
行业科普NUC2022
聊一聊图数据库应用的现状和 NebulaGraph 未来发展|NUC 2022
本文整理自 NebulaGraph 创始人兼 CEO 叶小萌在 NUC 2022 上的分享,欢迎关注 NebulaGraph 官网博客专栏查看更多 资讯 · 干货 · 案例 分享。

欢迎,今天到场的各位嘉宾。
去年的 NUC 大会我大概介绍了一下图数据库的发展历程以及 NebulaGraph 的产品情况,今年大会的主题是 The future of the big data——大数据的未来,所以想花十几分钟时间分享下我这段时间在图数据库未来方向上的一些想法。
图数据库现状:增长势头不减,新老行业各有突破
今天报名的观众大多数都是 NebulaGraph 的用户,大家应该差不多都是在这两三年,最多三四年里开始接触和使用图数据库的,其实整个国内基本也是这样一个趋势。国内的投资机构、图数据库新兴企业,基本上也是在过去三四年的时间里,像雨后春笋一样兴起的。
这几年, NebulaGraph 的实名用户增长速度也非常快。这里可以分享个数据——从 2021 年的第一季度到目前,NebulaGraph 整个的实名用户的差不多是 6 倍多的增长。这不光说明了大家对我们产品的认可,也反映了图数据库市场正在走向成熟。
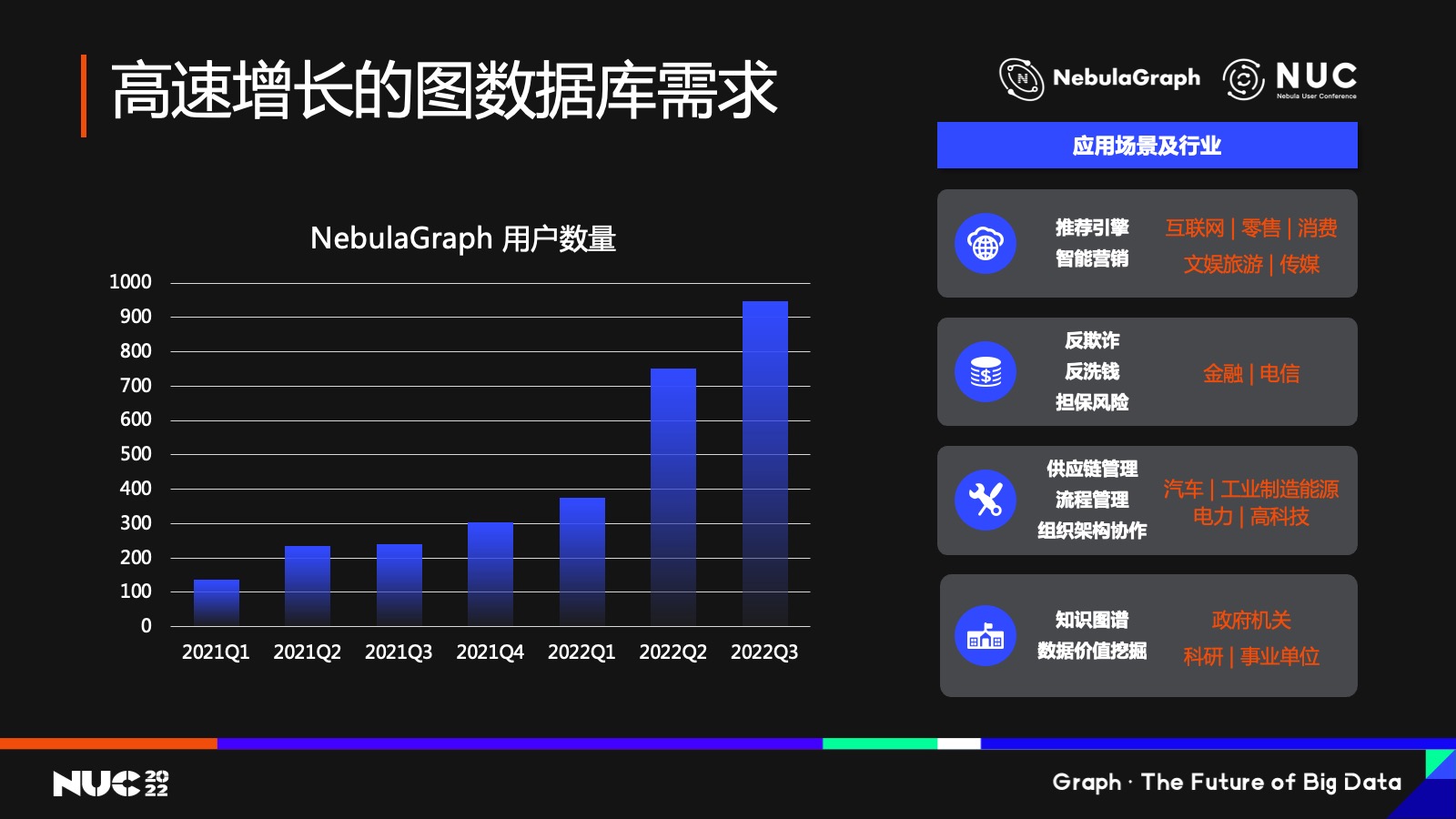
与此同时,越来越多商业化用户需求在不断冒出来。右边就是我们观察到的,目前图数据库需求比较旺盛的领域。
从最早的互联网企业的社交图谱应用,发展到推荐、风控等领域。然后就是金融行业,包括银行、证券、期货、保险等企业,我们把电信运营商也包含了在这里面。这些企业对图数据库的需求也是差不多在过去的 3-4 年逐渐起来的,而且逐渐变得成熟,我们看到图数据库的需求进入正逐渐进入这些企业的业务主链路,应用在比如反欺诈、反洗钱、反骗保、投研分析等等领域。
第三个领域其实非常有意思,是高端制造。从去年开始我们接触很多这个领域的用户,在这里有汽车制造,有高端电子产品制造等等,我们把电力能源部门也归在了这一类里面。这一类企业对图数据库的需求来自于,例如供应链的管理,生产流程管理,产品维修管理,用户管理等等一整套的流程管理,所以说增长速度还是非常快的。
