技术分享NUC2022
开源图深度学习框架 DGL 的机遇与挑战|NUC2022
本文整理自亚马逊云AWS-资深应用科学家-王敏捷在 NebulaGraph 年度用户大会上的分享,现场视频如下——
非常高兴 NebulaGraph 邀请我给大家讲做一个分享。
先简单介绍一下,我叫王敏捷,现在是亚马逊云科技上海人工智能研究院的资深应用科学家,我们研究院成立不久,主要研究的内容其实就是图。我们知道图(Graph)其实是一个非常广阔的东西,它包含的不仅仅是数据结构本身,它包含的是一种关系,甚至于是知识这样的一种范式。
今天我想分享的主题叫做《开源图深度学习框架的机遇与挑战》,我会谈到我们研究院所主导并开发的一个开源图深度学习框架叫做 Deep Graph Library(DGL) 以及我们在开源这个领域的一些前端的研究工作。
什么是图机器学习
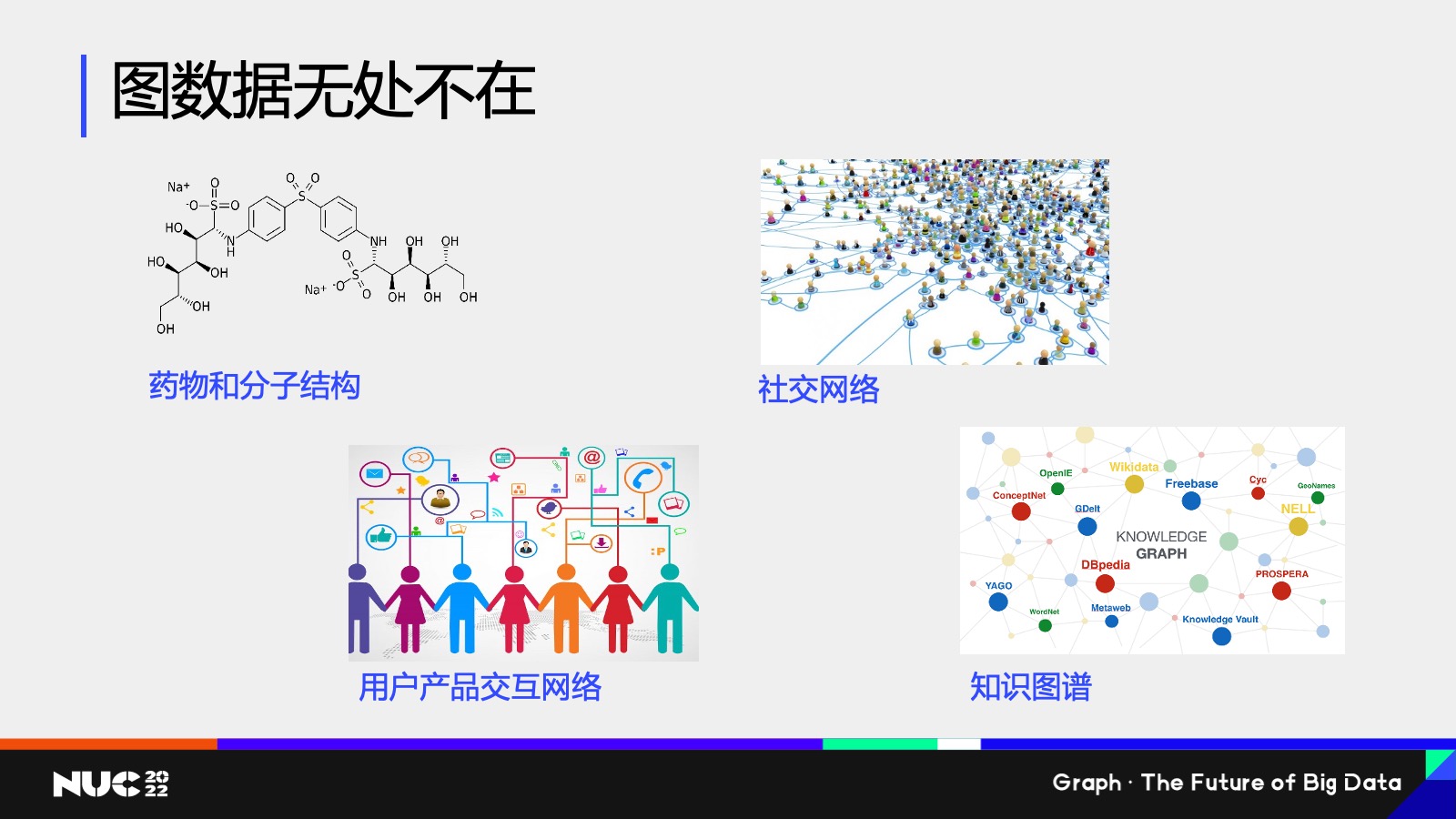
相信听过上半场很多这些 talk 的同学们或者老师们,肯定对这一点是毋庸置疑了——就是我们的图数据其实在整个生产生活当中是无处不在的,在一些比如说非常微观的层面上,我们的药物和分子结构其实可以认为是一种图的结构,然后在我们的电商等等场景当中,像社交网络产品的交互网络知识图谱等等,其实都是图的数据结构。
图机器学习任务
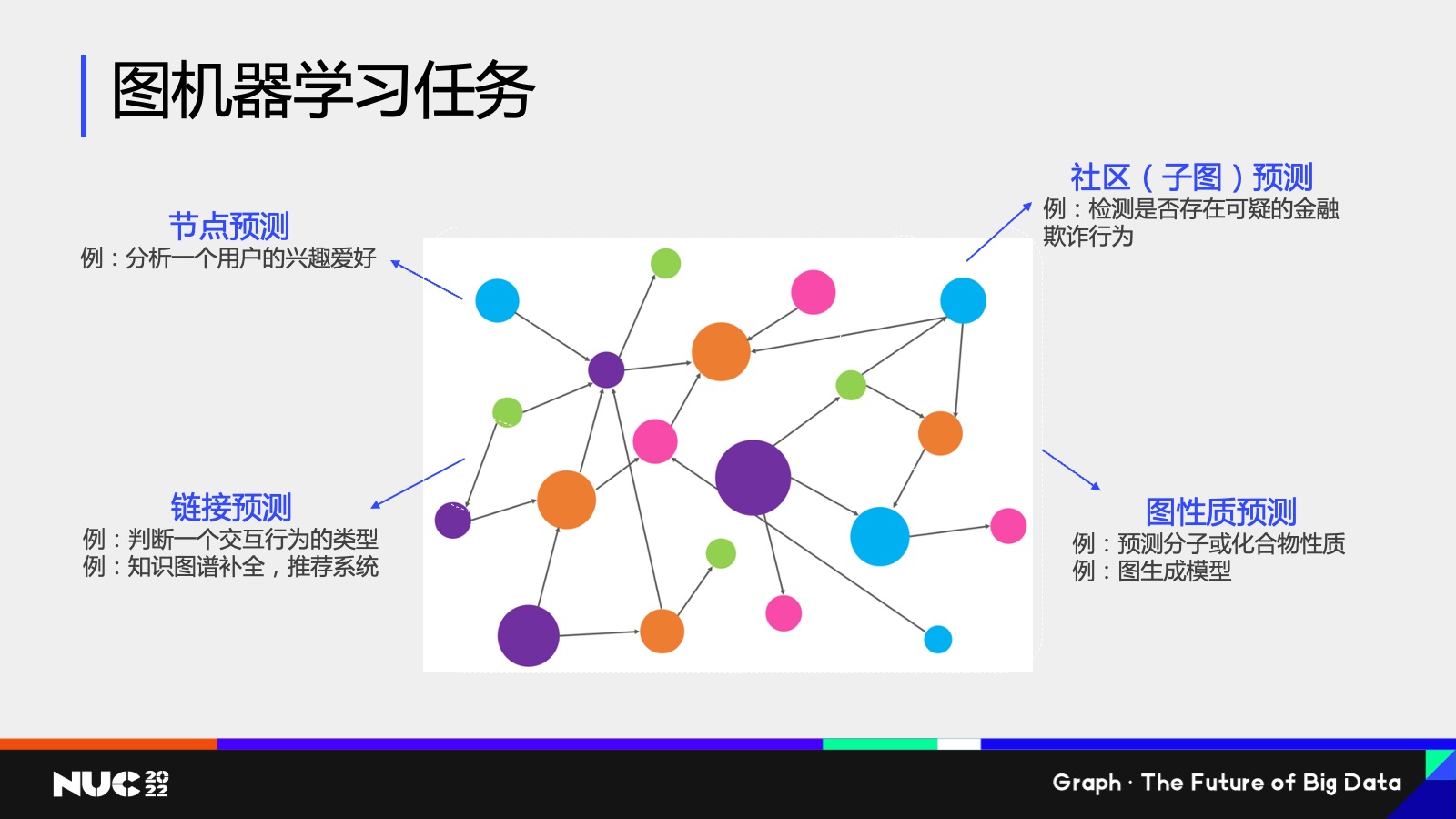
那既然图的数据结构有那么多样,而且无处不在,在图上的机器学习也会有各种各样的种类,这边我简单地抽象地概括一下,比如说我们现在有这张图,我们在这个图上其实有很多种不同的机器学习任务,比如说我可以对这个节点去做一个预测,我可以试图去分析,比如说一个用户他的兴趣爱好是什么,其实这就是在图上做节点分类的这样一个任务。
对应的我们既然有节点分类任务,也可以有链接预测的任务,比如说我现在这张图上有一条边,我去判断边的属性,其实这就是一个边预测的任务。我可以对一个已有的边进行分类,也可以去判断两个节点之间它是不是存在一条边,其实都是链接预测的这样的任务。相对应的例子,比如说像推荐系统,知识图谱股权等等,其实都是链接预测对应的实际应用。
节点和链接预测这两类任务以外,我们会有图的这样的一个预测。其中一个例子就叫做社区的子图检测,比如说我想判断一个比较大的图当中,是不是存在一类模式,就比如说节点之间它是某一种互相关联的关系,这类任务叫做社区子图的检测。常见的一个应用,比如说我们在金融风控中会经常发现,比如说一种欺诈行为,它其实有一种很强的这样一个图的 pattern,我能不能在一个复杂的金融交易网络当中检测到这种 pattern,其实就是一个子图检测的任务。
最后也会有整图检测这样的一个任务。整图检测往往是一个比对于比较小的这些图,比如说我们可以把药物的分子或者说一些化合物把它给认为是主图的结构,然后我去判断说给定一个药分子的这样一个图的结构,我能不能去预测出分子是否具有我们想要的某种化学性质,这类的任务就是整图的性质预测。
图应用案例
社交平台上的水军检测
刚刚讲的可能是一些比较抽象的分类,接下来我讲几个实际的例子。
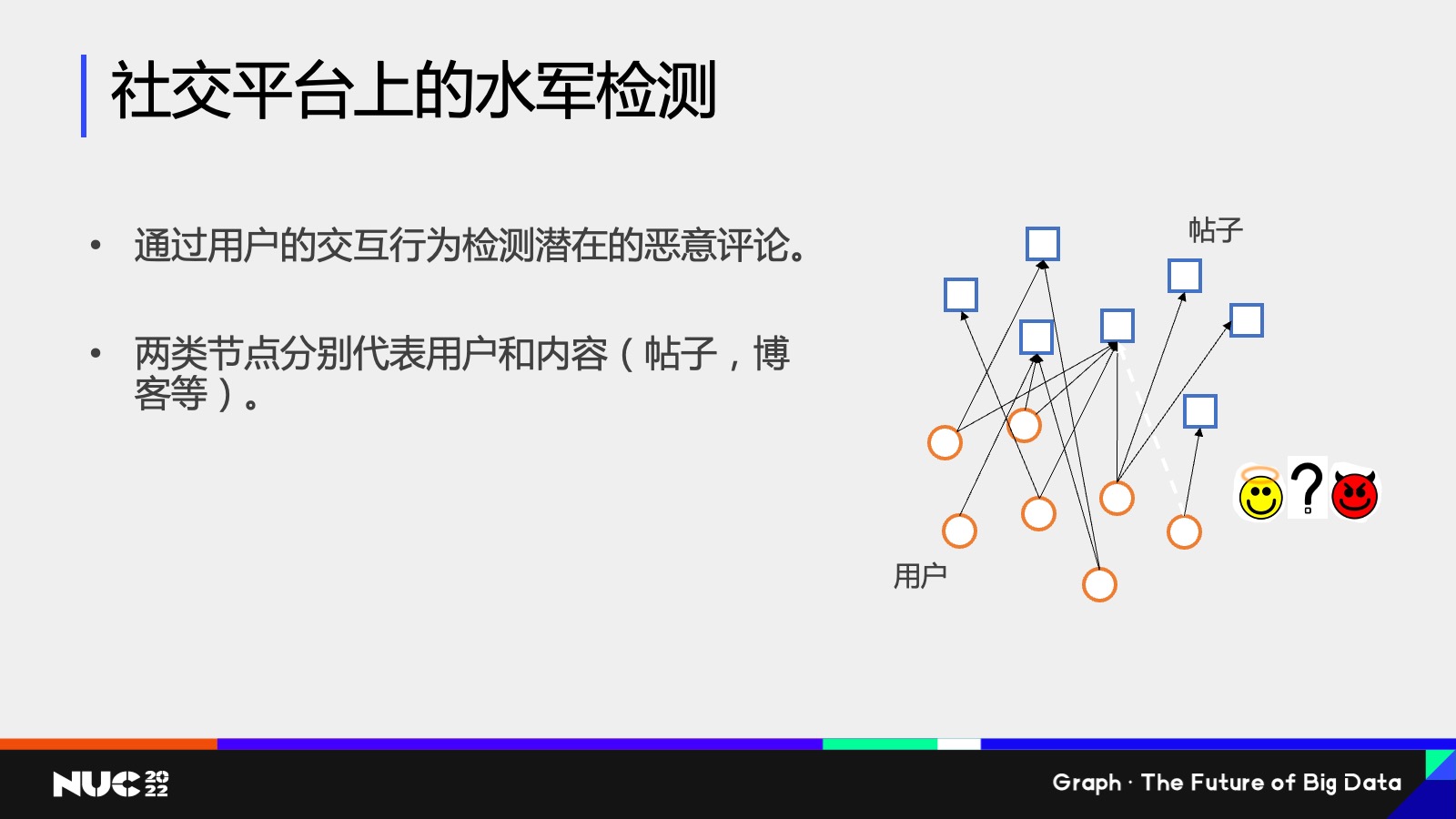
第一个例子,我们实际做的一个客户案例。这个客户是一个社交平台,它的一个任务是水军检测,它的数据其实大家在 PPT 上可以看到——有一个异构图,这个图上有两类节点,一类是这个帖子的节点,一类是用户的节点,我分别用圆圈方块来表示,这些边代表的是用户和帖子的交互关系,比如说用户点赞转发帖子等等这些。水军检测这个任务对应的是,如果出现一类新的交互关系,我要去判断说这个关系究竟是一个好的关系,还是一个恶意的关系,其实这对应的就是我们刚刚提到的边的分类任务。
所以其实可以看到,对于水军检测这样一个任务本身,我们可以把它给抽象成一个图上的机器学习任务。
药物重定位知识图谱
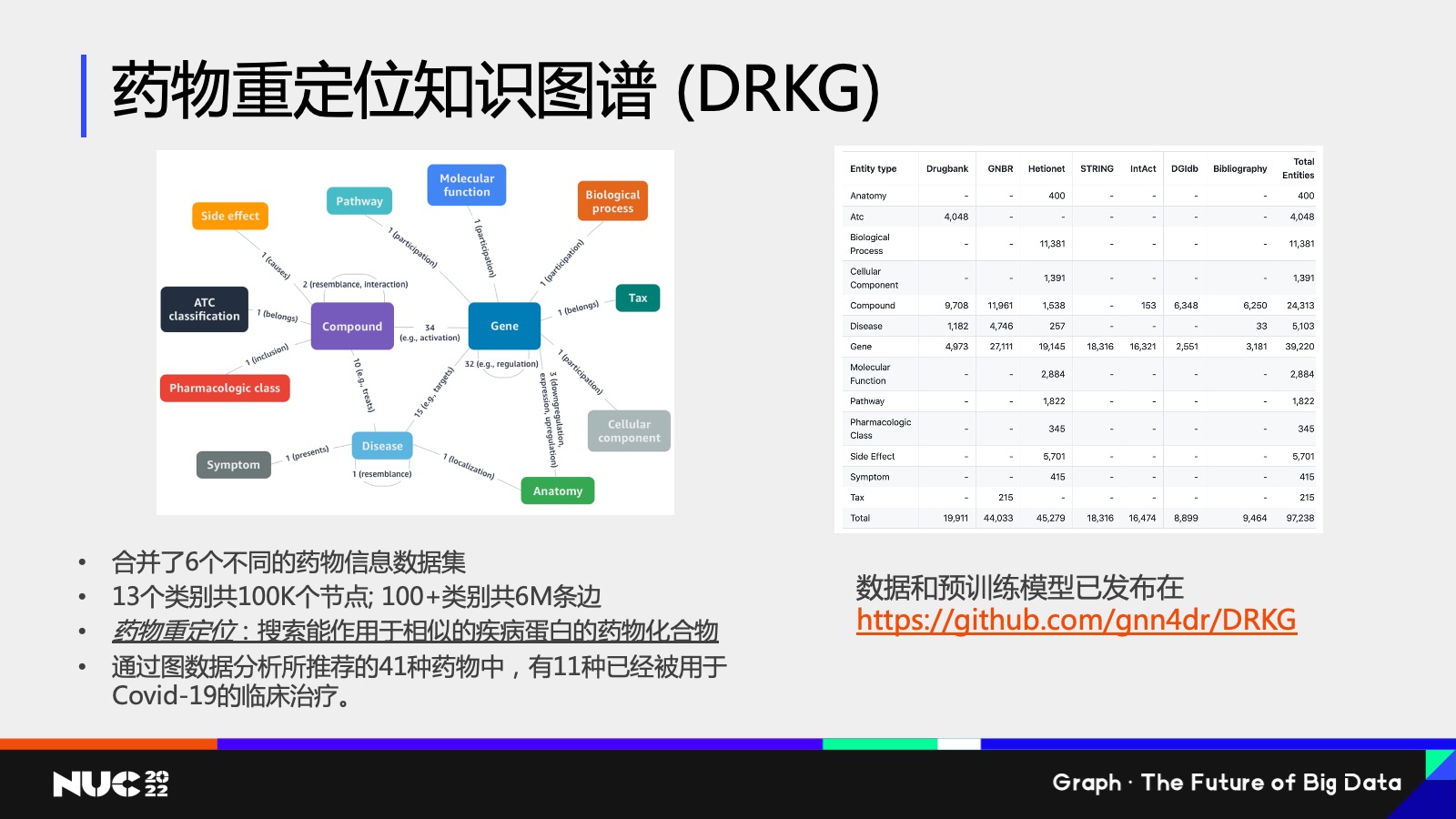
第二个例子我想讲的是我们研究院做的另外一个工作,这个工作其实是2020 年时做的,因为那个时候正好是新冠病毒肆虐的这样的一个时间,想看我们能不能通过我们研究院所做的图的主题,来给抗疫攻坚战贡献一份力量。
当时我们想做的一个任务叫做药物重定位,什么叫药物重定位?我们知道一个新的病毒产生,我们希望能够立马找到它的靶向药,但是一个药物的审批流程是非常长的,所以我们想要做的事情就是在已经审批过的药物当中,能不能把这个药物重定向为新的病毒的靶向药。当然这个过程是非常复杂的,我们做了这么一个知识图谱,叫做 药物重定位知识图谱(DRKG)。
