特性讲解技术分享
新手阅读 NebulaGraph 源码的姿势

摘要
对于一些刚开始接触 NebulaGraph 开源库的小伙伴来说,刚开始可能和我一样,想要提高自己,看看大神们的代码然后试着能够做点什么,或许能够修复一个看起来并不是那么困难的 Bug。但是面对如此多的代码,我裂开了,不知道如何下手。最后硬着头皮,再看了一遍又一遍代码,跑了一个又一个用例之后终于有点眉目了。
下面就分享下个人学习 NebulaGraph 开源代码的过程,也希望刚接触 NebulaGraph 的小伙伴能够少走弯路,快速入门。另外 NebulaGraph 本身也用到了一些开源库,详情可以见附录。
在本文中,我们将通过数据流快速学习 NebulaGraph,以用户在客户端输入一条 nGQL 语句 SHOW SPACES 为例,使用 GDB 追踪语句输入时 NebulaGraph 是怎么调用和运行的。
在开始本文之前,记得先编译完成 NebulaGraph,具体编译过程参见:使用源码编译
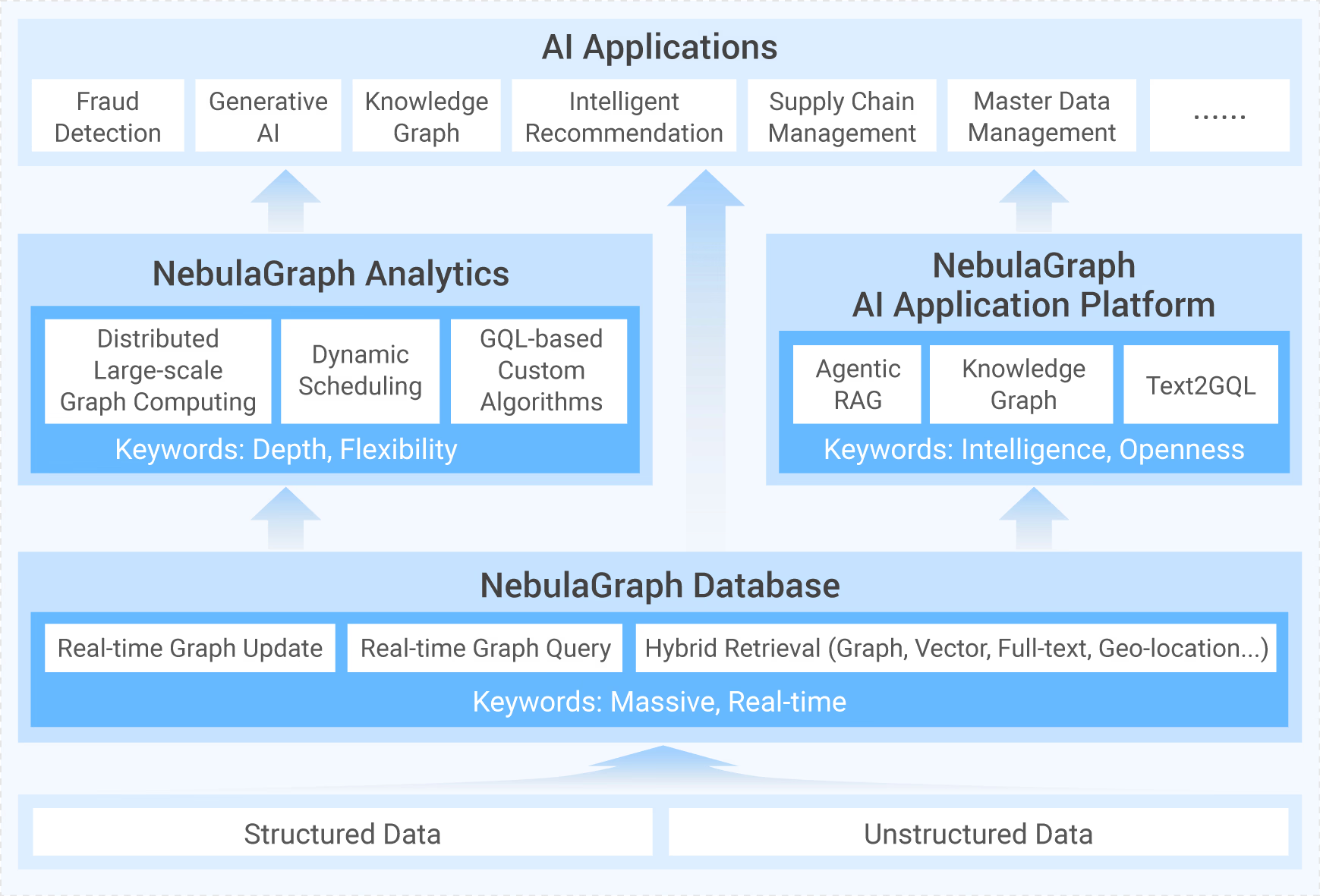
整体架构
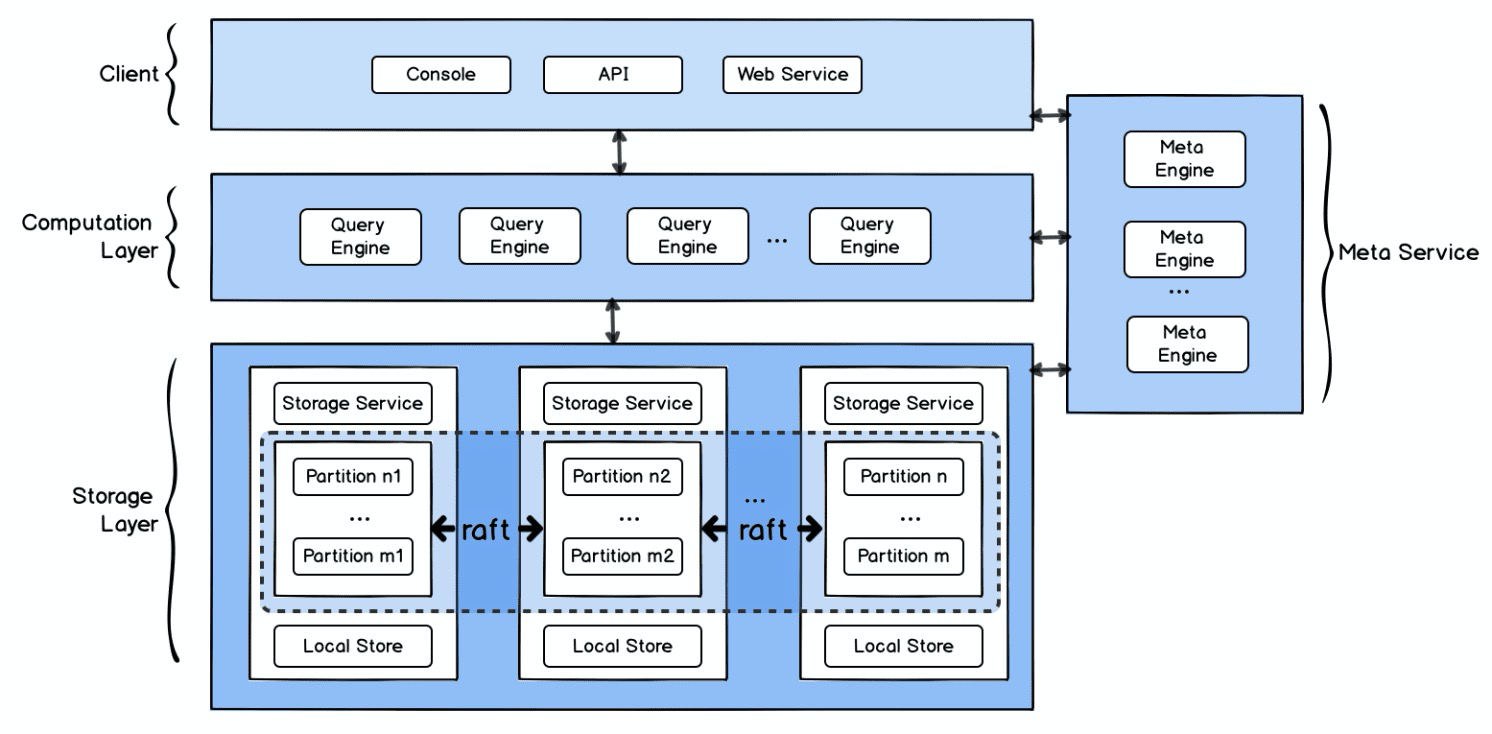
一个完整的 NebulaGraph 包含三个服务,即 Query Service,Storage Service 和 Meta Service。每个服务都有其各自的可执行二进制文件。
Query Service 主要负责
- 客户端连接的管理
- 解析来自客户端的 nGQL 语句为抽象语法树 AST,并将抽象树 AST 解析成一系列执行动作。
- 对执行动作进行优化
- 执行优化后的执行计划
Storage Service 主要负责
- 数据的分布式存储
Meta Service 主要负责
- 图 schema 的增删查改
- 集群的管理
- 用户鉴权
这次,我们主要对 Query Service 进行分析
目录结构
刚开始,可以拿到一个source包,解压,可以先看看代码的层级关系,不同的包主要功能是干什么的 下面只列出src目录:
|--src
|--client // 客户端代码
|--common // 提供一些常用的基础组件
|--console
|--daemons
|--dataman
|--graph // 包含了Query Service的大部分代码
|--interface // 主要是一些 meta、storage 和 graph 的通讯接口定义
|--jni
|--kvstore
|--meta // 元数据管理相关
|--parser // 主要负责词法和语法分析