那么大家可能会问,供应链管理这个话题已经比较老了,我记得最早是在上个世纪 90年代出现的,也就差不多 20 多年前出现了,为什么现在又有?其实之前的供应链管理可能比较简单,就是管理供应商——他们提供了哪些批次、哪些原材料,那么这种管理的数据量其实很小。现在随着技术的不断前进,供应链管理的重心开始发生变化,或者说从供应端开始转向了消费端。
举个例子,比如汽车制造,原来只是关心谁提供了轮胎,谁提供了引擎等等这样一些部件,这个数据量其实不多;但如果需要追踪每一辆汽车上、每一个零部件是由哪个厂家提供的呢?大家知道一辆汽车可能有几万甚至十几万零部件,那么大一点的汽车制造厂,一个月就可以生产十几万辆汽车对吧?如果说我们把每一辆汽车上的零部件,乘以一年生产的汽车总数量,如果追踪到这样细的粒度的话,这个数据量就非常惊人了。所以说我们看到业务的发展,正从原来的供应端开始向消费端在迁移,过程当中数据量暴增,这个时候就产生了对图数据库的一个必然的需求。
第四个领域是知识图谱。几十年前大家可能已经知道有知识图谱,但原来只支持一跳两跳的关系查询,现在会走得更深。比如做一些复杂的逻辑推理的时候,可能是需要往下走十几步。原来知识图谱的数据可能是存储在传统的关数据库里,但是随着数据量变大以及对关系查询复杂度变高,传统的关系型数据库就搞不定了——在这种情况下,大家对图数据库的依赖就越来越强。
除此之外,我们还看到了图数据库在新药研发、芯片设计、甚至 Web3 、数字货币、元宇宙等一些新兴领域的应用开始出现。所以说,为什么我们说未来已来?因为这些技术其实都代表着未来,可能在未来三五年甚至十年出现的技术中,图技术都有它的应用场景。
聊聊 NebulaGraph 未来发展的两个重点
上面大家已经看到,图数据库行业整个的发展非常快,那么在未来的 3-5 年时间里面,哪几样东西对图数据库的影响会比较大呢?我也分享下我的看法。
1. 推动图数据库行业标准化