可以看到左边这个知识图谱的 Schema 是非常复杂的,在这个图当中,比如说有 Compound 的化合物基因,包括 Disease 等等不同类型的节点,我们怎么去解决药物重定位的问题?其实也是同样的思路,我们把药物重定位的问题给映射成这个图上的一个机器学习问题。
如果把药物重定位映射成图上机器学习问题,它其实对应的就是一个链接预测,我希望能够去判断,比如一个疾病节点,它是不是潜在地和某一个药物节点之间有一个潜在的靶向连接关系,如果说通过数据分析能够判断出来有这样潜在的连接关系,就有理由相信说这类药物是治疗这类病毒的一个潜在的药物。
通过这个方式我们也做了一些建模,包括一些数据分析,最终的结果我们发现通过这个图数据分析的方式,所推荐的 41 种药物当中,有 11 种还确实是被用于 Covid-19 的临床实践的。所以可以看到其实在这个图数据当中,我们可以学习出很多有重要价值的信息和(取得)一些结果。
图神经网络 (GNN) 的介绍
什么是图神经网络(GNN)
实际过程中使用图数据去解决问题,大家可能会想到说我有这样的任务,我有这样的一个需求,我应该用怎样的模型去解决它呢?
现在主流的或者说一个非常火热的方向,(就是)把我们知道已经非常成功的深度学习技巧引入到图数据的学习当中,因此也就诞生了一类新的图数据库,叫做图神经网络 Graph Neural Network,GNN。
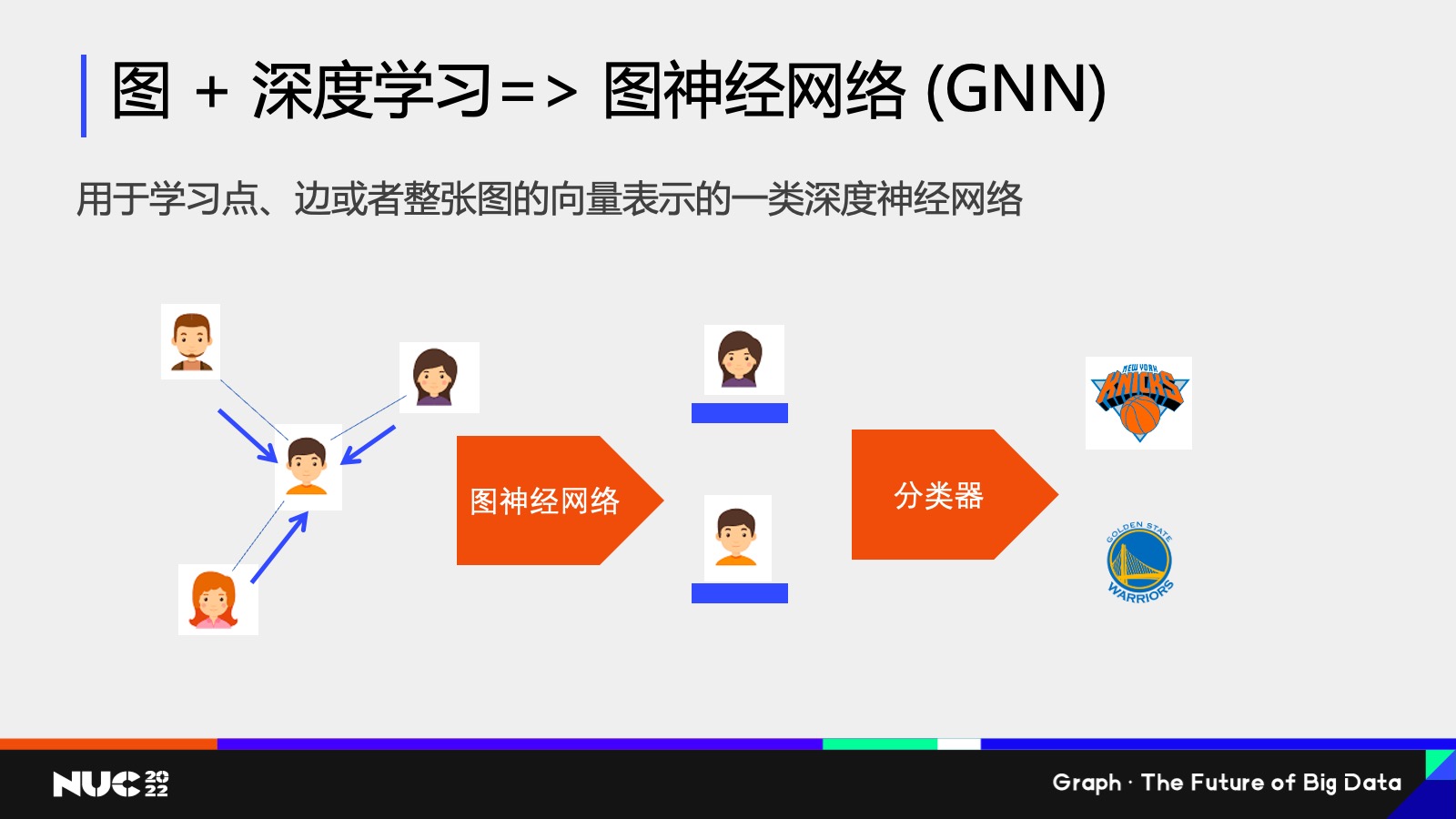
什么是 GNN?我这边做一个简单的介绍,如果做个类比的话,我们可以想象说非常常见的传统的比如说卷积神经网络,它是用于比如说图像识别这些任务,其实这些神经网络它的一个目的就是说我获得一份输入的数据,然后把这些输入数据变成一种高维空间中的向量表征。其实图神经网络也是对应的类似的这样一个技巧,它的输入数据是个图,所以自然地我就可以把这个图上的点边,甚至于整张图这个数据通过图神经网络的学习映射成一个高维的向量——其实这就是图神经网络。
这边有个简单的例子,比如说我们可以看到左边的输入数据是一个简单的社交网络,每个节点是个用户,用户和用户之间是朋友的关系,我可以通过神经网络给不同的用户生成一个高维空间的向量,它不仅仅包含比如说用户本身的画像信息,同时也会包含它周围邻居的结构信息。通过这样一个画像,这样的一个高维向量,我可以把它输入到分类器中去判断说他的一个兴趣爱好。
图数据网络为什么强大?一个原因就在于它在计算的过程当中,其实不仅仅考虑了一个节点自己的画像信息,也考虑了一个节点它周围的邻居的结果。
做一个很简单的类比,比如说如果要判断我到底喜欢哪一支 NBA 球队,最简单的方式就是看我的社交网络上我的朋友到底喜欢哪支 NBA 球队,如果发现我 99% 的朋友都喜欢,比如纽约尼克斯,我有可能也是这样一个球队的粉丝。
同样的,图神经网络也利用这样的一个很朴素的思想,也就是说当我在计算某一个节点的向量的时候,我会去收集它周围邻居的向量特征,然后做个聚合,通过这样的不断的迭代的方式,我可以获得图神经网络的最终输出的结果。
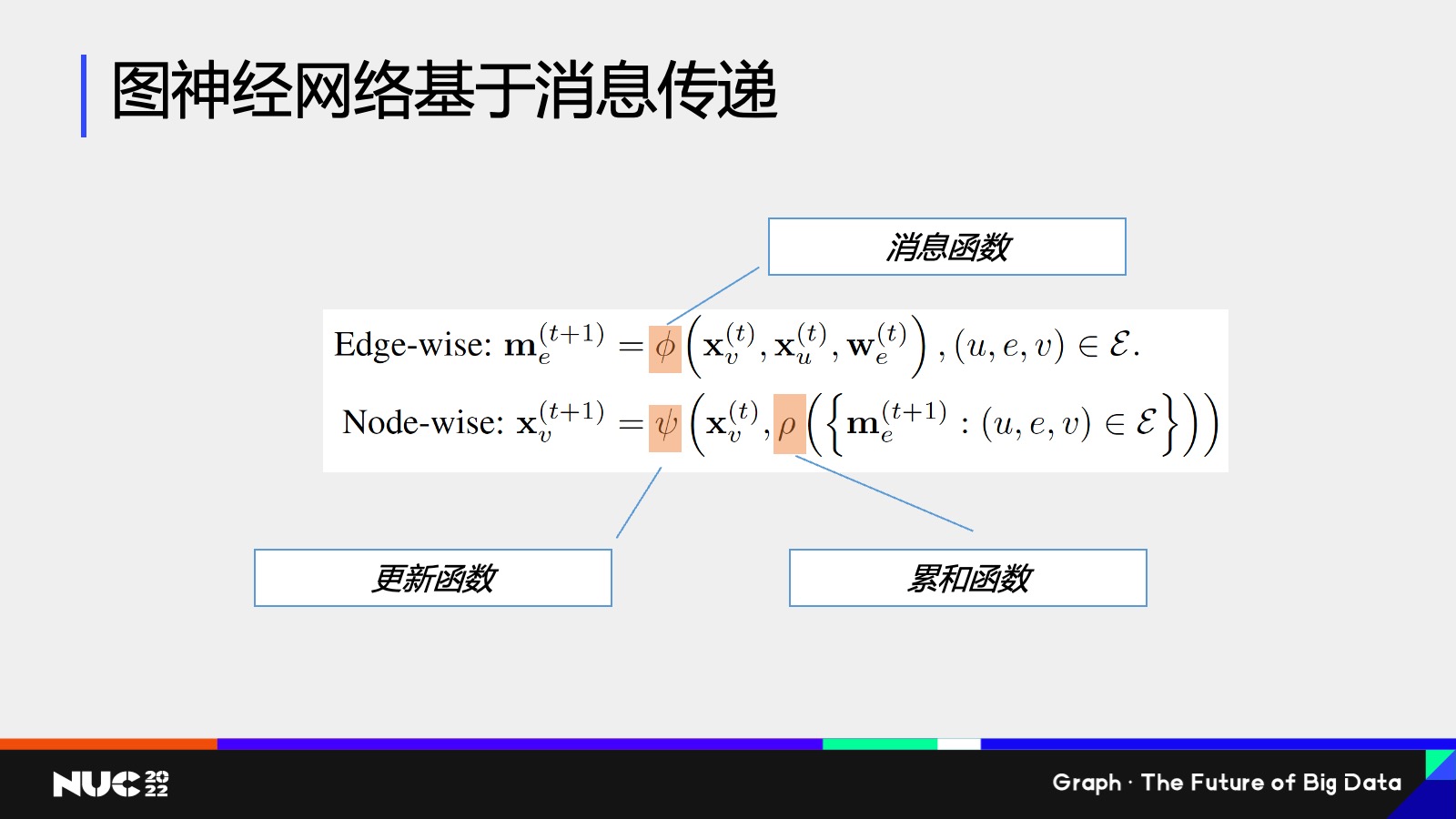
这边简单看一个公式,总体来说就是刚刚我们所说的这样一个过程,就是通过收集邻居信息,然后再做聚合的过程。
这个过程叫做消息传递,可以用一个数两个数学公式去表达。大家要记住这个词,消息传递是非常重要的,是我们图神经网络一个核心的概念。这当中其实包含了两类的计算,一类是在边上计算,去计算一个节点,到底要给邻居发怎样的消息,对应的当中也会有一个函数叫做消息函数。
然后另外一个是在节点上发生的计算,就是说(节点)现在收到了很多邻居的消息,我怎么把它给聚合起来,所以这对应的也会有一个累和函数。然后我通过了这些累和的消息以及我自身的消息,去重新更新自己的向量特征,所以这边会有一个更新函数。
图神经网络的灵活性以及强大在于,我刚刚所提到的这些消息函数、累和函数、更新函数,可以通过你自己的场景和任务本身去定制,也就是说图神经网络它不是一个模型,它是一类模型,而我完全可以根据你到底是做的怎样一个下游任务,去定制化这样的一个函数来获得更好的效果。
图神经网络的现状
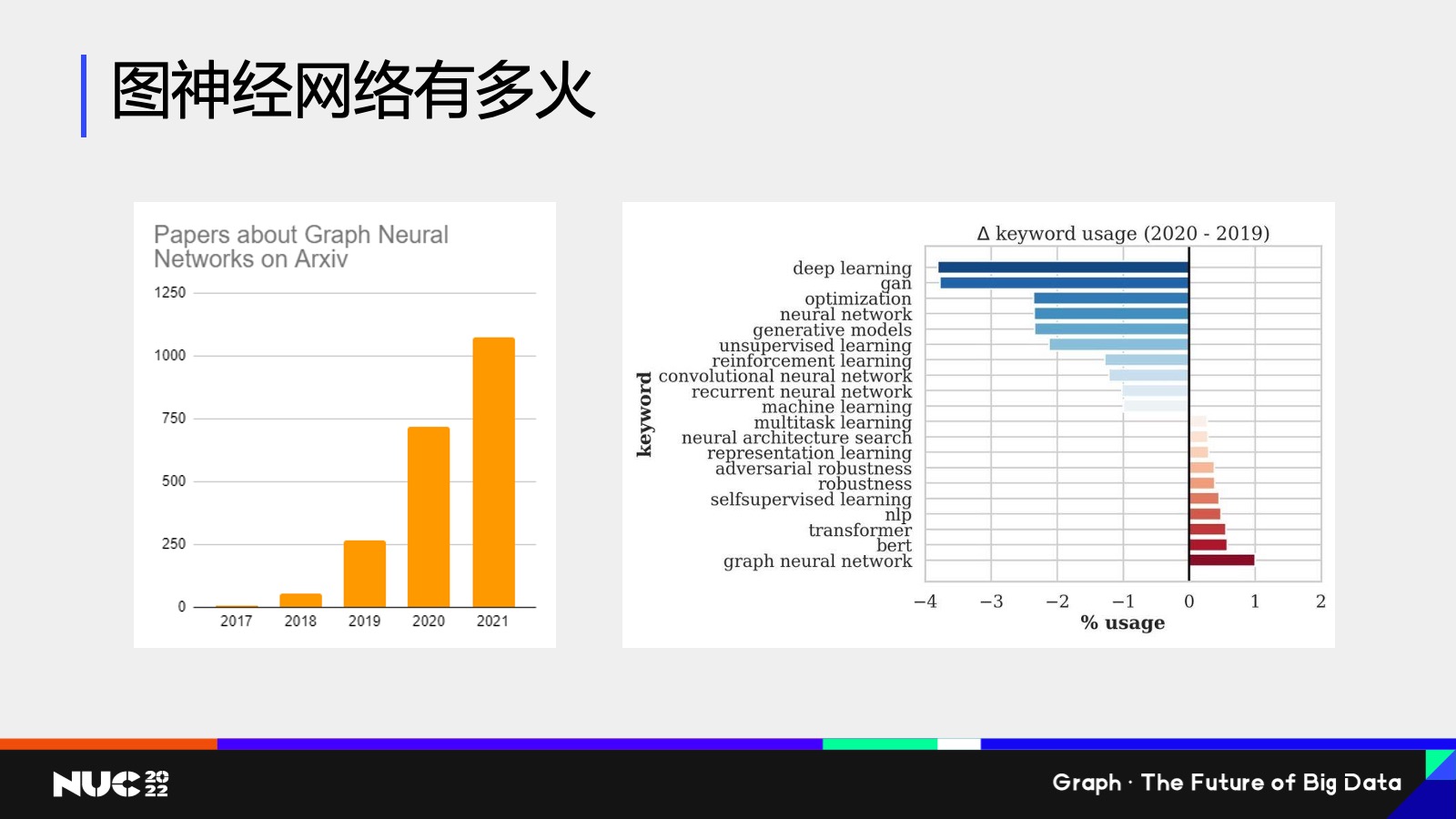
我们可以看看基于这样的一个思想,这类我们叫做图神经网络(的思想),它到底有多火——这边做了一些简单的统计,这是我自己做的在学术圈的一些统计,也并没有计算最近的一些文章。但是总体来说可以看到,关于图神经网络的论文数目每年的增长数目几乎是呈指数级的,然后在学术会议方面,图神经网络也是非常火热,(可以说)是最火热的关键词之一。

在学术圈,在今年年中刚刚结束的亚马逊云科技的发布会上,我们的资深副总斯瓦米(Swami)也是专门提到了 Graph Neural Networks,他专门提到说 Graph Neural Networks are the next big thing。也就是说其实不论是学界还是工业界,都是认为图神经网络是非常重要的、里程碑式的一个发展。
