技术分享行业科普
盘点 2025 年值得一读的图数据库文章~
交流图数据库技术?加入 Nebula 交流群请先填写下「你的 Nebula 名片」,Nebula 小助手会拉你进群~~
2025 年,你和 NebulaGraph 一起肝了哪些项目?有没有哪篇文章在你百思不解时,给了你灵感?
星云仔根据社区的阅读热度和专业深度,盘出了这份「2025 NebulaGraph 高光文章年鉴」。快来看看,这些过去一年被反复转发和讨论的宝藏,你错过了哪一篇?
星云仔温馨提示:点击图片,直接跳转文章原文
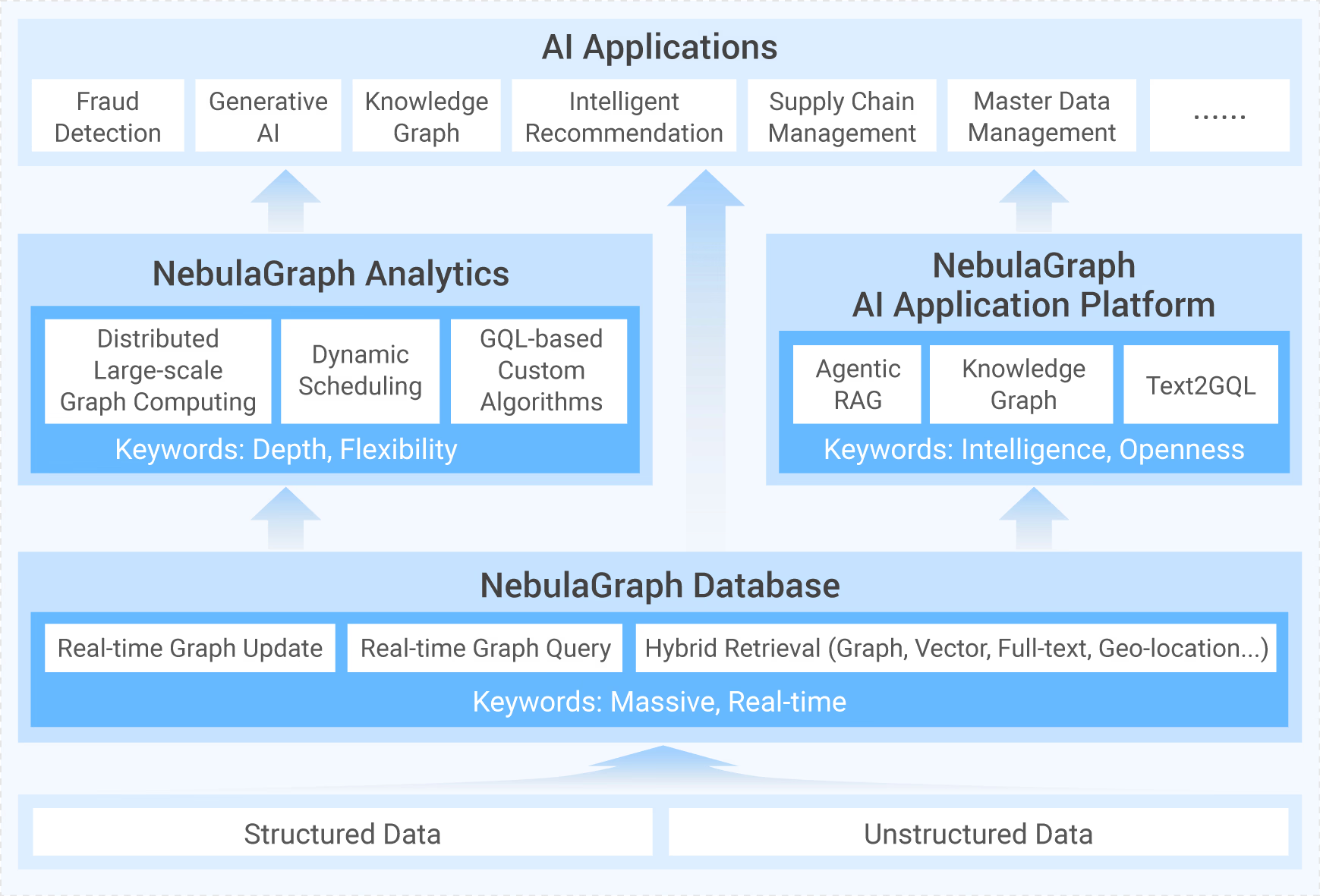
一、图数据库选型
什么场景选择图数据库是最佳解决方案?本文以客户-经理-助理的典型关系为例,揭示关系型数据库依赖外键隐式表达关系的局限,并展示以 NebulaGraph 为代表的图数据库,在复杂关系场景的显著优势,用最通俗易懂的语言让你理解:当数据关系复杂、变化频繁且需深度探索时,图数据库是不可替代的解决方案。

如何选择一款适合业务需求的图数据库?在 DB-Engines 国内外排名第一的 NebulaGraph 与 Neo4j 选型对比中,核心差异在于架构与定位。Neo4j 的 Cypher 语言成熟、生态完善,适合中小规模深度图分析。而 NebulaGraph 采用原生分布式架构,在十亿级边数据下查询性能优势显著,并全面支持信创环境,更适合需要水平扩展、高性能及国产化替代的大规模实时场景。

为何选择 NebulaGraph?作为全球数据库领域的“奥斯卡奖”,DB-Engines 排名是衡量数据库流行度的重要指标。2025 年 9 月,NebulaGraph 在 DB-Engines Graph 类别中排名第二,不仅证明了 NebulaGraph 在全球开发者社区和市场需求中的受欢迎程度,更体现了中国基础软件在国际舞台上的崛起。