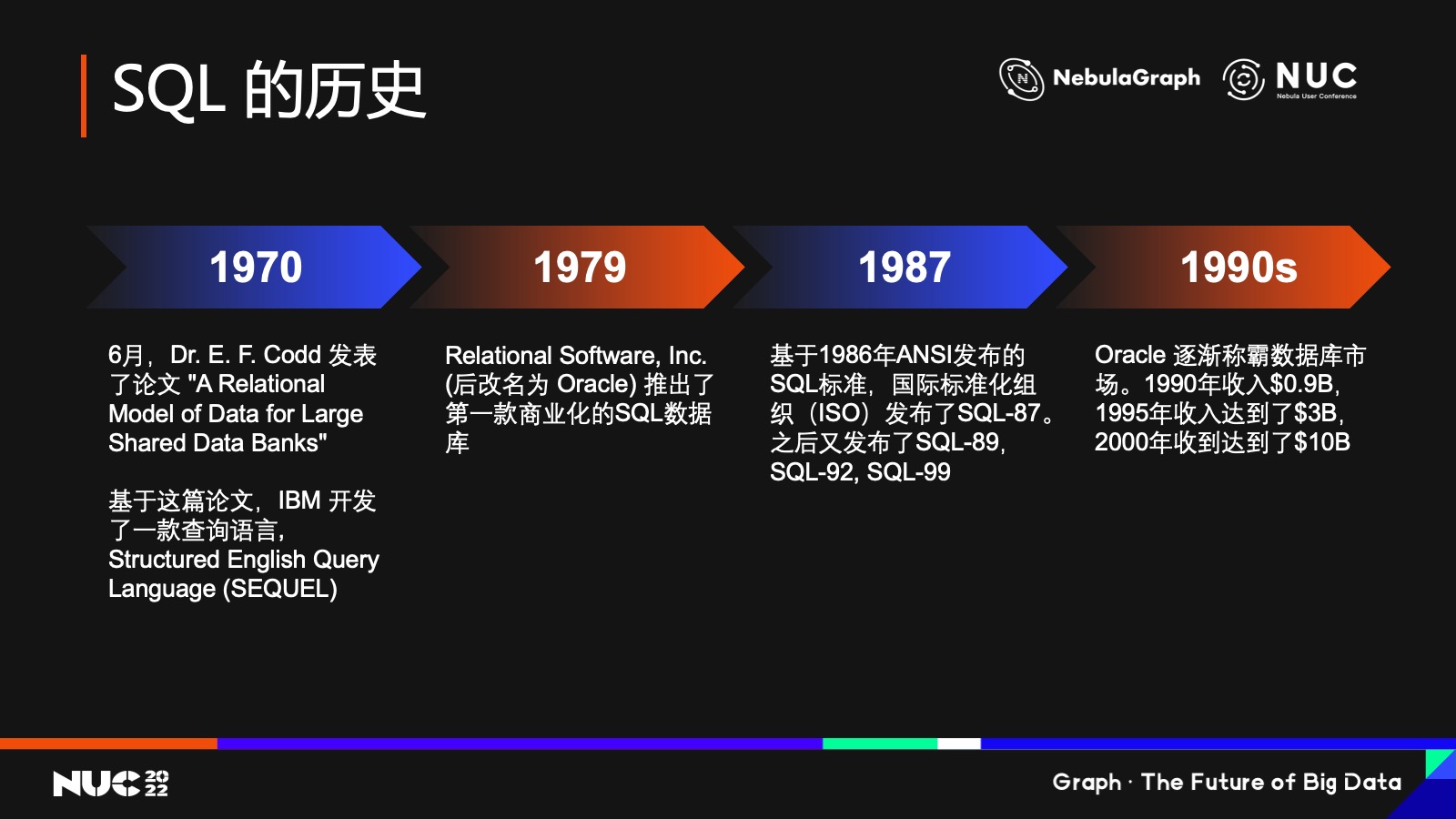
历史总是重复上演,所以我们不妨先回顾一下关系型数据库的标准查询语言 SQL 的历史——
1970年,Dr. E. F. Codd 博士发表了《A Relational Model of Data for Large Shared Data Banks》这篇论文,原来他们还不叫 Database,因为没有 Database,当时他们称为 “Data Banks”,其实就是现在的数据库。论文里介绍了他们在大型数据库里的一个关系模型,这就奠定了后来关系代数的基础。
基于这篇论文, IBM 开发了一个查询语言 —— 全称叫 Structured English Query Language ,取首字母就是 SEQUEL。到了几年后,大概 在 79 年之前,他们觉得SEQUEL 这个名字太长了,逐渐就把这个名字改成了 SQL,但发音还是一样的。
这就是我们大家非常熟悉的,而且是目前整个数据业界唯一一个标准查询语言 SQL 的来历。79 年时,一家叫 Relational Software 的公司推出了第一款基于 SQL 的商业化数据库;但大家知道这个时候 SQL 其实还没有成为行业标准,只是 IBM 推出的一个查询语言而已。而这家名叫 Relational Software 的公司,相信很多人都没有听过,就已经推出了基于 SQL 的数据库。但后来这家公司改了个名——Oracle,这个名字相信在座的各位就都听说过了,对吧,就是后来的甲骨文公司。
关系型数据库 在 80 年代的发展其实还是很慢的,到了 87 年,SQL 被 ANSI(美国国家标准局)接受为一个标准,有的人把它称为 SQL-86,但这只是美国的一个标准,因为 ANSI 是美国的标准化组织;所以后来他们又通过国际标准化组织,就是 ISO,在 87 年时接纳了基于 ANSI 86 的标准,推出了 87 年的 SQL 标准,业界把它称为SQL-87。当然后续它还推出了很多版本,包括 89 年、92 年,到现在最新的,大家比较熟悉的 99 年版本。
那么,推出查询语言标准的好处是什么?