DGL 的创立与发展
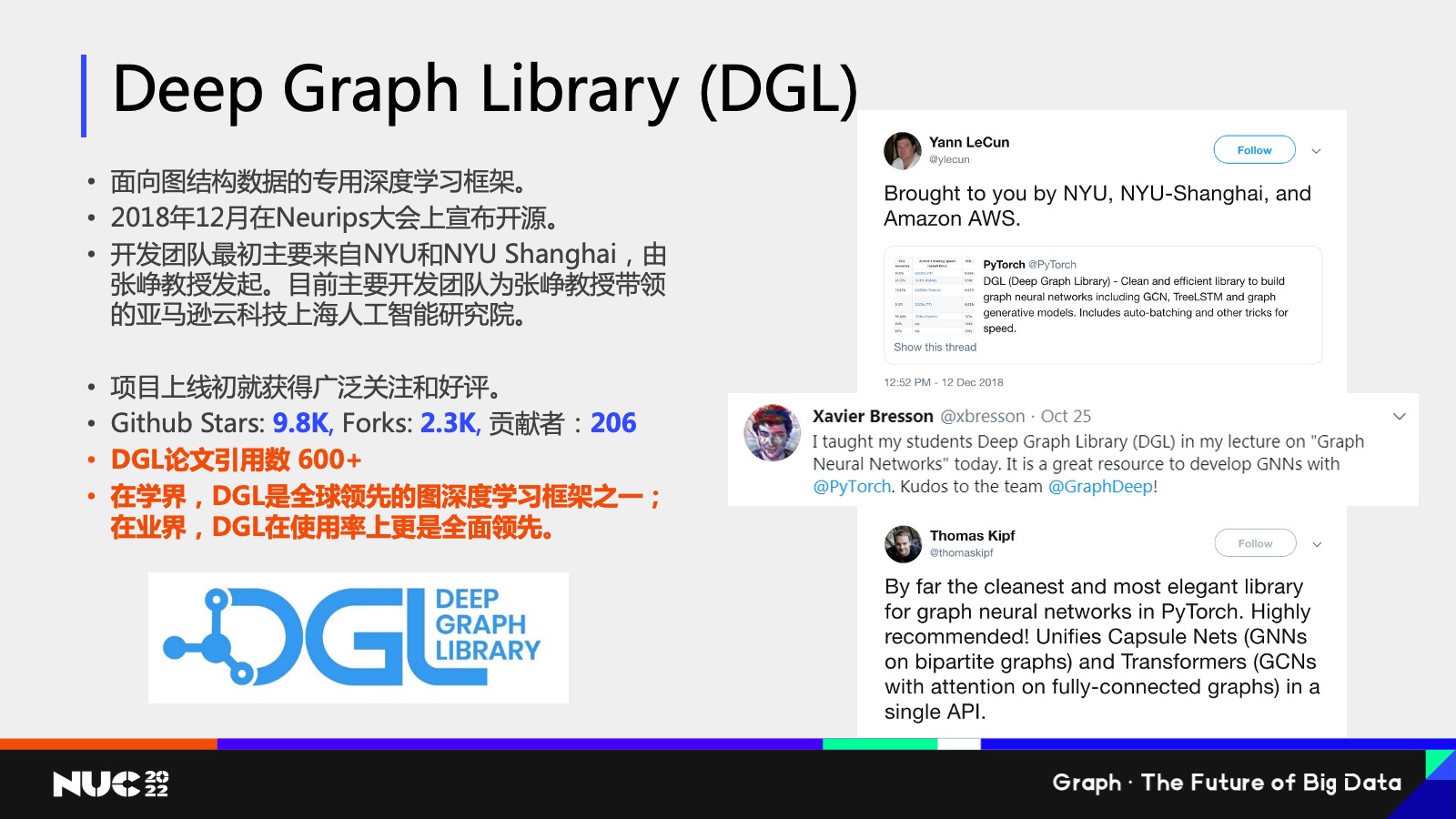
正是因为看到了这样一类新的神经网络的诞生,所以我们其实整个团队也是很快就跟上了。
我们是在 2018 年 12 月的时候开源了我们的图神经网络框架叫做 Deep Graph Library(DGL),我们这个框架是专门面向图数据结构专用的一个深度学习框架,我们开发团队包括我本人也是来自于 NYU 和 NYU Shanghai,由张峥教授发起,现在也是由我们整个亚马逊云科技上海人工智能研究院所负责开发,我们整个项目在上线之初就获得了广泛的好评和关注。
这边可以看到右边是一些不同的推特,就说当时我们刚刚上线的时候,有很多的知名学者,包括像图灵奖获得者 Yann LeCun 也是专门给我们点赞,我们现在的 GitHub Star 数已经超过 1万了,总体来说在一个良好的这样的一个增长的趋势当中。可以这么说,DGL 在学界可以说是全球领先的深度学习框架之一,在业界 DGL 的使用率上也是全面领先。
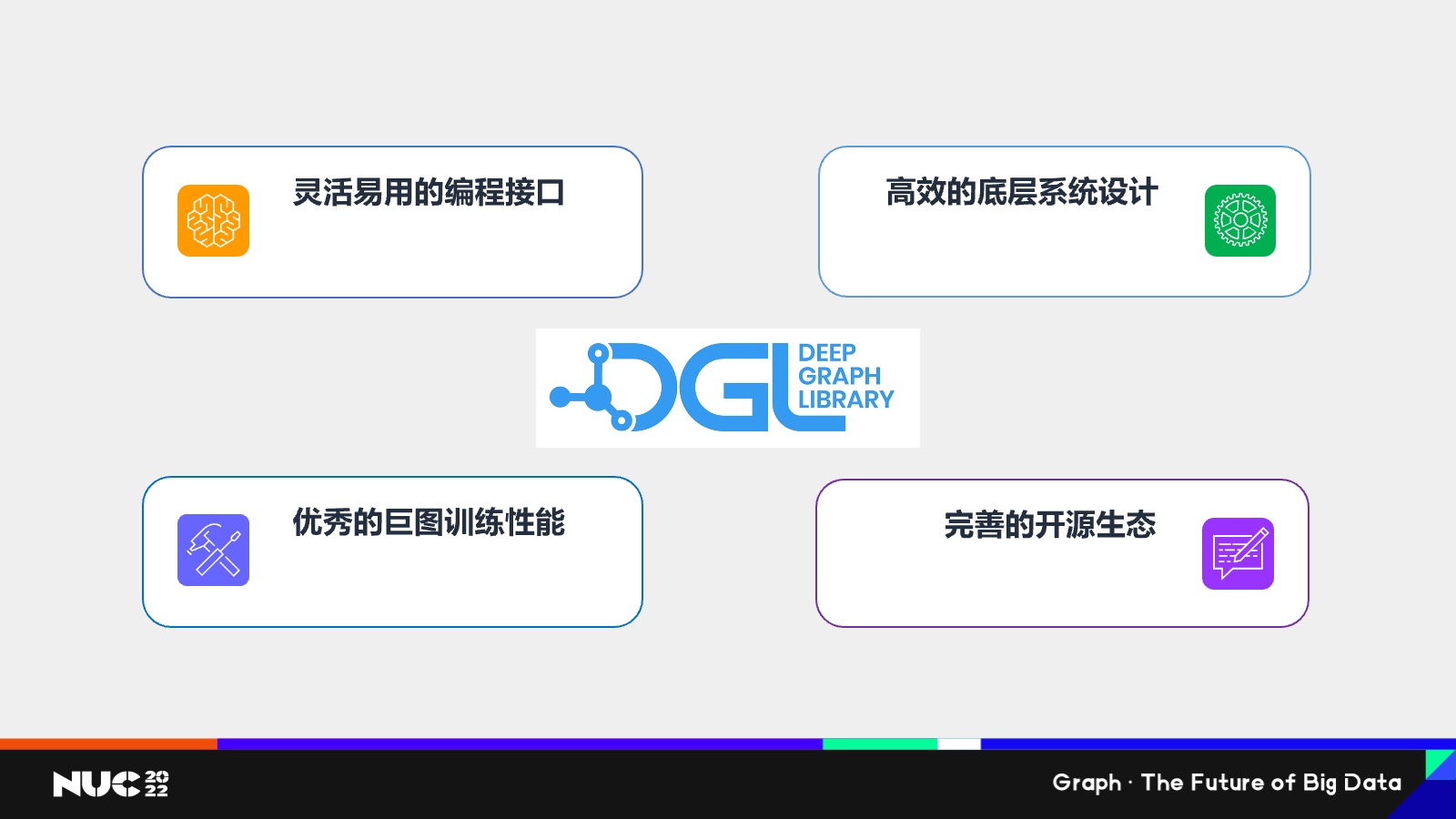
所以为什么 DGL 这么受人欢迎,我总结下来有4个原因——
第一个是我们有一个灵活应用的编程接口。图神经网络其实是作用在图上的这样的一类神经网络,所以其实包括我们刚刚看到这些消息传递对吧?我收集连接的信息,然后再累和其实都是图上的一个概念,所以我们采用了一个以图为核心的这样一个编程接口,使用户在编写图神经网络过程当中觉得非常的简单易懂。
第二点是我们有非常高效的底层系统设计,原因也是因为图和比如说我们常见的深度学习所遇到的数据,比如说张量等等是不一样的,图它是稀疏的,并且它是不规则的,所以他其实对于底层比如说用 GPU 加速是有挑战的,在这一点上就是专门实现了很高效的底层设计,使得比如说大家写了一个图神经网络,它能够很方便的在GPU上进行加速。
第三点就是我们有优秀的巨图训练性能。在实际场景当中一个图可能非常大,可能有百亿级的点和边,怎么去训练这样的大图是一个非常难的挑战。DGL 在这当中做了很多的探索,也做了很多的实践。
最后是作为一个开源项目,我们也非常关注开源生态的完善,现在也看到很多的 Package 在 DGL 上进行构建。

这边着重谈谈我们开源社区建设的情况,首先是我们有广泛的开源合作的伙伴,包括比较大的芯片厂商,也有比如说知名的高校,国内的公司等等;我们也每月会定期组织用户群的分享会,会邀请学界和业界的研究者一起来分享这个图神经网络最新的成果。因为我们也知道这是一个非常新的领域,所以也希望通过大家的交流来迸发出一些新的这些研究的 idea。
最后就是说 DGL 其实在很多的学术顶会上都做过手把手的教程,包括像 KDD、WWW 等等,而且我们作为开源项目也会把所有的材料全部公开在网上,所以如果大家想要学习 DGL 想要去上手的话,可以在这些网站上找到我们的这些学习材料。
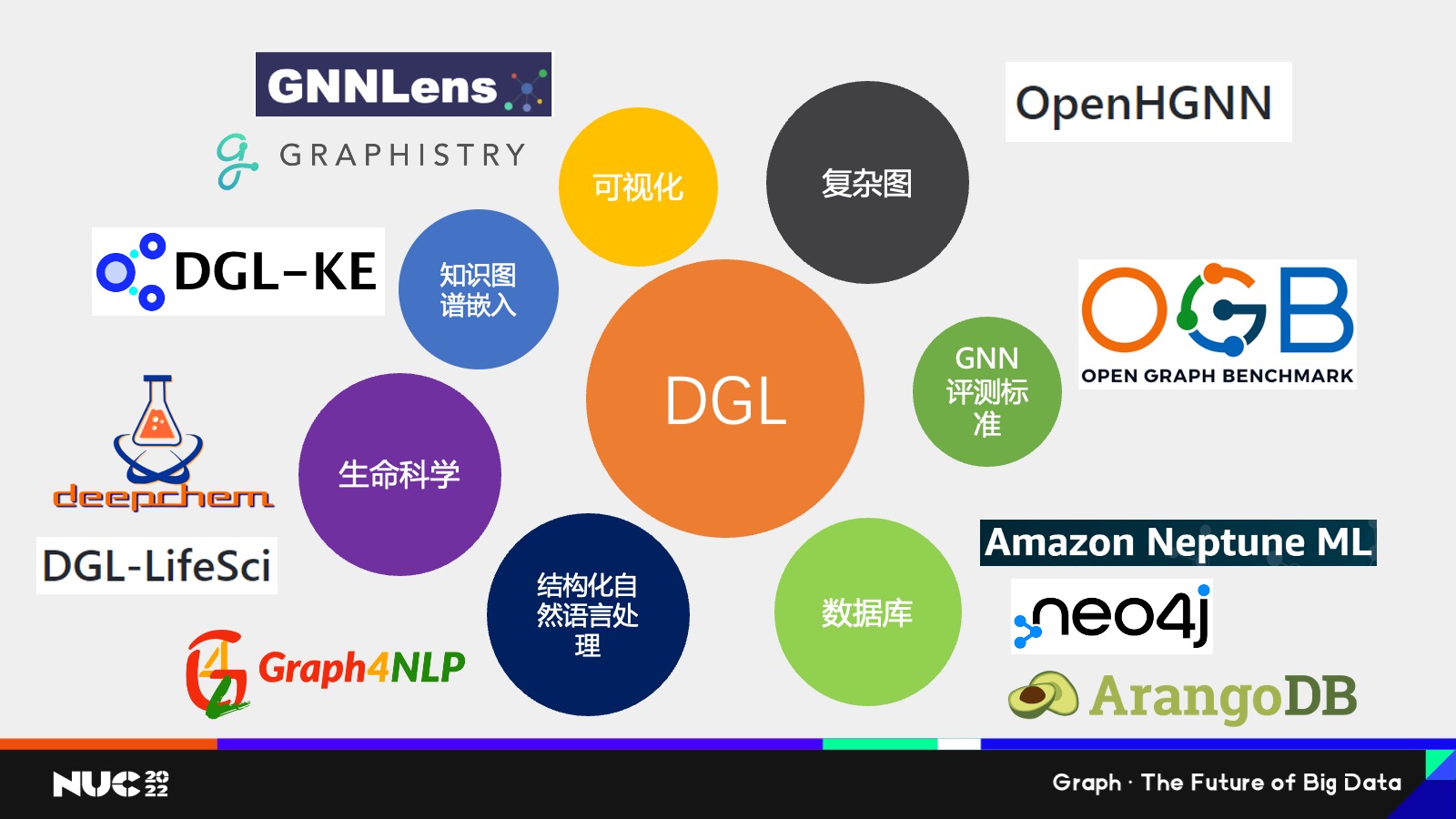
然后我们也知道就是说作为一个开源项目,一个很重要的就是建立一个开源生态,所以我这边也简单罗列了一下基于 DGL 所开发的很多项目,或者比较有 interaction 的一些项目。
首先是可视化,因为我们知道这个图是个非常复杂的数据,比如说我看张图片或者说看一段文本,我能够很清晰地了解它到底是什么意思,但是我看到这张图我可能就懵了,我不知道这个图连接在一起到底是什么意思,对吧?所以可视化就是个非常重要的一个手段去给我们的客户解释说图数据到底意味着什么。这边我们也看到有像学界的 GNNLens,包括业界的 HGNN 等等这些,他们都基于 DGL 开发了可视化的工具。
第二点是复杂图,因为我刚提到的一些图,比如社交网络它可能更多的是比较简单的图,因为其实只有一类节点,就是用户,用户之间比如说有个朋友的关系——但实际,我们看到很多的图它是异构的,它有不同类型的节点和不同类型的边,在复杂图上怎么去建模,这是一个比较难的问题,我们这边也有专门是北京邮电大学的石川老师组,可以说是国内做异构图最有名的组,他们所开发的叫做 OpenHGNN 这样一个项目,专门给大家提供了异构图的很多模型库,所以如果大家感兴趣的话,也可以去看一下 OpenHGNN。
接下来就是 GNN 的评测标准,作为一个新兴领域,我们肯定需要有很好的评测标准来衡量哪个图层网络模型更好,所以这边有 Open Graph Benchmark, OGB 也是现在目前最火热的 benchmark 之一,基于他也是开放了 DGL 的接口。