|--storage // 存储层相关
|--tools
|--webservice
代码跟踪
通过 scripts 目录下的脚本启动 metad 和 storaged 这两个服务:
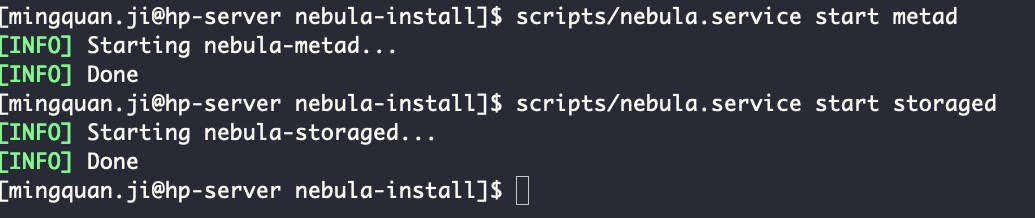
启动后通过 nebula.service status all 查看当前的服务状态

然后 gdb 运行 bin 目录下的 nebula-graphd 二进制程序
gdb> set args --flagfile /home/mingquan.ji/1.0/nebula-install/etc/nebula-graphd.conf //设置函数入参
gdb> set follow-fork-mode child // 由于是守护进程,所以在 fork 子进程后 gdb 继续跟踪子进程
gdb> b main // 在 mian 入口打断点
在 gdb 中输入 run 开始运行 nebula-graphd 程序,然后通过 next 可以一步一步运行,直到遇到 gServer->serve(); // Blocking wait until shut down via gServer->stop(),此时 nebula-graphd 的所有线程阻塞,等待客户端连接,这时需要找到客户端发起请求后由哪个函数处理。
由于 NebulaGraph 使用 FBThrift 来定义生成不同服务的通讯代码,在 src/interface/graph.thrift 文件中可以看到 GraphService 接口的定义如下:
service GraphService {
AuthResponse authenticate(1: string username, 2: string password)
oneway void signout(1: i64 sessionId)
ExecutionResponse execute(1: i64 sessionId, 2: string stmt)
}
在 gServer->serve() 之前有
auto interface = std::make_shared<GraphService>();
status = interface->init(ioThreadPool);
gServer->setInterface(std::move(interface));
gServer->setAddress(localIP, FLAGS_port);
可以知道是由 GraphService 对象来处理客户端的连接和请求,因此可以在 GraphService.cpp:``future_execute 处打断点,以便跟踪后续处理流程。