第一个,各大院校开始开设数据库这门课程了,因为他们可以用统一的标准来教授 SQL;第二从企业界来看,因为这有这样一个标准,所以很多数据库如雨后春笋一样冒出来,大家都来支持 SQL。
那么刚刚说到的 Relational Software,就是后来的 Oracle,它是其中最大的受益者。因为这个标准的推出使得业界对数据库的接受程度非常快。我们查了几个数据, Oracle是 86 年上市的公司,他们在 90 年的时候,全球总收入是 10 亿美金不到,到了 95 年就已经达到了 30 亿美金,2000 年的时候就已经达到了 100 亿美金,10 年间有差不多10倍的增长,作为一个数据库企业可以说是非常快了,当然这背后有很多原因,但其中一个很大的原因,我们认为是来自于这个标准。
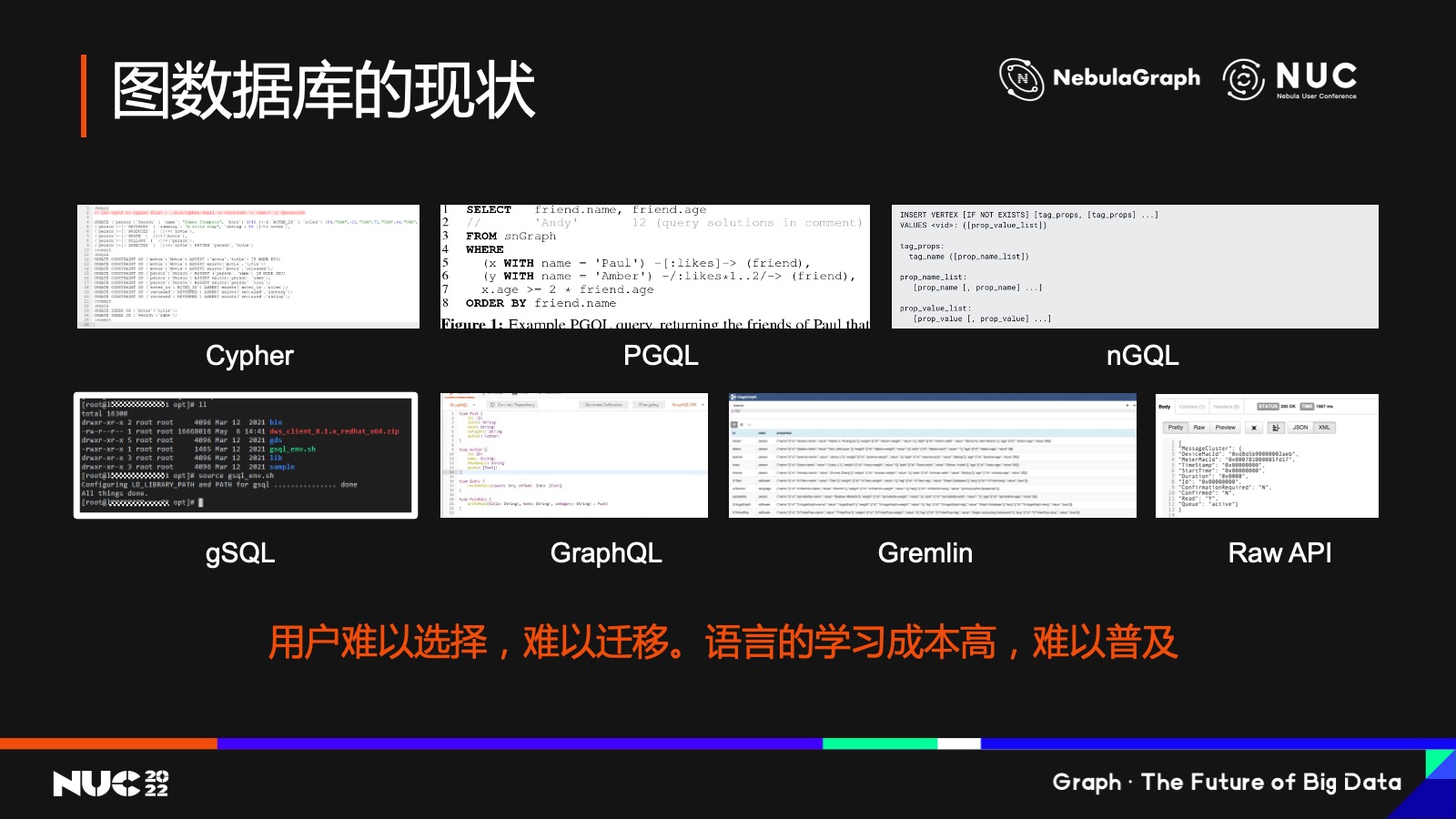
再回过头来看一下图数据库的现状。
现在的图数据库领域是一个比较分散的状态,光 query language 就有很多种,当然其中比较有名的或者说用户量比较大的是 Cypher,这个大家知道是 neo4j 的查询语言。然后还有 PGQL、以及 NebulaGraph 推出的 nGQL,我们也列在这里了。其他的还有 gSQL、GraphQL、Gremlin 等等。甚至还有一些图数据库,号称支持某些语言,但其实他们提供只是一个查询的API,用户要自己去调用 API 来取数据去实现一些算法。
那么所有这些带给用户的是什么?一个是选择成本,另外一个就是迁移成本,从研发的角度来看,各式各样的语言学习成本也非常高,所以造成了图数据库的普及非常难。

比较幸运的是,几年前,业界或者说国际标准化组织也看到了这样一个问题,所以大概在差不多 3-4 年前,就在我刚刚说的图数据库高速发展这几年,包括 Oracle、Neo4j 在内的一些公司,就组成了这样一个 workgroup,这个组织是在标准化组织ISO-IECJTC1-SC32-WG3 下面的,目的就是希望推出一个图数据库查询语言(Graph-Query-Language,简称 GQL)的标准。
当然整个标准的制定和推进是一个相当漫长的过程,那么到现在的话,基本上这个标准已经接近最终的版本了。具体内容这里就不展开说了,大概就是一个比较完善的查询语言,包括数据定义、数据查询、数据操作等等,而最关键的是,它跟 SQL 是一个姊妹篇,就是说跟我们刚才介绍的 SQL 有非常好的结合。这个工作组把 GQL 里面的很重要的一部分 patttern matching,我们说的图的路径的模式匹配这样一部分抽出来,把这部分作为 SQL的一个 extension,就是把它作为SQL的一个扩展包,并制定了一个新的标准,就是对 SQL 的拓展。我们很高兴地看到,这个标准基本上已经被 SQL 的工作组接受了,那么这个东西其实也是 GQL 的核心,从一开始 GQL 和 SQL 之间就是一个紧密结合的关系。
统一图查询语言 GQL 为什么这么重要?