数据库的话,就是说我们知道有很多数据它其实不在内存里面,它可能一开始是来自于比如用户自己的这些数据的 warehouse 这边,也像有就 Amazon Neptune ML、Neo4j、ArangoDB,他们都提供了关于 DGL 的这样的一个开放的接口,我后面会提到我们的 NebulaGraph, NebulaGraph 其实和 DGL 也有一个良好的数据接口,然后我们专门还有一个和 NebulaGraph 的这样的一个实践案例,后面我会提到。
接下来是自然语言处理。这一点可能大家会觉得有点 surprise,为什么自然语言处理和 Graph 有关系?事实上我们去看一个文本的时候,我们去理解一段文本,其实一个很自然的想法是去理解它的结构,比如说我去理解这个段和段之间的上下的因果关系,所以其实在我们研究院看来,我们研究图本身不仅仅是应该局限在图数据,也应该去看说比如说一些非结构化数据当中有没有图这样的一个关系,其实学界当中和我们的想法有很多地方是不谋而合的,所以这边也有像 Graph NLP 这些专门基于 NGL build的给这些 NLP 的库。
生命科学也是非常重要,我刚提到像分子生物医药等等,还有这些微观的数据,其实可以认为是图,所以 DGL 也有专门的面向分子生物的包叫做 DGL-LifenSci,像在这个领域做研究,做了很多的同学可能会了解 deepchem 这么一个 package,这个 package 是有提供 DGL 所实现的模型,
最后就是知识图谱,知识图谱我不用多说了,作为一个非常重要的图数据的来源,在知识图谱上进行训练是非常重要的, DGL 也是有专门的 DGL-KE 这样一个知识图谱的支付搜索框架。
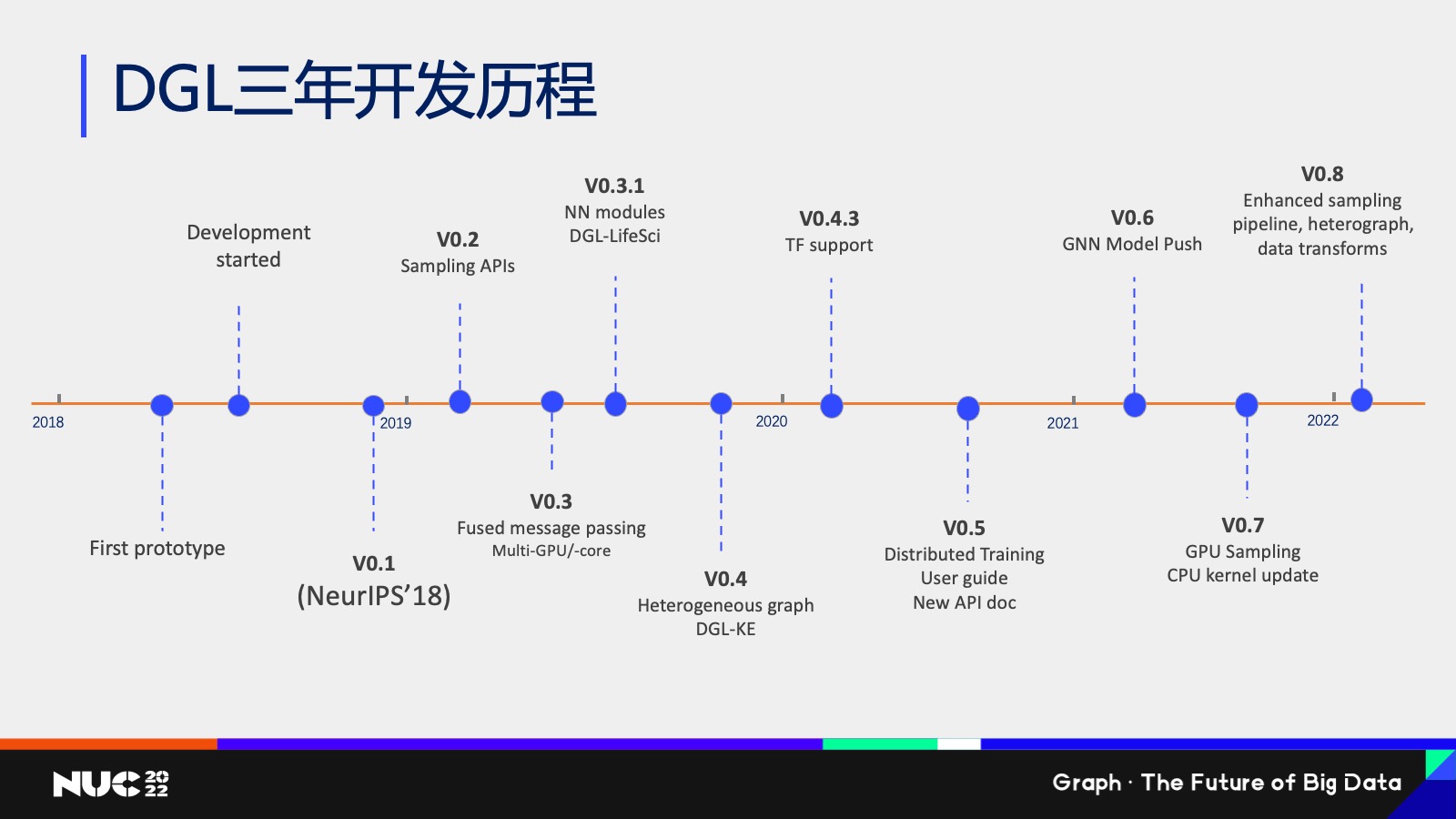
简单看一下 DGL 这三年的开发历程,其实我们从 2018 年年底发布第一个版本之后,一直在不断的开发新的功能,然后也是几乎每三个月大概是开发一个新的版本,然后每个版本就会添加很多不同的这样的一个支持,比如说大图的一些采用的算法的支持,包括分布式的训练等等。
开源图机器学习面临的挑战
介绍完 DGL 的事情,我想讲一下我们作为一个开源图机器学习框架面临的一些核心的挑战。
事实上如果我们去看市面上的图神经网络框架其实有很多对吧?不仅有 DGL ,还有像 Paddle Graph Learning、Jraffe、PyG 等等,有很多这样的一个package。
你可以想象就为什么有那么多 package,原因也很简单,就是我们还做得不够好,否则的话也不会有那么多 package 对吧?那就说明它其实有很多的挑战是我们没有办法很好解决的,也是我们在看的主要的方向。这些方向我总结下来一共有三点,第一点是易用性,我怎么让用户使用开发这个图神经网络变得非常方便。第二点是高性能,怎么让他们训练的过程变得非常快。最后就是大规模图我怎么去解决,在一个图上就是一个巨图的这样的问题。
大家可以看到这个图当中其实有很多的交集,也就是说其实我们在做的过程中,我们会发现,其实很多情况下它是有 trade-off 的,比如说如果我在易用性上我要达到一个完美的易用性,很有可能我在性能上就会有做一些损失,这个当中就会有带来了很多的研究的问题和挑战。
所以接下来我可能会讲一些我们研究院在这几个不同的交集当中,我们做的一些实践,以及我们做的一些研究的课题。
易用性和高性能的挑战
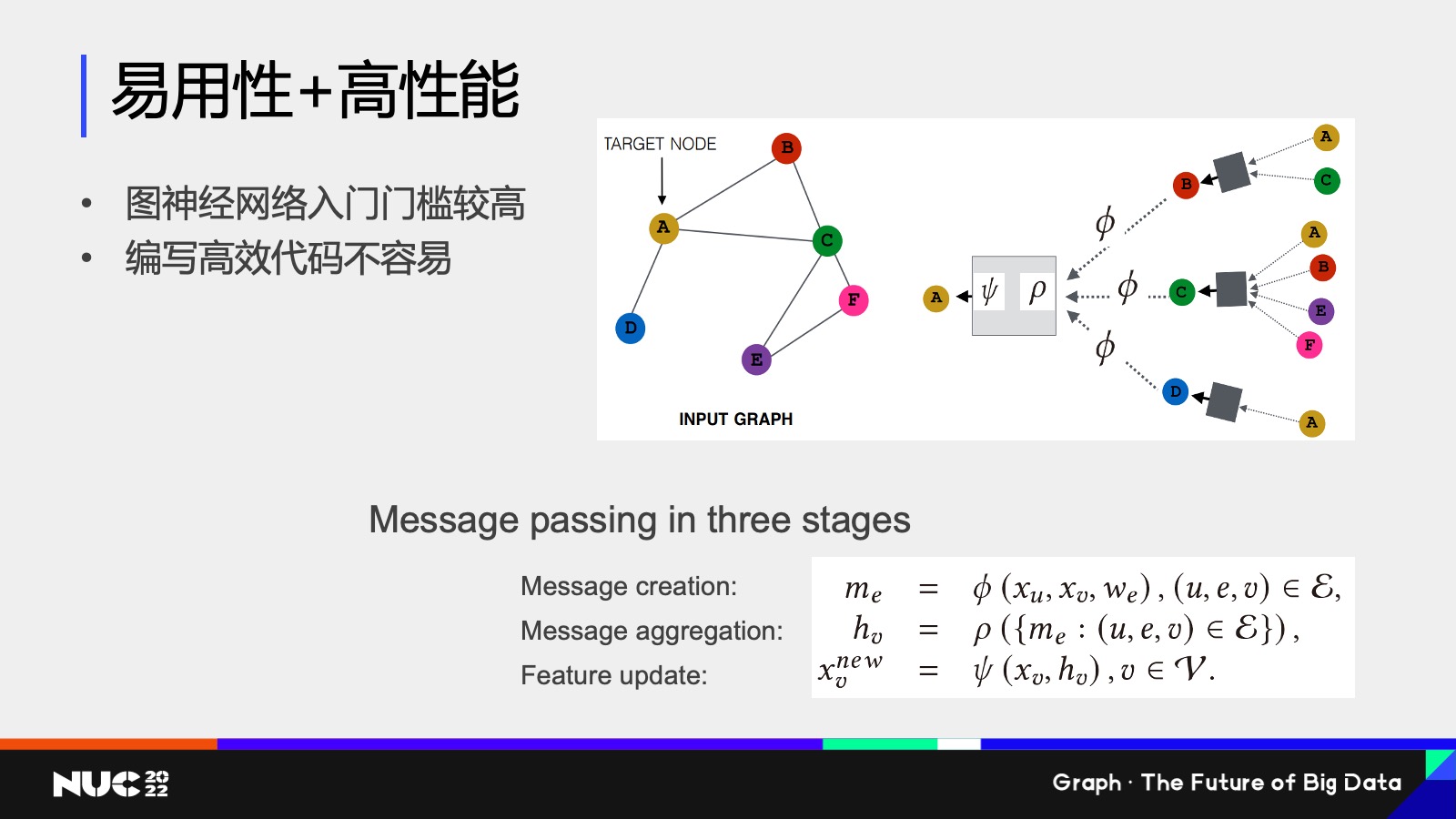
首先的一个问题我想说的是易用性加上高性能,因为我们做下来发现一个很大的点是说神经网络已经很难了,然后图又是一个很复杂的数据,所以当我们把这个图和神经网络结合在一块以后,就会发现这个事情特别难做,所以它的整个入门门槛是非常高的。
然后我在编写代码的时候,我很容易写出来非常低效的代码,原因也是跟我们刚刚所提到的说图它是一个稀疏的和不规则数据结构是有关的,而我们的底层的硬件芯片像 GPU 等等,它其实都更加关注的是这种规整的数据结构。所以如果我们去编写一个图神经网络的时候,很有可能最终的结果不会特别好。

我这边做一个简单的举个例子就说这边有一个网络叫做 Graph,其实大家不用特别担心说这个数这个公式怎么看上去那么复杂对吧?但是我可以给大家讲稍微讲一下,比如说大家如果回想一下图神经网络,我刚刚提到其实就是两类计算对吧?一个在边上的计算,一个是在点上计算。
我在边上要做的事情是把一个节点的消息发给邻居,在点上要做的事情是说我收到很多邻居的消息把它聚合,对吧?所以说如果我去看 GAT 这个模型公式,其实它也就是这两个计算,比如说公式 1 和公式 2 和公式 6,你可以看到他其实做的都是说在这个节点的边上,我计算某个东西,对吧?
