulaGraph RAG 正式官宣
导读:VLDB (International Conference on Very Large Data Bases)是数据库领域的三大顶级国际会议之一,自1975年创办以来,一直引领着数据库领域的前沿研究与技术创新,被誉为数据库领域的风向标。NebulaGraph GenAI Team 负责人古思为在 VLDB 上进行了主题为《GraphRAG in NebulaGraph 》的演讲。
一、背景
NebulaGraph 专注于图技术,已进行了多年的开源分布式图数据库的研发。在 RAG 技术还未被称为 RAG,而是上下文学习方法的时候,我们就意识到以图的方式处理知识会对解决这些问题有很大帮助。因此,NebulaGraph 率先提出了 GraphRAG 的方法,并于 2023 年 8 月与 LlamaIndex 联合发布 GraphRAG。
 自此,古思为带领 NebulaGraph GenAI Team 一直致力于 GraphRAG 在 NebulaGraph 中的建设与落地。在 VLDB 2024 上,企业版「悦数 RAG」首次亮相。
自此,古思为带领 NebulaGraph GenAI Team 一直致力于 GraphRAG 在 NebulaGraph 中的建设与落地。在 VLDB 2024 上,企业版「悦数 RAG」首次亮相。
二、为什么需要 GraphRAG
RAG 通常涉及将知识库中的信息进行向量化处理,以便在查询时能够快速检索到最相关的信息块。这种方法使得模型能够处理那些它原本未曾训练过的问题,从而大大扩展了模型的应用范围。这种常见的机器学习方法,通常称为“分割与嵌入”方法。虽其处理语义匹配方面很有效,但它仍然面临许多挑战。其中一个主要的问题被比喻为“大海捞针”,即在庞大的数据中寻找特定信息的困难。
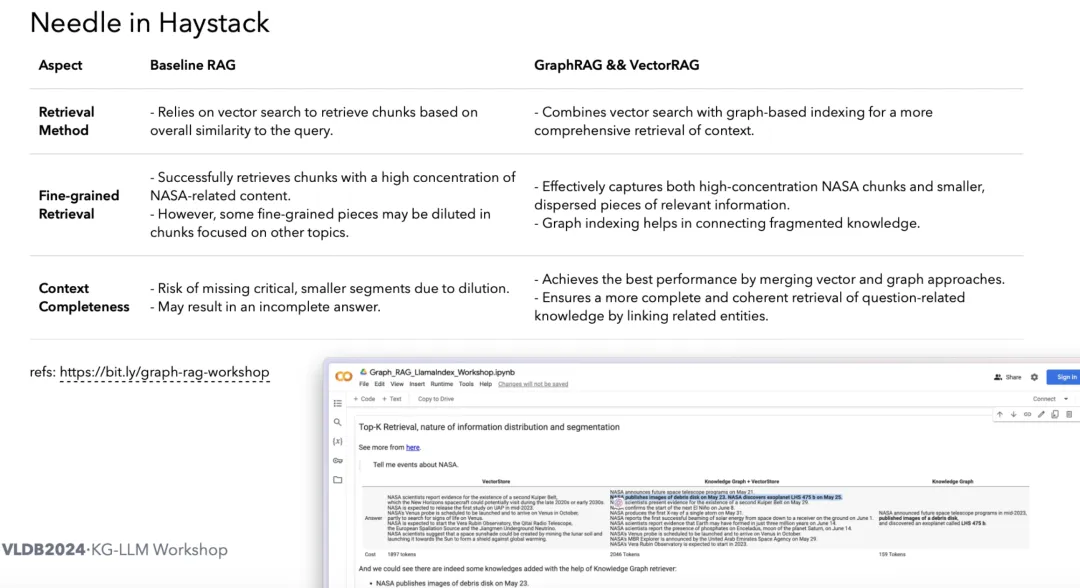
除了“大海捞针”的问题之外,另一个挑战源自于嵌入模型本身的局限性。通常,在构建这种系统时,我们往往没有资源去定制一个专门的模型,因此大多数情况下只能依赖通用的预训练模型。然而,这些模型在处理一些复杂的领域知识时,可能会出现无法准确表达语义的问题。
当图技术与 RAG 结合后,能够有效帮助解决我们在使用嵌入模型时遇到的难题。
图技术可以对数据进行更精细的分割,同时保持全局的上下文信息。例如,将一本书的每一章节中的重要知识点放入图中,保留知识点之间的关联关系。相比于传统的线性切割,这种方法能够更好地维护知识结构。

在使用向量检索时,模型依赖的上下文关联通常是概率性的,这种关联体现在语义理解模型中,但这些模型往往比较简单,智能化程度有限,可控性较低。而通过构建图谱,我们能够建立更确定且高质量的连接,大大减少了因嵌入模型引起的误差。此外,图谱还可以轻松构建全局上下文,从而进一步提升检索精度。