此时重新打开一个终端进入 nebula 安装目录,通过 ./nebule -u=root -p=nebula 来连接 nebula 服务,再在客户端输入 SHOW SPACES ,此时客户端没有反应,是因为服务端还在阻塞调试中,回到服务端输入 continue,如下所示:
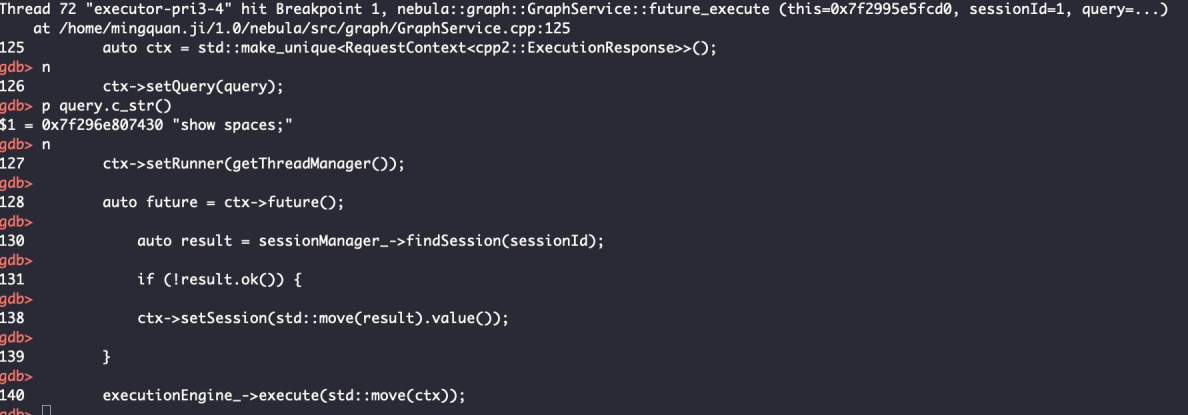
经过 session 验证后,进入 executionEngine->execute() 中,step 进入函数内部
auto plan = new ExecutionPlan(std::move(ectx));
plan->execute();
继续 step 进入ExecutionPlan 的 execute 函数内部,然后执行到
auto result = GQLParser().parse(rctx->query());
parse 这块主要使用 flex & bison,用于词法分析和语法解析构造对象到抽象语法树,其词法文件是 src/parser/scanner.lex,语法文件是 src/parser/parser.yy,其词法分析类似于正则表达式,语法分析举例如下:
go_sentence
: KW_GO step_clause from_clause over_clause where_clause yield_clause {
auto go = new GoSentence();
go->setStepClause($2);
go->setFromClause($3);
go->setOverClause($4);
go->setWhereClause($5);
if ($6 == nullptr) {
auto *cols = new YieldColumns();
for (auto e : $4->edges()) {
if (e->isOverAll()) {
continue;
}
auto *edge = new std::string(*e->edge());
auto *expr = new EdgeDstIdExpression(edge);
auto *col = new YieldColumn(expr);
cols->addColumn(col);
}
$6 = new YieldClause(cols);
}
go->setYieldClause($6);
$$ = go;
}
其在匹配到对应到 go 语句时,就构造对应的节点,然后由 bison 处理,最后生成一个抽象的语法树。