我们不用管它算的是什么东西,你可以直接认为公式 1、2、6 它其实就是在边上进行计算,然后 7 这个公式是在点上算的,它的做法就是把这个点上就我刚刚算出来这些边上的消息做一个有机的结合,然后再把它聚合起来。
Ok,所以这就是 Graph Attention Network, GAT 这样一个模型。
如果我们去编写一个 code 在当中,其实边我们提供了两套方式去编写,第一套方式我们叫它 User-defined Function,UDF。这个一看到就是说如果用户去写 UDF 的话,它写出来是这样的一个两个函数,第一个叫做 message,第二个叫做 aggregate 对吧?虽然说写程序写的不多的同学可能不太了解,但是大概还是能够看出来,比如说每一行代码它对应的哪一行公式,对吧?
所以其实整体的代码逻辑是非常简单的,而且能够自然而然看出来它的对应关系,这样的一类编程接口就是非常直观,但是一个问题是在于说它非常低效,原因是在于我们要为了支持这样一种非常直观的编程方式,需要把图这种不规整的数据结构整理成规整的数据结构。
我可以举个例子,比如在图上很常见的情况是一个节点,它可能有不同数目的邻居,可能有的节点它是一个名人节点对吧?我可能有 100 万个邻居,但有些节点可能就像我们这样的,可能也就是比如说 100、200个朋友对不对?你在计算这个消息累和的过程当中,它的计算的代价是很不一样的,我为了要支持这样的一个方式,我需要把它进行分类。
比如说节点度数比较高的,我把它给聚在一块,节点度数低的我把它给分成另外一块,然后通过不同的批次的计算完成整个计算,可以想象这个计算本身是非常耗时的,原因也是因为我把一个大的规整,我把大的计算把它切成了很多小计算,切成小计算的代价,就是会增加很多系统上的一些 overhead。
所以在 DGL 当中我们提供了另外一种编程方式,就说对于一些高级的用户,我们推荐大家是怎么去写 GAT 这个模型?是让他们直接调用我们已经包装好的底层的算子。比如说下面这个例子,如果我要用 DGL 包装好的底层的算子去实现阶梯模型是怎么做的?
可以看到就是说首先虽然我有大概的还有个对应,比如说我这边用注释写了,说每一行公式对应的是哪一些代码,但是这个代码本身其实的可读性已经比上面要低很多了,我并不能很快的去了解说到底每一个 operation 到底在干什么。
这边可以看到有很多 DGL 的调用,比如说如我们看下面的这些调用,其实就是我刚刚提到的说提交已经封装好的底层的这些算子交给用户去做,但是理解这些算子的本身是有代价的,所以可以看到说这个当中也就是另外一类编程模型的这样一个问题,它虽然非常高效,因为每一个就是很高效的算子去帮你高效 GPU 的加速,但是它是直白的,然后这当中的性能差距能有多大呢?
当然得判断这个图的分布是怎样,但是最终的结果我们测下来大概平均会有 10 倍到 100 倍的差距,所以这个差距是非常大的。
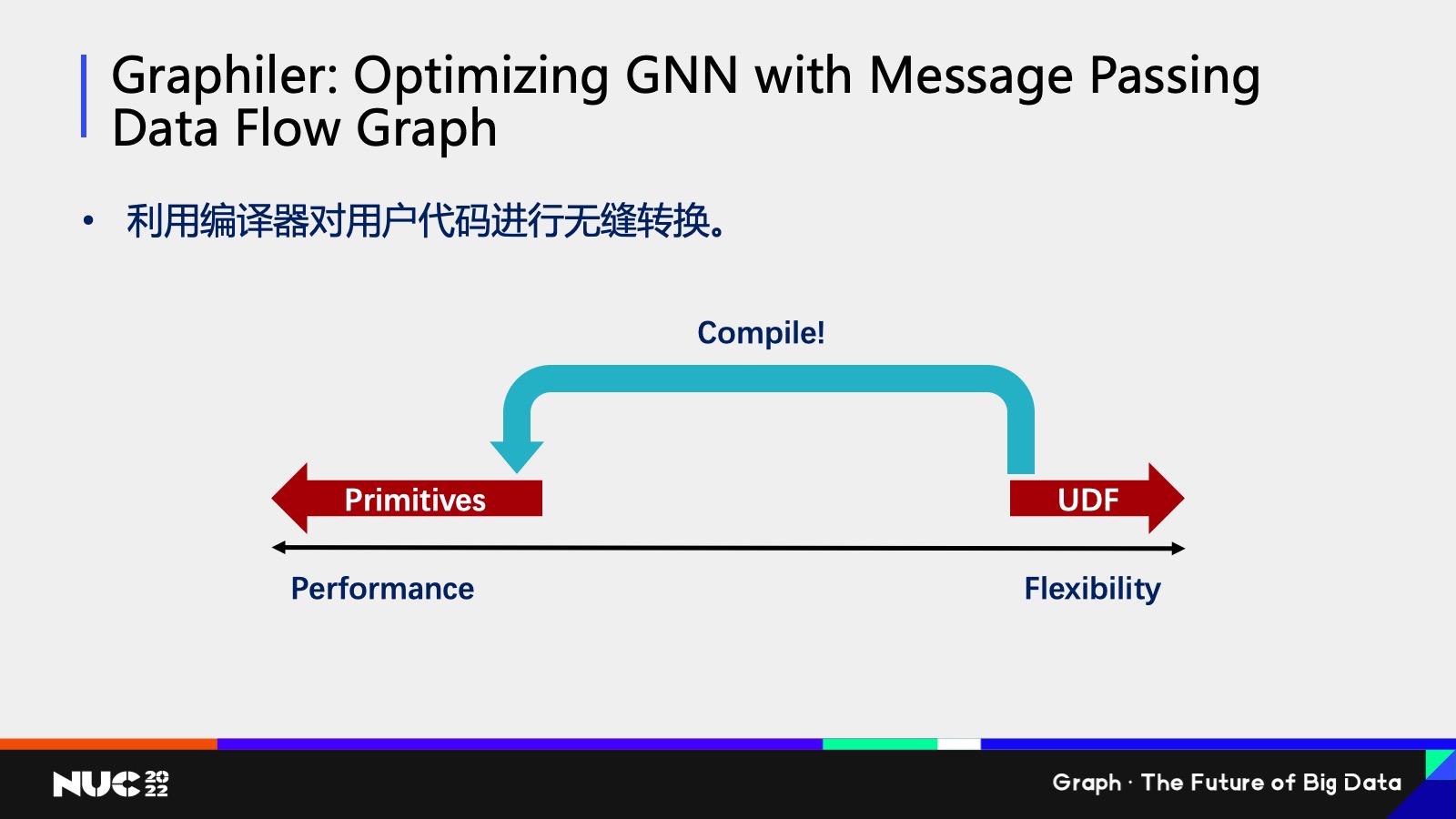
Ok,所以这其实就有一个 trade-off 在里面,就我刚刚提到的在易用性和高性能之间,它是有一个要做权衡的。
对于我们研究人员来说,我们想做的事情就是想了解说我们有没有办法达到又好用又高效。我们的解决方案去做一个编译器,因为我们其实可以看到就是说用户写的一些非常直白的代码,我完全可以通过一个编译的手段给翻译成我们刚刚所看到的非常高效的代码,用户不用去可见说当中的翻译过程,通过这种方式用户只需要写直观的代码,但是它能达到同样的,很高效的性能,这篇文章我们也是在今年发的一篇文章叫做《Graphiler: Optimizing GNN with Message Passing Data Flow Graph》,如果大家有兴趣也可以去看一下我们具体是怎么实现的。
大规模图的挑战

Ok,接下来的我想提的就是大规模图,是我刚刚所说的三中的第三个挑战,学术圈也是越来越关注这个问题。
比如说右边可以看到我刚刚提到的 Open Graph Benchmark,OGB 这样的一个评测集当中的数据集的大小,可以看到其实现在最大的图也是比之前要大很多了,像 MAG-LSC 有大概 240 million这样的一个规模,但是这个规模和我们工业界遇到的图的规模还是差很多的,我们公益就遇到了规模肯定是要在百亿千亿级量,就相相当于是这个图的大概 10 倍到 100 倍以上。
所以可以看到就说学界还没有感受到工业界的这样的一个规模,但是在这样的规模上其实已经有很多的问题了。
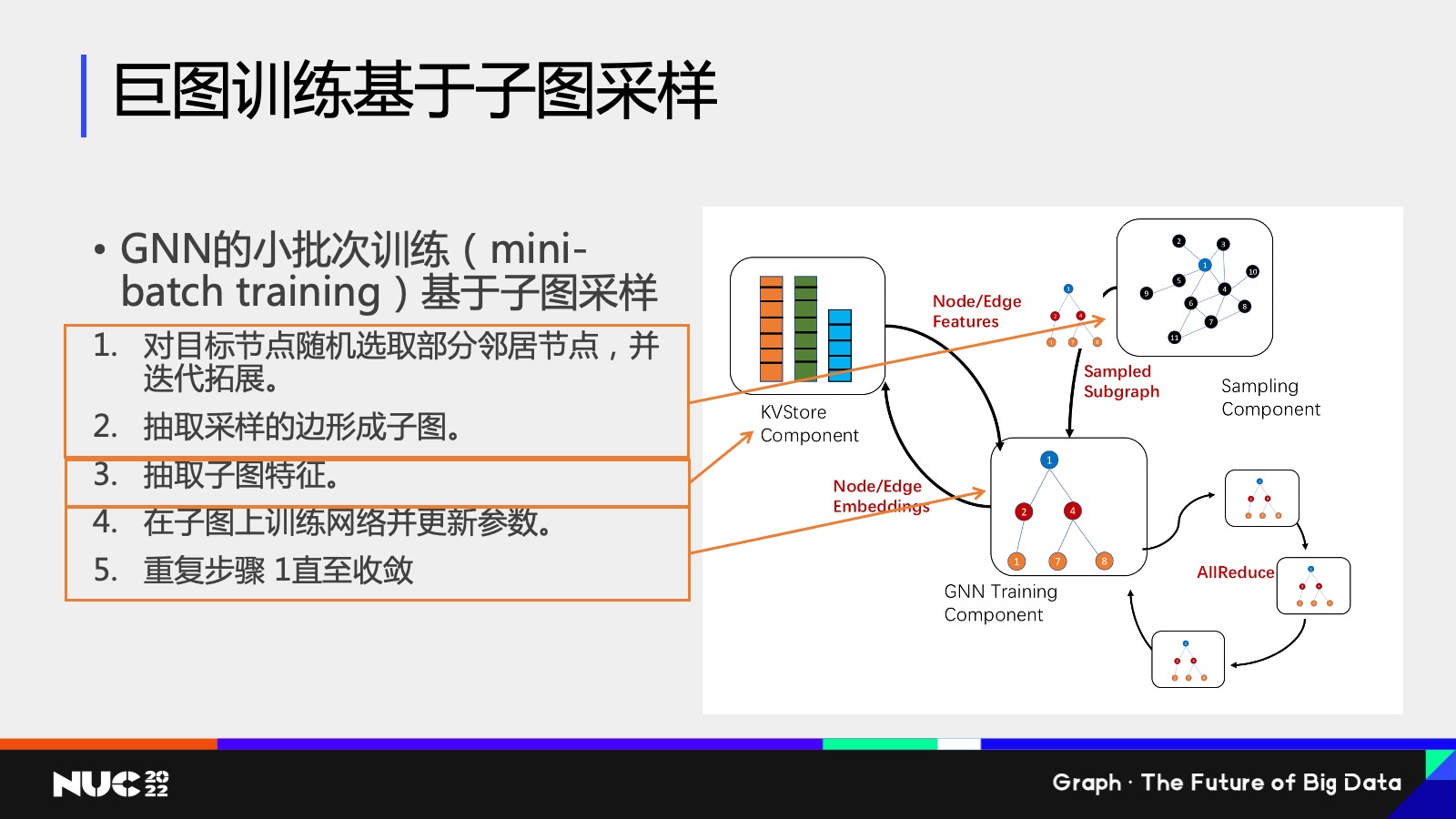