可以看到 GQL 是整个数据领域的第二个查询语言标准。数据库大家都知道,经过几十年的发展,数据库的种类已经是非常多了,对吧?数据库的种类少说十、二十种肯定是有的,大家比较熟悉的可能有比如像时序数据库、文档数据库等等,但这些数据库都没有自己的语言,要么就用 SQL,要么有一些自己的、各式各样的一些查询语言,但都没有这样另外制定一个标准——只有图数据库,现在国际标准化组织认识到了它的重要性,所以要制定这样一个图查询语言的标准。这个标准可能是在明年年底或者后年年初会正式对外发布,一旦发布之后,它对投资客户就像前面 SQL 在 80 年代后期推出标准一样,会对整个行业带来一个巨大的推动作用。
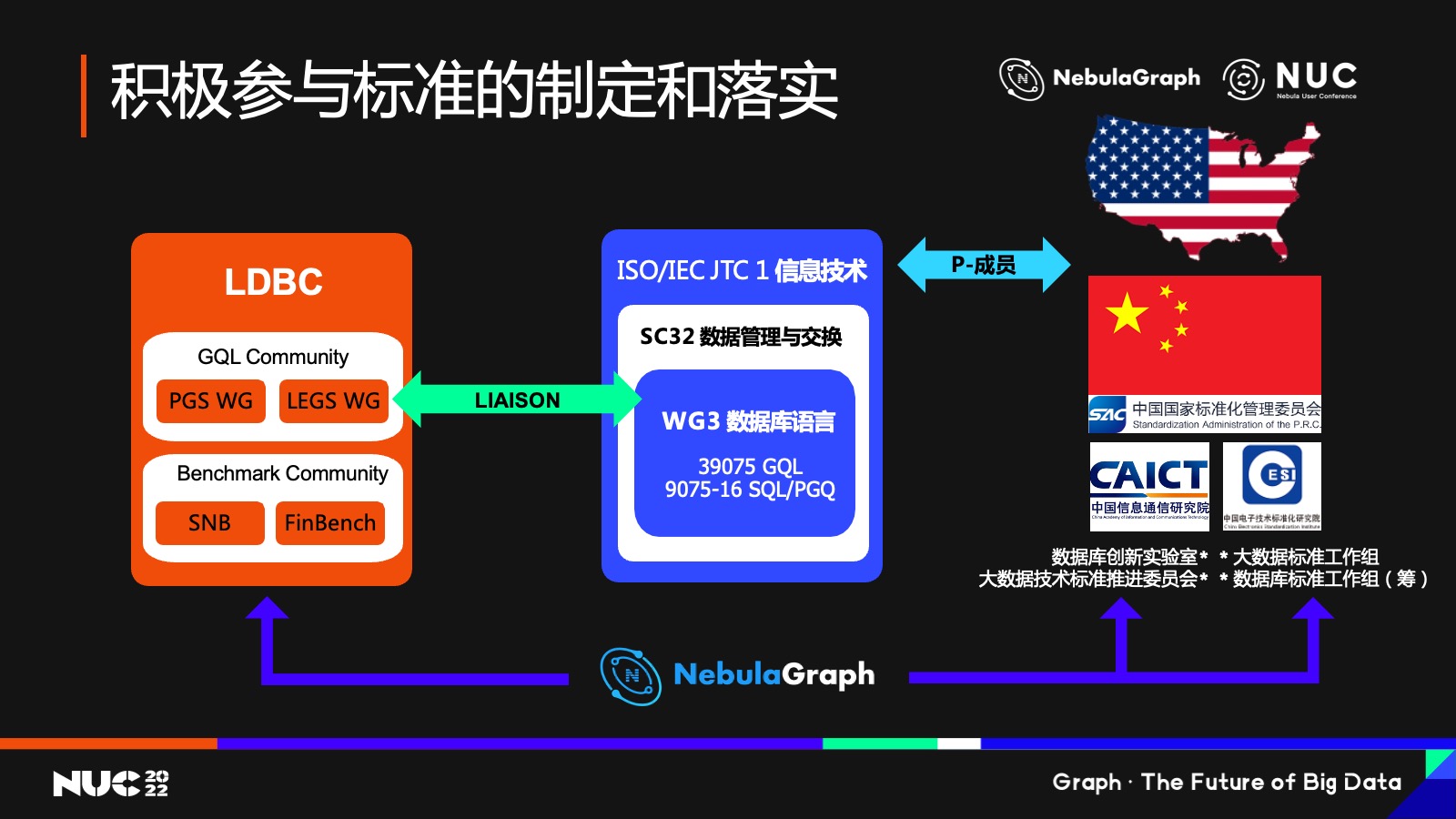
再讲一下 NebulaGraph 在制定标准中的参与和推动作用。
我们作为图数据库公司,主要通过这样的两个不同的途径——一是是通过国际化组织,大家都知道的 ISO,它的成员基本都是国家,并不是公司本身,我们在国内主要就是通过 ISO 在国内的代表电子四所,通过他们积极参与到 GQL 的制定当中,是目前的一条路径。