词法语法分析后开始执行模块,继续 gdb,进入 excute 函数,一直 step 直到进入ShowExecutor::execute 函数。
继续 next 直到 showSpaces(),step 进入此函数
auto future = ectx()->getMetaClient()->listSpaces();
auto *runner = ectx()->rctx()->runner();
'''
'''
std::move(future).via(runner).thenValue(cb).thenError(error);
此时Query Service通过 metaClient 和Meta Service通信拿到 spaces 数据,之后通过回调函数 cb 回传拿到的数据,至此 nGQL 语句 SHOW SPACES; 已经执行完毕,而其他复杂的语句也可以以此类推。
- 如果是正在运行的服务,可以先查出该服务的进程 ID,然后通过 gdb attach PID 来调试该进程;
- 如果不想启动服务端和客户端进行调试,在 src 目录下的每个文件夹下都有一个 test 目录,里面都是对对应模块或者功能进行的单元测试,可以直接编译对应的单元模块,然后跟踪运行。方法如下:
- 通过对应目录下的 CMakeLists.txt 文件找到对应的模块名
- 在 build 目录下 make 模块名,在 build/bin/test 目录下生成对应的二进制程序
- gdb 跟踪调试该程序
附录
阅读 NebulaGraph 源码需要了解的一些库:
- flex & bison:词法分析和语法分析工具,将客户端输入的 nGQL 语句解析为抽象语法树
- FBThrift:Facebook 开源的 RPC 框架,定义并生成了 Meta 层、Storage 层和 Graph 层的通讯过程代码
- folly:Facebook 开源的 C++14 组件库,提供了类似 Boost 和 std 库的功能,在性能上更加优化
- Gtest:Google 开源的 C++ 单元测试框架
其中数据库资料可以参考:
喜欢这篇文章?来来来,给我们的 GitHub 点个 star 表鼓励啦~~ 🙇♂️🙇♀️ [手动跪谢]
交流图数据库技术?加入 Nebula 交流群请先填写下你的 Nebula 名片,Nebula 小助手会拉你进群~~
作者有话说:Hi,我是明泉,是图数据 NebulaGraph 研发工程师,主要工作和数据库查询引擎相关,希望本次的经验分享能给大家带来帮助,如有不当之处也希望能帮忙纠正,谢谢~