因为这个图很大,我没有办法把整个图放到内存当中,该怎么办?其实是需要做一个采样的方式去做训练的。这个在 GNN 当中我们也称之为叫做小批次训练,mini-batch training。
Mini-batch training 包含好几个步骤,首先是第一个步骤是,因为整个图没有办法放到内存里面,所以只能先选取目标节点,然后去看这个目标节点的邻居子图,把这个子图拿出来,这个图就小了。抽取出子图之后,再去根据子图的关系去把它对应的特征给拿出来,拿出来之后就获得了一些比较小的图。
然后在这个子图上训练网络,比如说可以把这个图放到 GPU上,因为 GPU 内存有限,但这个子图变得很小,我就把它放到 GPU 上进行训练,然后我在不断重复这个步骤,直到它的收敛。
可以看到其实整个过程是比普通的深度神经网络的小批次训练要复杂的,而这个过程由于它包含了很多的步骤,所以我们在设计 DGL 的子图训练框架的过程当中,也把它给分割成了不同的模块。
比如说对于第一个,我们把我们给定一个节点,我们去抽取他的邻居的子图,这个模块我们称之为采样模块,这个模块就在右边这个图上对应的叫做 sampling component,这个模块它负责的作用,就是说我把这个子图抽出来,把它给喂到下面的步骤当中去做计算。
然后第二个是子图的特征的存储,我们知道子图特征其实本质上是很多高维向量特征,高维向量特征我其实可以用一个传统的 key value store 的方式把它给存储起来,其实我们专门为图神经网络设计了一个 Key value store 的这样一个component,然后当把这个图采样和子特征都已经抽取出来之后,就可以把它给放到接下来的输入到接下来训练模块里边,而训练模块就很有可能在 GPU 上,而且可能会有多个这样的训练模块进行之间进行一个协作,可以获得一个更高效的并行训练的效果。
然后这样的训练分割其实可以部署到不同的硬件环境上面,包括我刚刚说的采样模块,特征模块、训练模块,根据不同的硬件环境,我可以采取不同的部署。
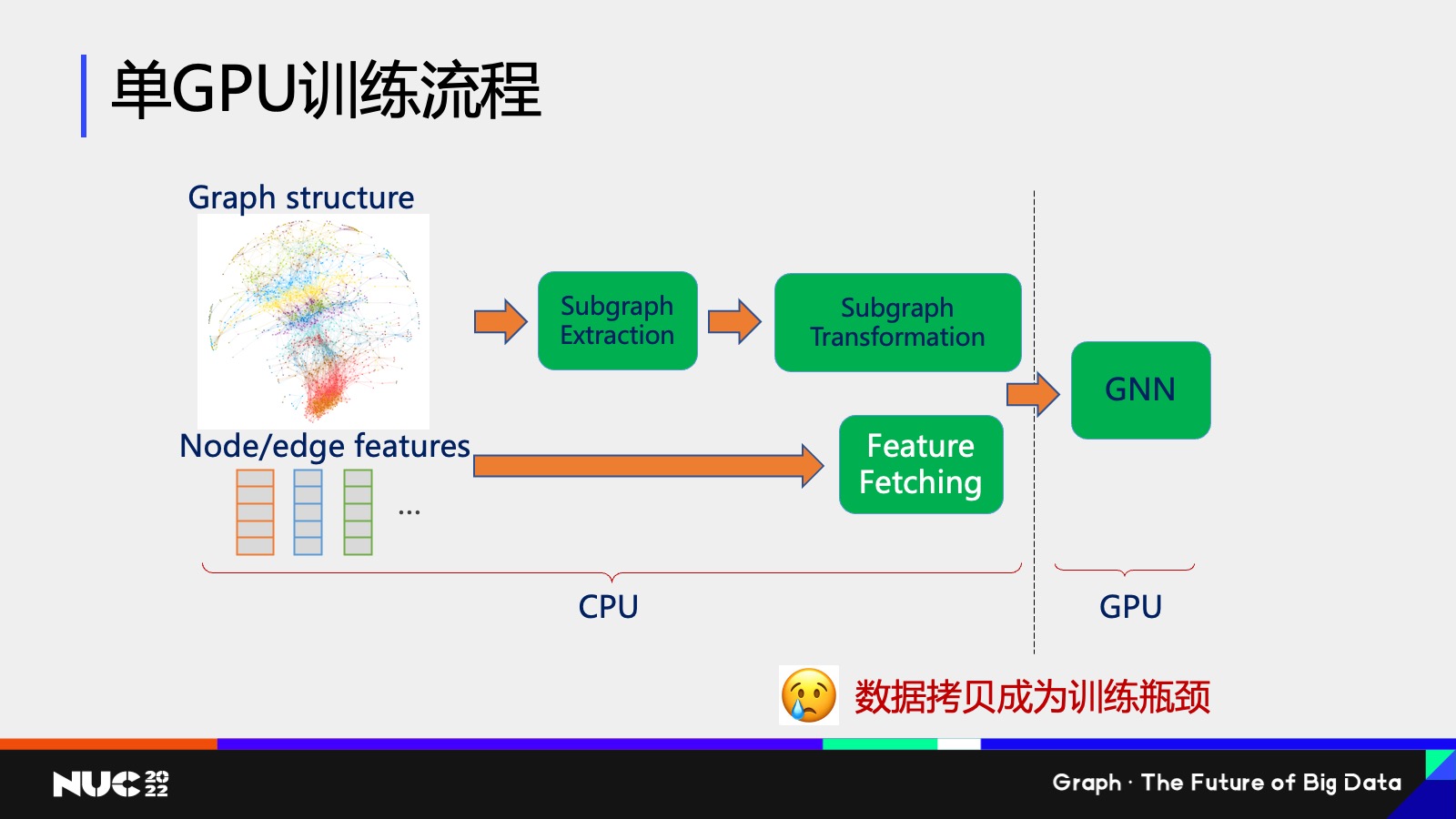
举个例子,如果现在是个单 GPU 训练这样的一个流程,现在有个 Graff structure 和一个 Node feature ,这些图都很大、整个特征包括图结构都很大,我没有办法放到 GPU 上。那该怎么做呢?OK,我(可以)放到 CPU 上。
通过刚刚说的先做一个子图的抽取,抽取完之后对这个子图做一些变换,然后把它对应的 feature 把它给抽出来,最终把它给交到 GNN 上做一个训练,其实这就是在单 GPU 上的整个训练的流程。
在传统的训练硬件的部署方面,其实是因为这个图很大,所以只能把前面的这些采样包括特征抽取的流程放在 CPU 上,然后把后面训练的流程放在 GPU 上。那这个过程就显而易见会带来一个问题,就是我们在从 CPU 到 GPU 的数据拷贝,它会成为整个训练的瓶颈。
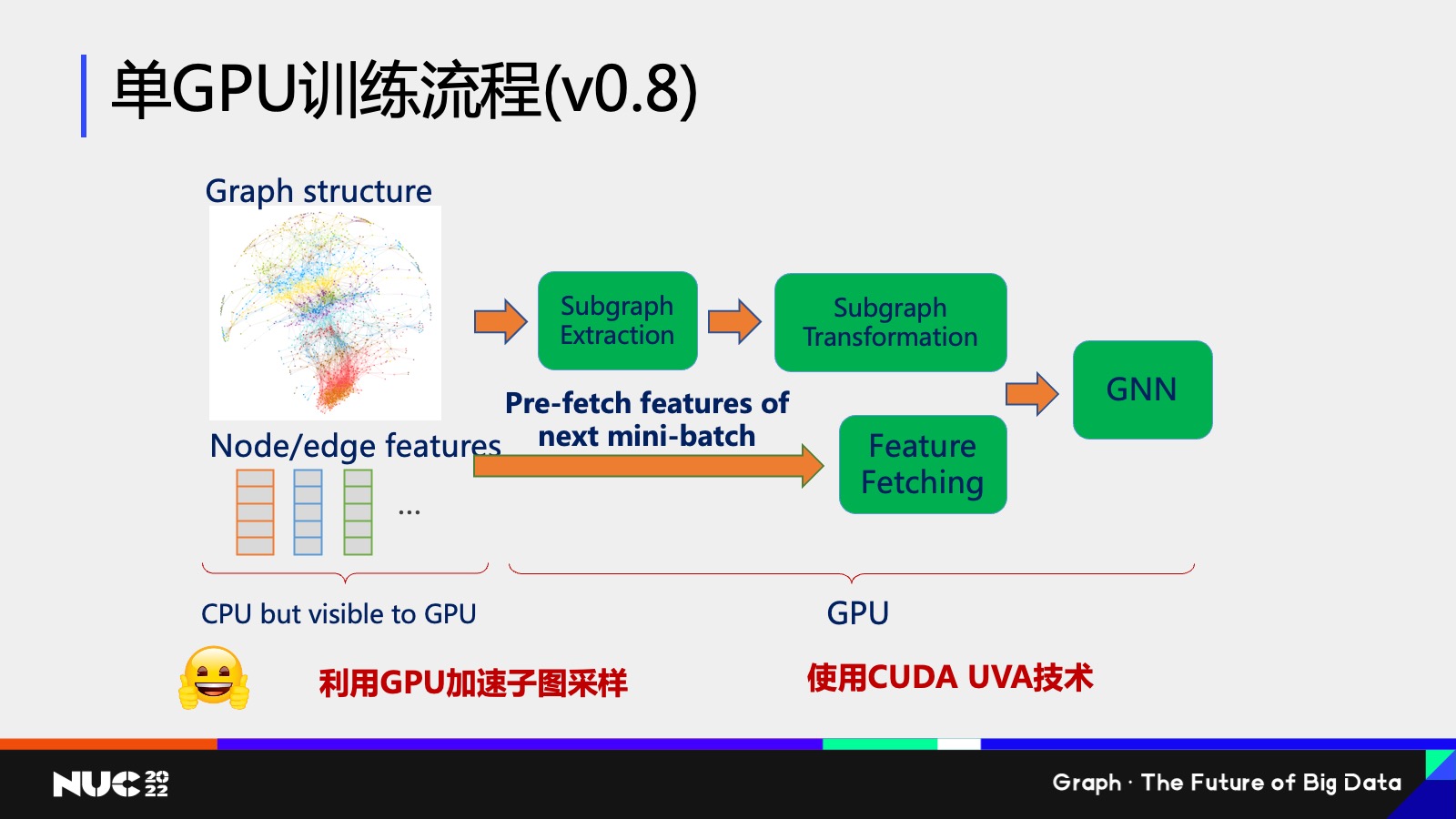
所以在 DGL 其实是上一个版本 0.8 这个过程当中,我们其实就对刚刚我说的流程进行了一个更新,我们的总体原则是说我们希望把更多的计算放在GPU上,这样才能更高效。但是因为 GPU 内存不够,所以我们需要使用新的技术来解决内存限制的问题。
我们使用新的技术就叫做 CUDA UVA 这样一个技术,如果我用一句话来概括它就是说我可以在 CPU上开辟一块空间,这个空间的大小可以和你的 CPU 的用量一样大,但是这块空间是可以被 GPU 访问的。这其实就解决了刚刚说的你的 CPU 用量不够,但是又想用 GPU 进行加速的这样一个问题。
通过使用 GPU UVA 的技术,我可以把所有的图的结构包括 feature 的结构把它放到 UVA memory 当中,这部分 memory 虽然在 CPU 上,但是 GPU 可见的,然后我把后面的所有的流程全部通过 GPU 进行加速,整个过程就会达到一个非常高效的这样性能。
如何借助图数据库解决这些问题
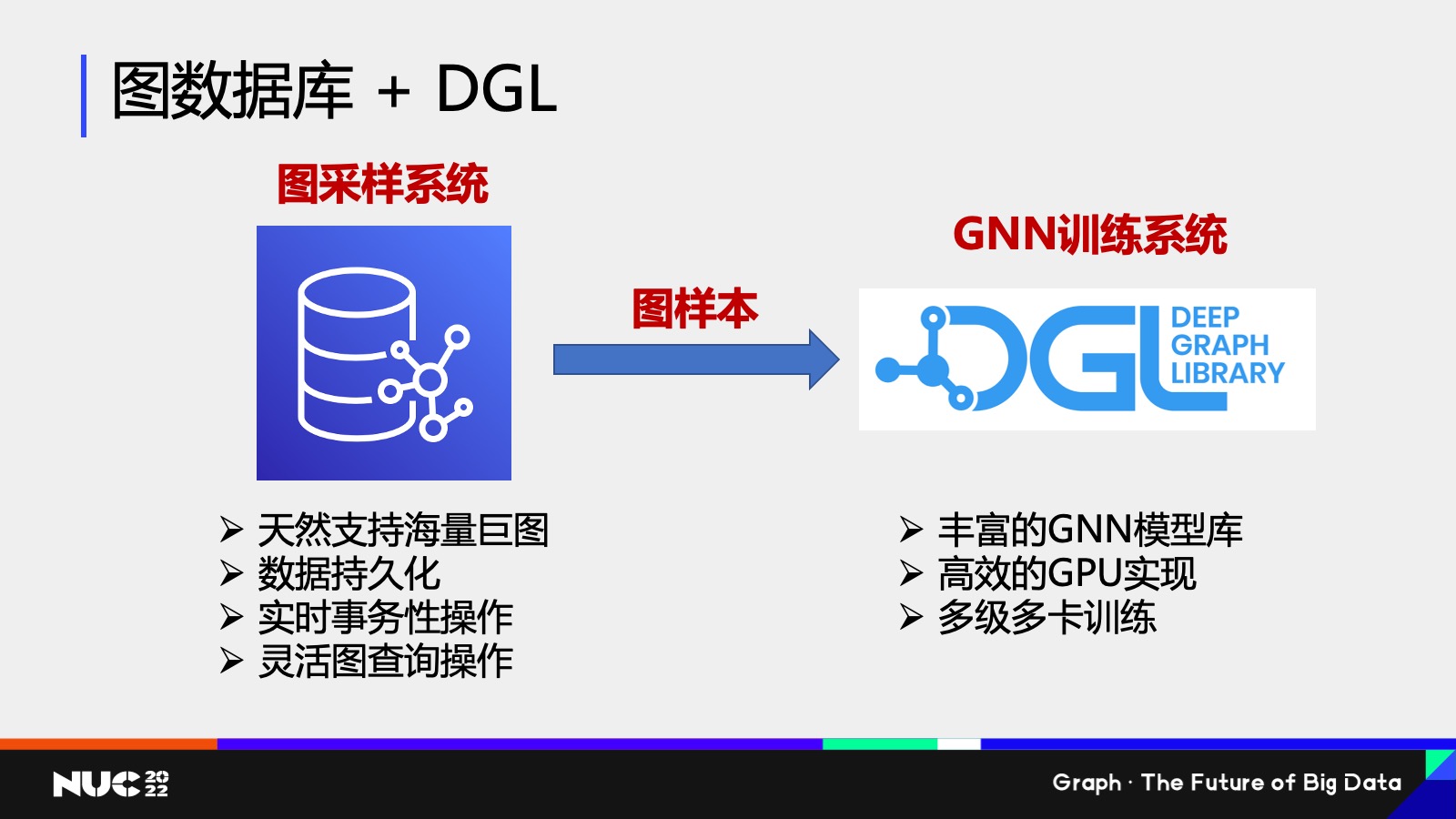
好,这个是在单 GPU 上的训练流程,如果说我们图更大对吧?我可能一个机器的内存都存不下,我该怎么办对吧?其实一个很自然的想法,就是说我们能不能通过一些已有的 infrastructure 来解决这个问题,这个当中最重要的一个 infrastructure 之一就是这个图数据库了,那图数据库有哪些特性呢?