二、AI+知识图谱
在 DeepSeek 问世之初,尝试将其与 NebulaGraph 结合,从零构建农业知识图谱,验证 AI 在知识结构化方面的强大能力。
首先,DeepSeek 能够从单篇文章中提取实体与关系,生成规范的 nGQL 脚本,快速构建基础图谱。其次,面对多源信息,AI 可自动融合新知识,动态扩展图谱结构,并支持属性与关系的增量更新。最后,即使仅输入主题描述,DeepSeek 也能“无中生有”生成符合逻辑的图谱框架,为冷启动场景提供可行路径。

用 DeepSeek + NebulaGraph 构建知识图谱的类似实践,还有以下两篇~
用 NebulaGraph + DeepSeek 解锁元宵节文化知识图谱,你知道几个?
NebulaGraph + DeepSeek 轻松看懂《哪吒2》人物关系
三、GraphRAG
在高级 RAG 技术演进中,由 NebulaGraph 提出并落地的 GraphRAG 成为解决传统检索框架知识稀释、关联丢失与宏观分析难题的重要路径。2025 年,NebulaGraph 进一步提出 Fusion GraphRAG 方案,系统融合文档层级、章节结构与图谱语义,在统一图存储中实现多层级、多模态的知识索引与检索。
Fusion GraphRAG 不仅支持基于元知识层的精准召回,还可通过 Chain of Exploration 在图谱中自主探索,完成从全局摘要到局部深查的复杂任务。
基于 Fusion GraphRAG,NebulaGraph 进一步推出低门槛的 AI 应用平台,支持企业以知识篮子方式组织文档,并通过对话快速构建智能应用。

针对生物医学领域知识复杂、AI 易产生幻觉的痛点,国外开发者 Diya Mandot 构建了专业的生物医学问答系统 BioGraphRAG. 该项目以 NebulaGraph 作为核心图数据库,高效存储并管理了超过千万实体、数千万关系的 BioKG 数据集,并利用多进程优化,将数据导入时间从 33 小时大幅缩短至 3 小时。

如何提升 RAG 的效果?如何把 NebulaGraph 和大模型相结合?这里有系列教程,手把手教大家从 0 到 1 搭建一款垂直领域 AI 应用。
星云实验室 part 1|用知识图谱+GraphRAG,构建垂直领域 AI 应用
星云实验室 part 2|用知识图谱+GraphRAG,构建垂直领域 AI 应用
星云实验室 part 3|构建知识问答聊天引擎与前端交互页面
四、用户案例
告警响起,面对成百上千个微服务调用,问题究竟出在哪层网络、哪个应用、哪台主机?这就是 BOSS 直聘运维团队每天要面对的挑战。
直到他们用 NebulaGraph 构建起一张实时的全景图谱,所有服务、主机、中间件都变为点和边,调用关系、性能指标一目了然。当故障再次发生时,借助 NebulaGraph 的高性能图查询与图算法,仅用 20 秒就能实现根因定位,把平均故障修复时间压缩到分钟级别,让运维团队从此告别连猜带蒙,真正实现智能运维的质变。

面对海量且复杂的业务关系,携程选择将 NebulaGraph 深度集成到其基础设施中,并巧妙构建了一套覆盖单机房、三中心与跨域多活的弹性部署策略。通过客户端的定制化改造,他们成功将跨域查询的网络损耗降低了 70%,并实现了QPS 跃升23%、平均响应稳定在毫秒级的出色表现。
这一实践不仅证明了 NebulaGraph 在千亿级超大规模场景下的强大性能,更体现了携程工程团队如何通过精细化的架构设计与调优,让图技术真正服务于核心业务。

在追求 GraphRAG 国产化落地过程中,中科数睿团队系统探索了包括 NebulaGraph、TuGraph 在内的多款国产图数据库,并历经了从微软开源方案、DB-GPT 到 KAG 等多种技术路径的迭代。基于 DeepSeek 大模型微调与诱导生成,团队最终创新性地构建了流式解析、分层存储与动态规划相结合的混合架构。该方案有效利用 NebulaGraph 处理结构化关系,并结合占位符回填机制,显著提升了专业领域问答的准确性与可解释性,为 GraphRAG 国产化落地提供了宝贵的一手经验。

五、技术科普
内存调试犹如大海捞针,尤其在复杂的 C/C++ 程序中,本文介绍的 Debug 神器 Core Analyzer 能够深入扫描堆内存,支持多种内存管理器,提供堆概览、泄漏检测、引用链追踪等一系列强大命令,极大提升内存问题排查的系统性与效率。它特别适用于并发场景下难以复现的疑难问题,是对 ASAN 等传统工具的重要补充。

NebulaGraph 存储负责人@四王,回顾了 Redis 作者与 DDIA 作者围绕 Redlock 安全性的经典辩论,深刻揭示了分布式锁在时钟漂移、进程暂停等场景下的共性问题,其本质在于实现分布式一致性共识。对分布式锁的技术讨论充分体现了 NebulaGraph 团队对分布式系统核心问题的持续关注与研究深度,也为大家理解 NebulaGraph 的分布式架构实践提供了理论参照。

六、Ending
回顾 2025,这些文章不仅记录了一场场技术的探索与实践,更映射出图数据库走向核心基础设施的清晰轨迹。无论是与 AI 的深度融合,还是在千亿级场景中的稳定性锤炼,NebulaGraph 与社区开发者共同交出了一份扎实的答卷。
感谢每一位读者的关注与阅读。技术的价值,在于被理解、被应用、被改进。希望这份年度盘点能成为你新一年探索路上的得力助手。
交流图数据库技术?加入 Nebula 交流群请先填写下「你的 Nebula 名片」,Nebula 小助手会拉你进群~~