三、GraphRAG in NebulaGraph
(一)探索开发
我们推出 GraphRAG 后,GenAI Team 构建了开箱即用的 GenAI Suite,使 GraphRAG 更易用,且性能更强大。
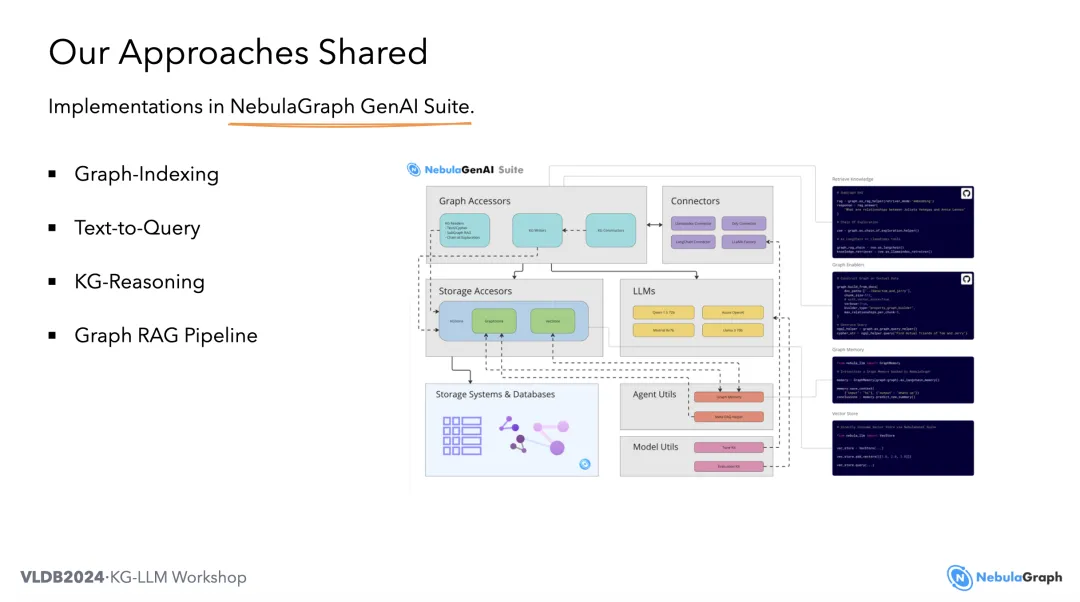
(二)最新成果
GraphRAG 在 NebulaGraph 中应用的最新成果是「悦数 RAG」,这是一款极简的知识应用构建平台,使 GraphRAG 技术的强大功能触手可及。用户可以通过友好易用的对话界面轻松创建搜索引擎、聊天机器人和内容生成应用,无需任何编程操作。通过激活和循环内部知识,「悦数 RAG」能够最大限度地发挥其价值,将知识和见解转化为行动。
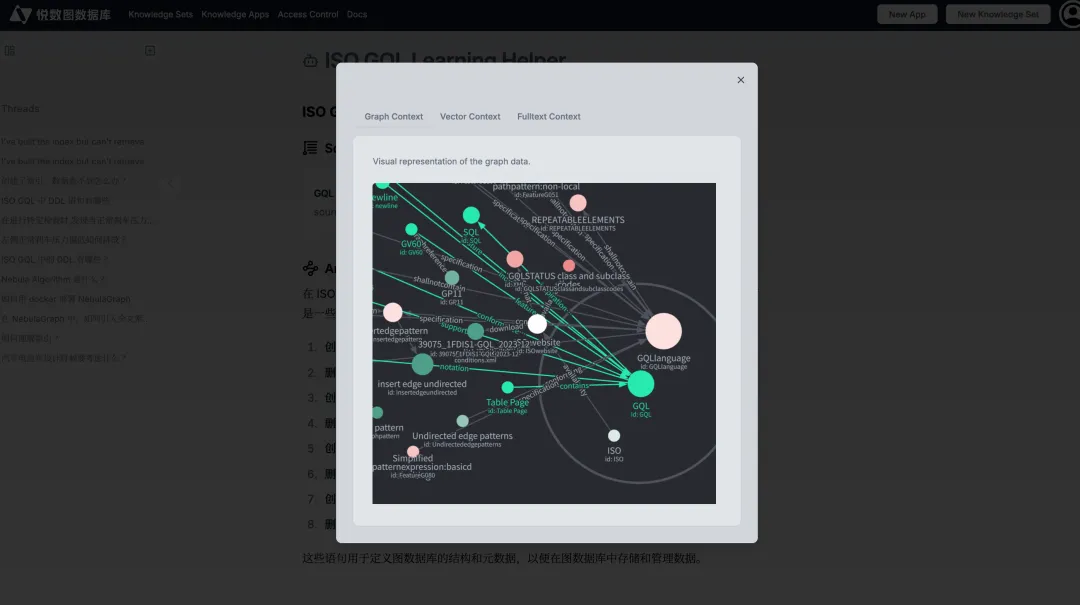 用户应用界面:Graph RAG 回答援引的 Graph 上下文
用户应用界面:Graph RAG 回答援引的 Graph 上下文
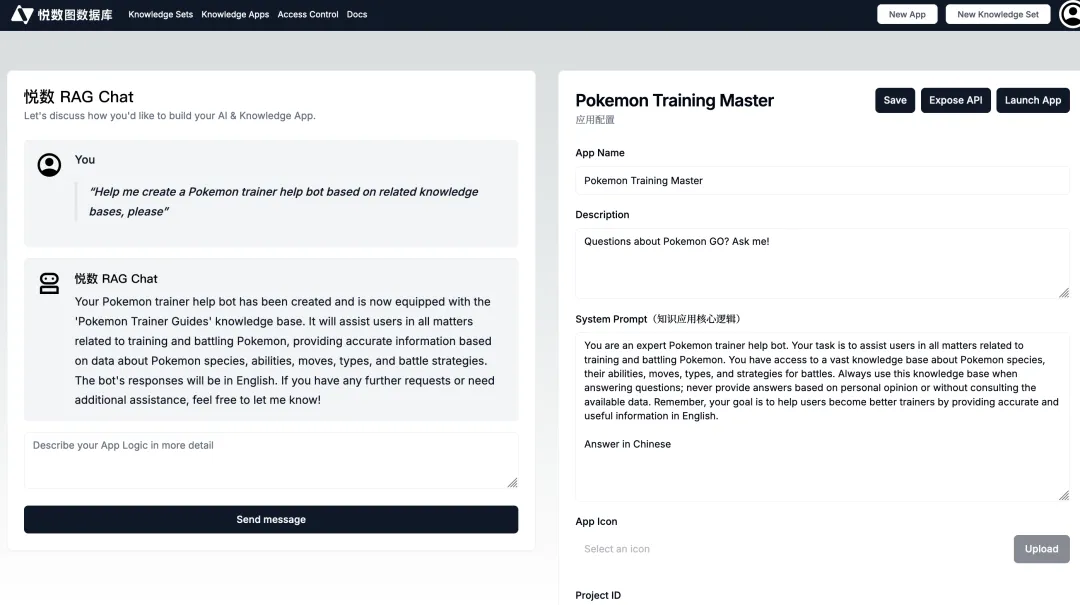 应用构建界面:通过自然语言设置、维护和优化应用
应用构建界面:通过自然语言设置、维护和优化应用