第二条路径的话是通过另外一个组织叫 LDBC,这个大家可能会比较熟悉。LDBC 是12 年左右由 Facebook 的一个实习生做出来的。当时 Facebook 做关系图谱,社交图谱怎么查询、怎么来判断图数据库或图查询效率?这位实习生就想来做一个 Benchmark,后来就变成了 LDBC。现在 LDBC 也是一个很重要的组织,它跟 GQL的工作组有非常紧密的结合联系,而 NebulaGraph 现在也是 LDBC 的成员之一,也会通过我们在 LDBC 里面的影响力去影响这个标准。
2. 把握图数据库的主要应用场景
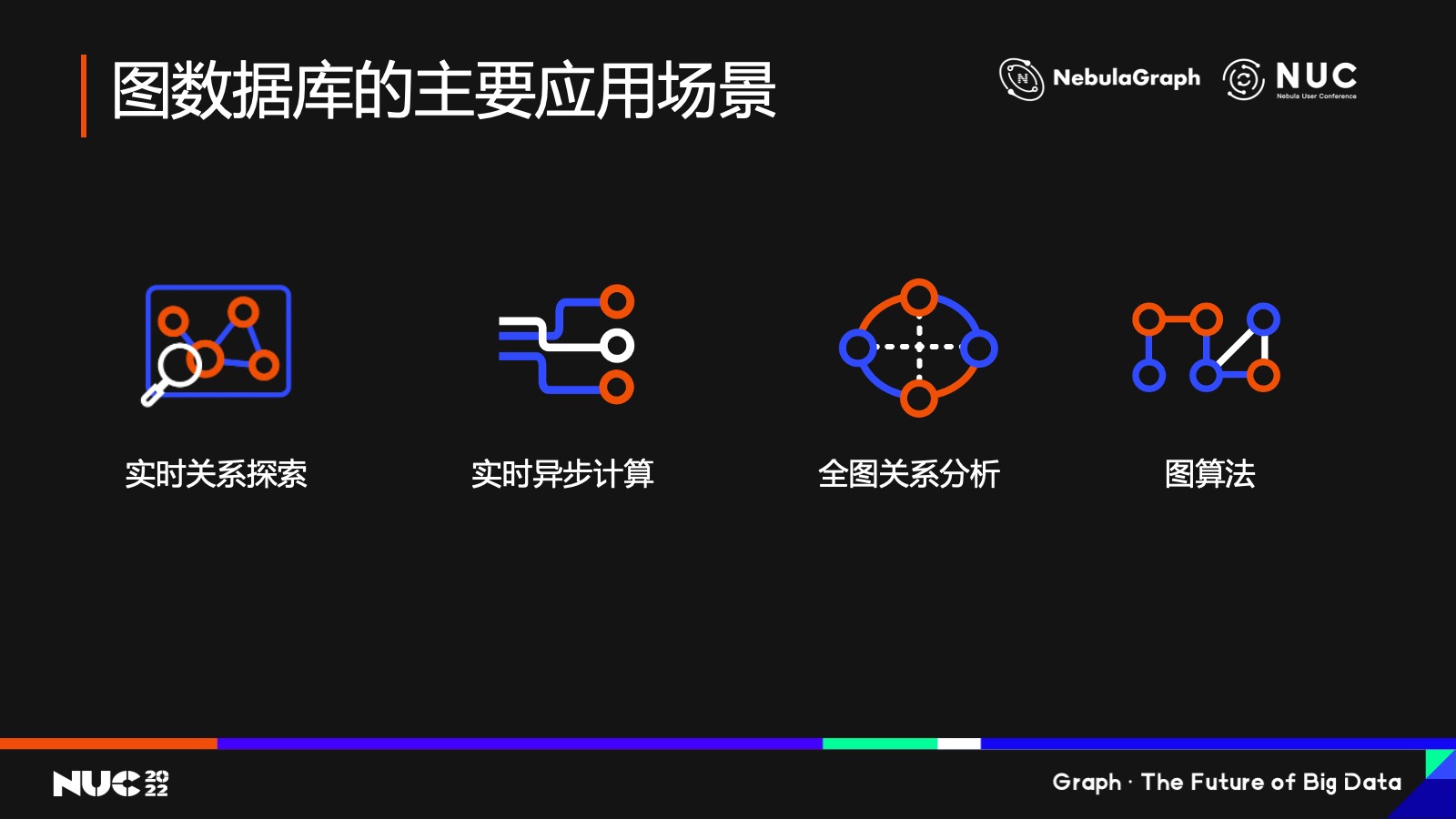
除了标准之外,我们再聊一聊图数据库未来的应用场景。
我认为图数据库更多的应用是在时效性。为什么这么说?大家可以看到目前图数据库主要的应用场景,从技术角度来区分,可以分成四类。第一类是实时关系探索,第二类是实时的异步计算,就是从实施的业务实时的 query 里面分出来的异步计算的这样一个分支,它不会影响业务的实时性,但是有它在整个数据计算的时效性会比较高。第三个的话就是全图分析,这个就是我们所理解的 AP,就是事后分析。第四个是图算法,这也是图和其他大数据不一样一个地方,因为图上面有很多算法,比如说社群发现、最短路径等等这样一些算法,那么这个算法也是基于全图计算的。
在这四类应用里我们可以看到,前两类比较偏 TP,也就是说我们说的 online service 或者说在线服务;后两类偏 AP 一些,也就是事后分析。

我认为相对于 TP,事后分析的场景更多是解决用户的痒点,而不是痛点。
为什么这么说呢?首先在事后计算时,图计算框架不是不可替代的。大家知道图的计算框架有很多,最早的从谷歌的 Pregel 到后来的比如 GraphX,还有很多这样一些离线的图计算框架,它可以做图分析的一些算法,但这个东西并不是不可替代的,我们用传统的大数据系统也可以做同样的事情。
比如说阿里,原来阿里比较有名的一个,基于 MapReduce 的一个大数据计算框架叫ODPS ,在 ODPS 上他们也做了一个图的计算框架对吧?但是它是基于 ODPS 这个 MapReduce 算法来做的,所以说可以看到包括 Graphx,本身其实也不是一个纯粹的图计算的框架,它也是基于下面的基于流式计算 Spark 来做的对吧?