首先我们可以看图数据库它是天然支持海量巨图的,对吧?图不论多大,我可以分布式存储。同时图数据库另外几个好处,比如说可以支持数据持久化,可以支持实时的事务性操作,包括灵活的图查询语言,为什么灵活的图查询语言非常重要?因为其实大家可以想我采样的过程,我给定一个节点,我去拿到这个节点的这样的一个周围的邻居过程,其实是完全就等价于说我在图做了一个查询操作。
Ok,其实可以看到图数据库包含这些很好的一些性质。我们刚刚也提到 DGL 有丰富的 GNN 的模型库,然后我们有高效的 GPU 的实现,我们也可以实现多机多卡的这样一个训练。
自然而然我们可以思考说能不能把它们结合起来,结合起来的一个想法也非常简单,就是我刚刚提到的我把图数据库作为我们这个图采样系统,因为它支持图查询语言它可以作为采样的一个部分,对吧?而且它可以支持海量的巨图,然后我把图样本从图数据库当中抽取出来之后,交给 DGL 只要作为 GNN 训练系统进行操作——所以这个就是一套整套的一个新的这样的一个 design。
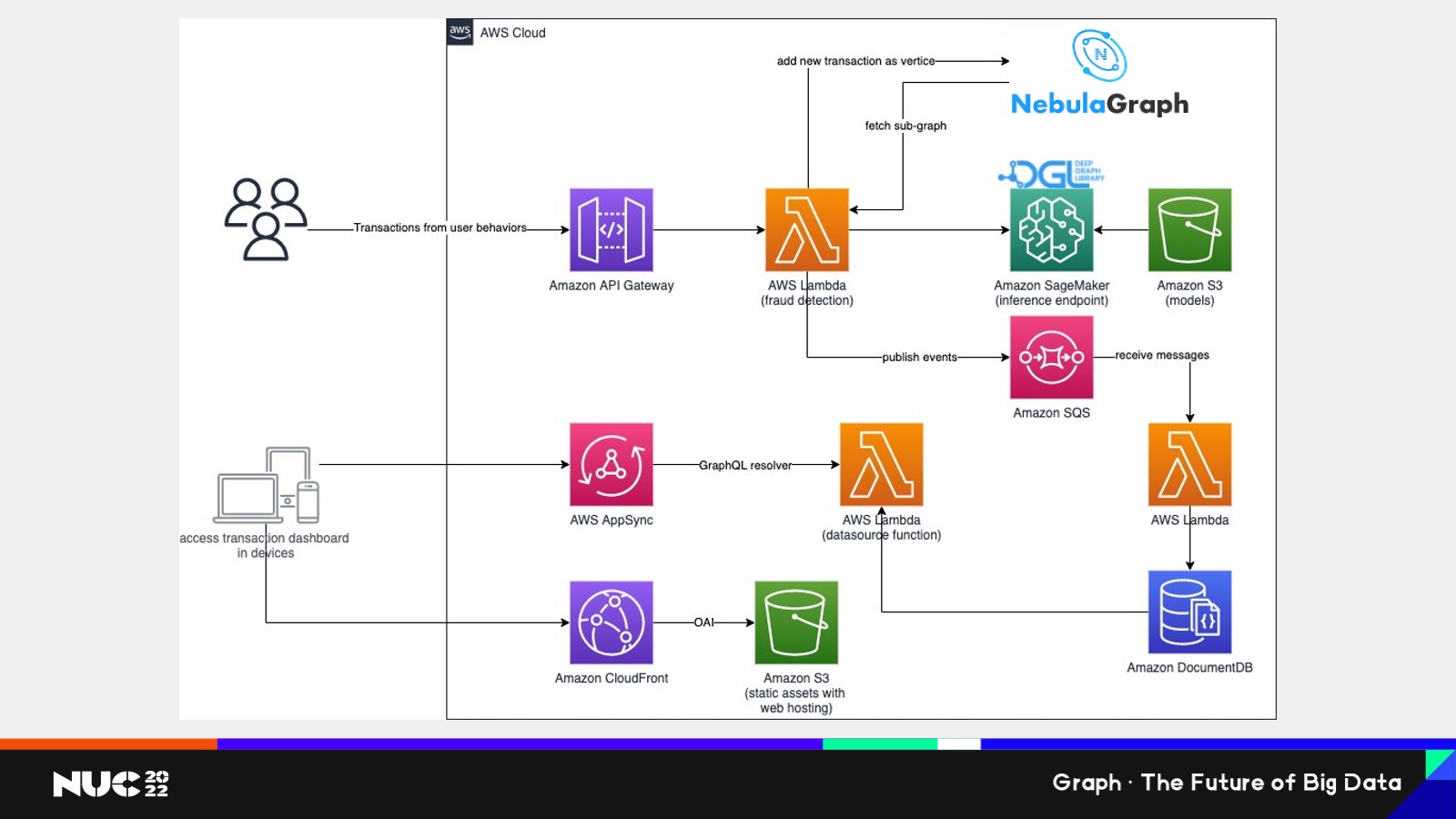
这边其实我们也是给我们客户做的一个案例,这个案例也是非常有幸地使用到了 NebulaGraph 的技术。这是在我们的 AWS 云上所做的这样的一个 architecture,可以看到整个过程当中,核心就是说你可以看到 NebulaGraph 所做的事情,就是一旦这个节点它是一个实时系统,就说我这个图就算在整个运行过程当中有新的节点,新的边加进来,它也是可以满足需求的。
因为 NebulaGraph 是有实时的事务性操作的功能,在这边其实 NebulaGraph 所起的作用就是一个图采样系统。我们通过 graph database 拿到 sub-graph,也就是我们说的子图,获得子图之后,我们再交给 DGL,我们 DGL 是部署在 Amazon 的 SageMaker 这样的一个 end point上,然后通过 DGL 的计算,我们可以获得这样的一个更高效的这样一个训练效果。
DGL 在编译和分布式的最新研究成果
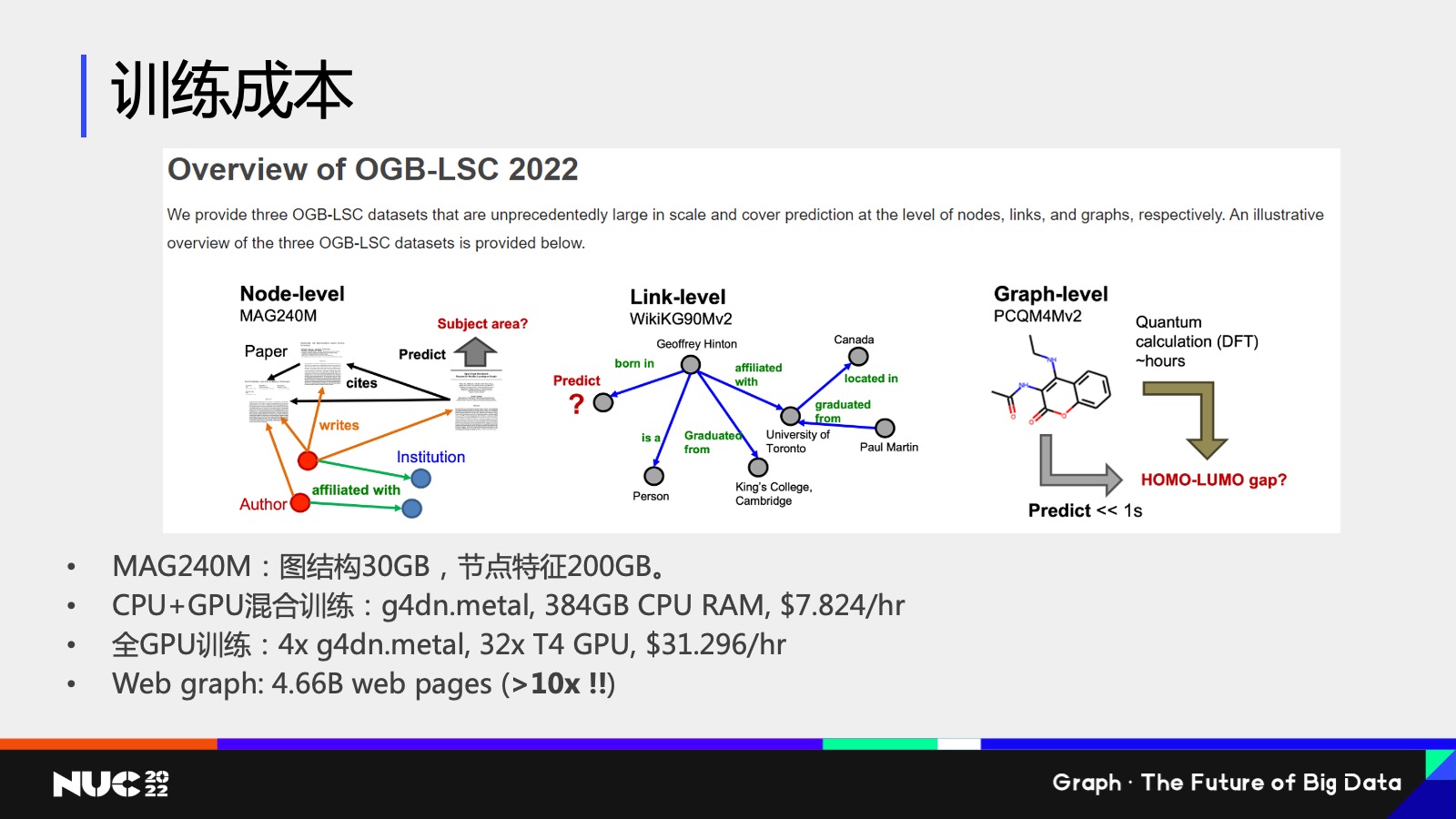
接下来我也想说一下训练成本的这样一个问题,因为其实刚刚我记得之前嘉宾也提到说训练非常慢,其实不仅仅慢也很贵。
我现在这边做一个简单的例子,我使用的一个数据叫做是 OGB 里边的一个数据叫做 MAG240M,然后它这个数据规模有多大?我刚刚提过了,它其实有 240 million 这样的一个节点,所以它的图结构数据大概是 30GB,节点特征大概是 200GB 左右这样一个量级。
如果使用 CPU 加 GPU 的混合训练,我需要把这些数据全部放在 CPU 上,所以需要一台这样的机器——这个机器在 AWS 上大家可以查到它的价格大概是 8 美元一小时,ok,有人说我可能还是比较有钱的对吧,所以我可以用得起这样的一个这样的一个数据这样的机器。如果说我想要用全 GPU 训练,我们把它的速度再 push 到一个limit,对吧?我想要更快怎么办?我需要很多的 GPU 它的总的容量,GPU 内存总容量能够放下所有的就是图结构包括特征结构,这个时候我就需要 4 台这样的机器,你的价格就已经上升很多了,对吧?
同时我们要考虑就是说这个图本身还不是最大的,事实上如果我们去考虑 Internet,我们整个互联网对吧?互联网我们认为它是个图,它的整个链接关系都可以认为是连接关系,这个图的大小是 MAG240 的 10 倍以上,我们可以想象我们的训练成本有多贵,对吧?
所以训练成本其实是图神经网络现在大规模图神经网络训练上的一个很严重的问题。
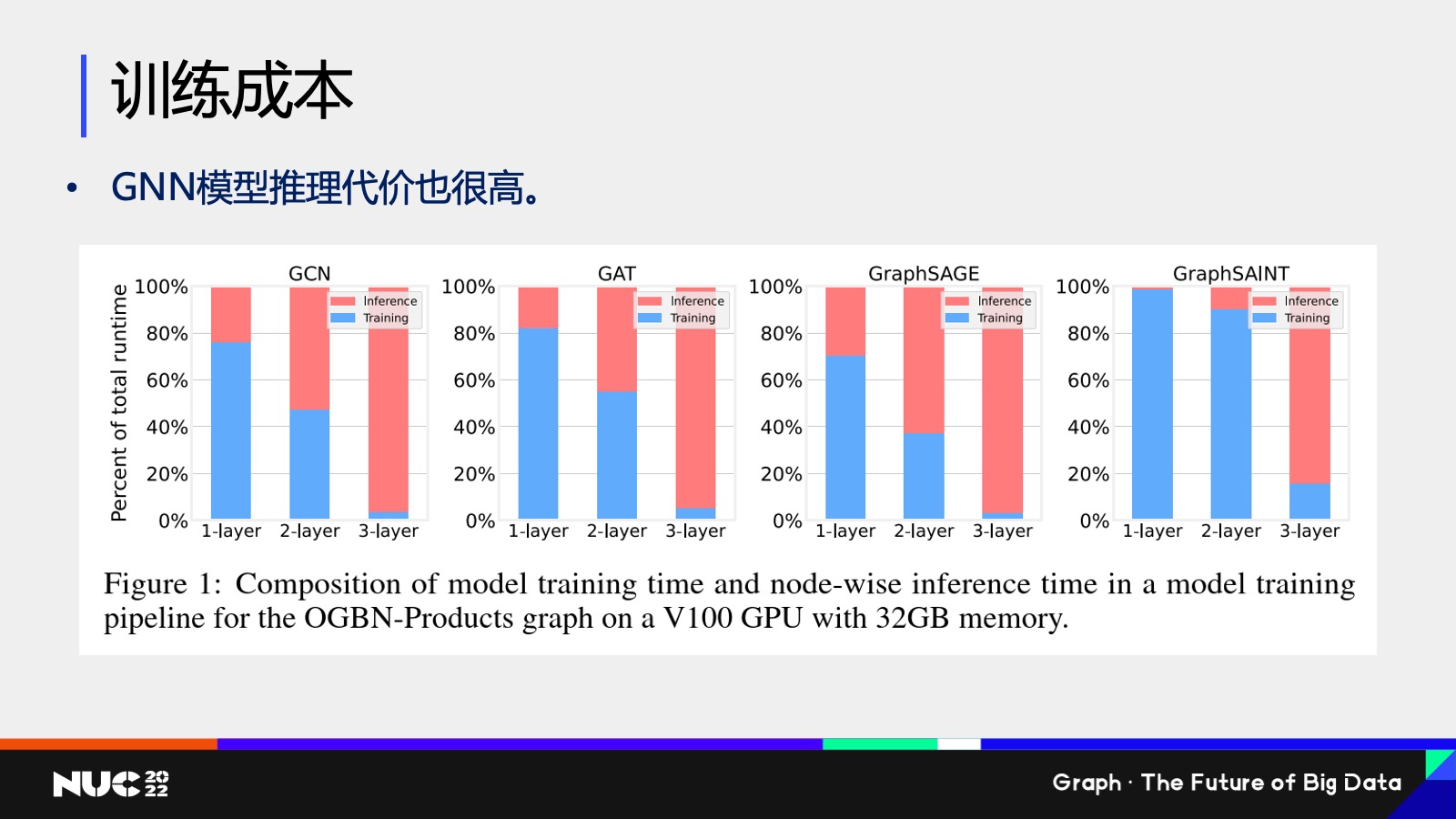
然后这边训练成本不仅仅包含的是我们说的训练,其实还有一点是可能大家没有太大关注的,就是它的推理性能也是代价很高的。这边我们做了一个 benchmark,就说是推理,就说我在训练过程当中我还要做推理来验证说我这个模型到底有没有训练对,对吧?