所以可以看到,图计算框架本身所做的所有事情,用传统大数据计算框架也都能做,唯一不同的地方是什么?可能不同的地方在于用传统大数据框架来做的话,效率会慢一点。如在右边那张图显示的,用图的计算框架做的话只要 3 个小时,用传统大数据框架来做,可能要 5、6个小时,那么对用户来说,3 小时和 6 个小时的差别有吗?肯定是有,但其实没有那么大。
那么回到刚刚说的 AP ,我们认为,图数据库的实时计算能力可以解决在线业务的痛点问题。大家知道如果是在线的业务中,查询速度如果比较慢的话,它对业务就会产生影响。
举个例子,比如说金融行业的风控,银行转账的风控场景,之前我们的风控都是做事后分析,现在绝大多数的银行或者金融行业用的基于图的分析,是不是有欺诈或洗钱行为基本都是离线分析,所谓离线就是 T+1 去分析今天好像有两笔交易是有欺诈行为的或者有洗钱风险的,这样做的问题是,当你分析出来有风险的时候,其实这个钱已经出去了,转账已经发生了,对吧?资损已经发生了。
所以说从业务角度来说,他更希望什么?他更希望看到的是在事中,也就是说当这笔交易发生的时候,就能够进行判断,如果这笔交易有风险,我就要进行拦截,因为这样对业务的好处就是我能直接减少损失。那么要把它做到能实时的、直接拦截的话,对整个的风控数据查询的性能要求就非常高。
因为大家知道,比如说整个的交易链路,如果我们希望用户转一笔钱的时候,他的体验比较好的话,就需要在比较短的时间,比如说半秒钟或者更短的时间内完成这笔交易。当然,整个链路当中要做很多事情,其中可能有一部分是做风控,给了风控比如 100 毫秒,风控系统必须在 100 毫秒内给我一个结果,说有风险还是没风险。当风控评估超时的时候,系统基本上都是认为这个东西是没有风险,就直接过了。这时问题就来了,如果说你超时或者 100 毫秒内做不了判断的话,对整个的业务带来的风险就越高。那么这样也就是说在图数据库里,如果你要去做一些一跳两跳三跳这种查询的时候,你的延时就必须只能在规定时间内完成,完不成就直接影响到风控动作的完成。
所以,能不能很快地完成查询,其实就是解决了业务的一个痛点问题。当我们效率足够高的时候,就可以赋能业务去做更多的这样一些事情。而当我们能力不强的时候,业务只能依赖于事后分析。
基于以上这两个的判断,我们也可以聊聊 NebulaGraph 未来两年大致的发展。一方面我们会全面支持 ISO GQL,便于快速实现标准化的对接。另一方面 NebulaGraph 也会持续提升查询性能和并发度。作为一个分布式系统,我们还需要有更强的弹性能力,以便能够支持更大的数据量。当然,我们也不会放弃 AP,因为离线分析跟在线分析一起组成了图这块的闭环,所以我们也会去集成更强的计算框架以及图学习框架,打造一站式的图解决方案,敬请各位期待。
那么,以上就是我今天要跟大家分享的内容,谢谢大家。
NUC 2022 往期精彩内容回顾:
交流图数据库技术?加入 Nebula 交流群请先填写下你的 Nebula 名片,Nebula 小助手会拉你进群~~