我们可以发现就是说这边我们测试像GCN、GAT、GraphSAGE、GraphSAINT 不同的这些模型,这边红色的代表是它的推理占比时间,而 training 代表训练占比的时间,然后不同的柱代表的是不同的数目的层数。
可以看到就是说当比如说这个模型达到三层,三层其实也不是很深对吧?三层的时候它的整个推理要占比的要占到 90% 以上的时间。所以可以看到整个训练过程,整个耗时当中推理都是一个非常严重的问题。
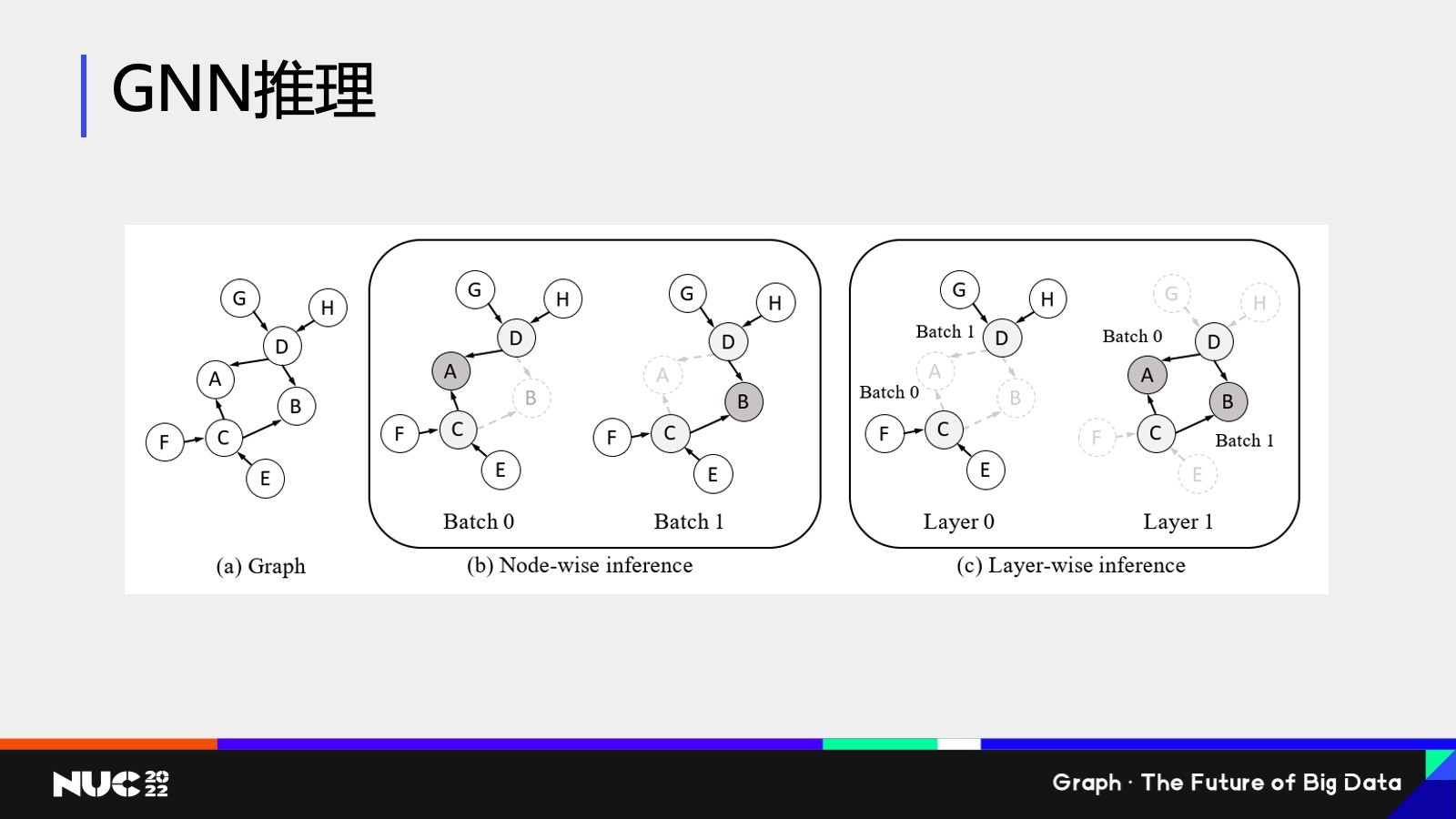
当然解决问题肯定要一步步做,所以我们看到这个问题,我们先对推理的问题做了一定的优化。我们所采取的一个思路叫做叫 Layer-wise influnce,按层的这样一个推理的范式。什么意思?就是我们发现为什么刚刚我们看到这个推理性能那么的慢,原因是因为传统的推理性能都是基于 b这样的一种做法,就是 Node-wise inference。
Node-wise influence 的做法比如我要 influence A 这个节点的结果,我怎么做?根据图神经网络的做法,我要去看他所有的邻居以及邻居的邻居的消息,对吧?所以对 A 来说我要计算它周围所有的节点 。接下来我走到下一个 batch,我要去算 B 的时候,很不幸它正好 share 所有 A 的neighbor,这个时候其实我就全部重新算了一遍,这个当中就有很多的计算冗余,这就是为什么之前我们看到计算那么慢的一个主要的原因。
因此我们的解决方案就是把这样的计算方式换成了 Layer-wise 的计算方式,也就是说我并不是先计算 A 和 B ,而是先计算它的二度邻居的 inbeding,比如说 C 和 D。通过这样的方式,每个节点都只需要计算一次,这就是为什么 Layer-wisa 要比它快很多。
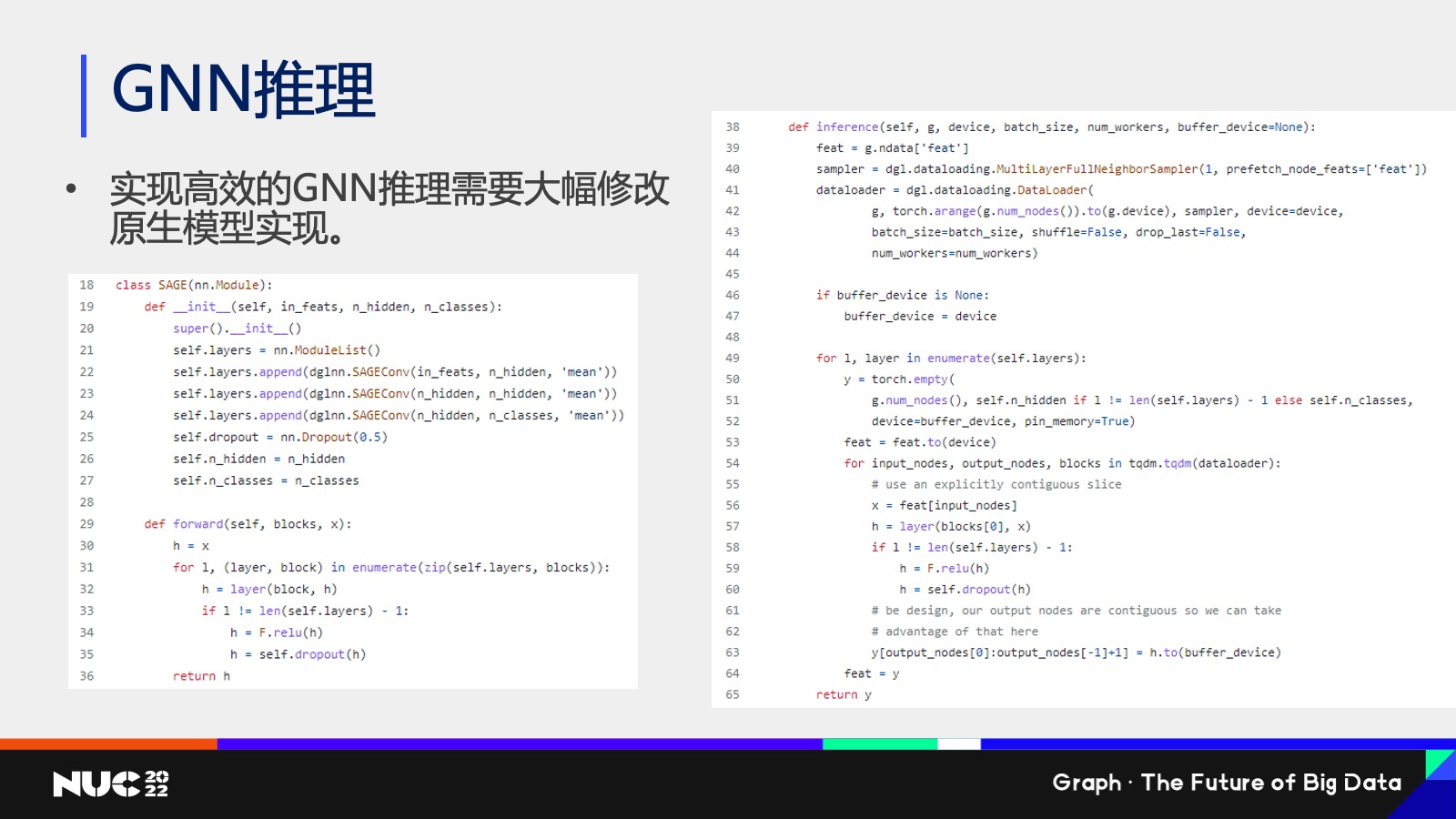
当然 Layer-wise 也有它的问题,比如说我写了一个 Graph SAGE ,它是有三层的模型,每一层是一个 sage com 的一个 layer,当我把它变成一个 Layer-wise 的计算的时候,它的整个代码就看不懂了。因为Layer-wise 它其实是 break了我们的整个在计算的过程当中一个计算的逻辑,然后用户必须对所有的模型都要重写一份代码。
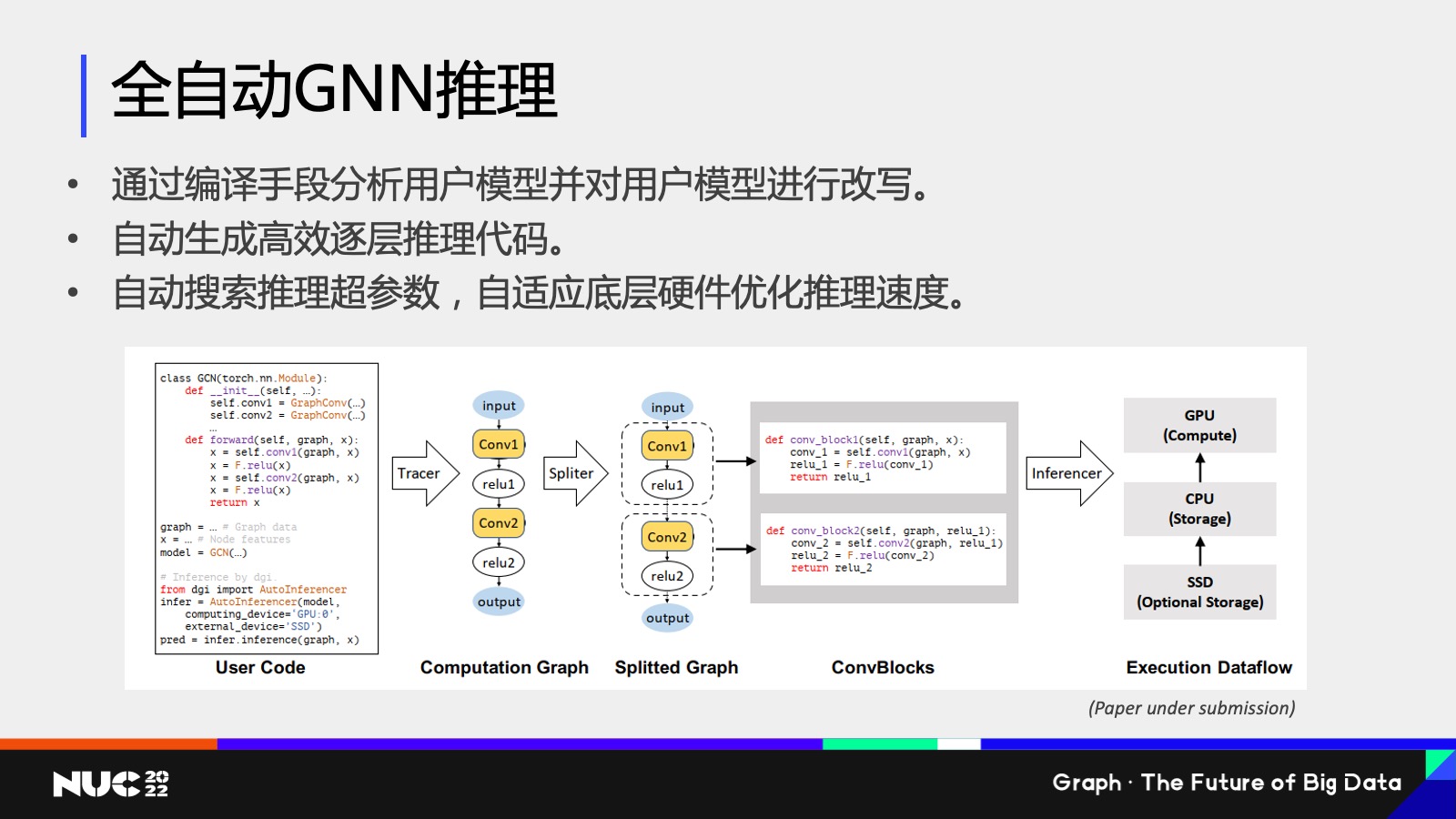
通过这个方式,其实我们做了一个研究工作,就叫做全自动的 GNN 推理。利用了刚刚我们提到的逐层 Layer-wise 推理的方式,同时为了解决我刚刚提到的用户编写代码困难,所以我们又设计了一个编译的框架,通过分析编译用户的代码,然后把它给自动地变成我们刚刚看到的 Layer-wise 这样的一个推理的一个代码,然后达到一个比较高效的推理速度。

最后做一些总结,今天我的分享主要介绍了一下 DGL 的一些关键的技术特点和开源社区的一些介绍。之后其实我也讲了,包括像易用性、高性能、大规模图方面,其实它是有很多挑战的,因为图神经网络它作为一个比较新的这样的一个领域,还是有很多比较热的研究问题,也是我们研究院攻坚的方向,同时我也介绍了一些我们在编译和分布式领域的一些最新的研究成果。所以如果同学们有兴趣,可以一起来投入到这样的领域当中。
最后简单打个广告,希望大家使用并贡献 DGL 大家可以访问我们的网站,访问我们 GitHub 的页面,也可以关注我们的知乎的专栏,我们会定期做很多的关于图神经网络的一些分享。
Ok,谢谢大家。
NUC 2022 往期精彩内容回顾:
交流图数据库技术?加入 Nebula 交流群请先填写下你的 Nebula 名片,Nebula 小助手会拉你进群~~