
周边工具技术分享
Jupyter Notebook 遇上 NebulaGraph,可视化探索图数据库

在之前的《手把手教你用 NebulaGraph AI 全家桶跑图算法》中,除了介绍了 ngai 这个小工具之外,还提到了一件事有了 Jupyter Notebook 插件: https://github.com/wey-gu/ipython-ngql,可以更便捷地操作 NebulaGraph。
本文就手把手教你咋在 Jupyter Notebook 中,愉快地玩图数据库。
只要你仔细读完本文,一条 %ngql MATCH p=(n:player)->() RETURN p 命令就可以直接查询出数据,再接上 %ng_draw 就可以画出返回结果。
下面,进入今天的主菜——Jupyter Notebook 扩展:ipython-ngql。
其实,ipython-ngql 这个扩展断断续续地开发了两年,我一直没有开发完成。恰好之前有空,并完成了一直以来的心愿,把 ipython-ngql 重构并正式发布了。它除了完全适配 NebulaGrpah 3.x 所有查询之外,还支持了 Notebook 内的返回结果可视化。
在介绍 ipython-ngql 是什么之前,我先做个简单的 Jupyter Notebook 介绍,虽然大多数的 Python 开发都知道。
什么是 Jupyter Notebook
Jupyter Notebook / Jupyter Labs 项目最初起源自 IPython 这个项目,后者是一个命令行上的交互式 Python 解释环境。因为有很好的补全、高亮和丰富的扩展能力,IPython 很快就成为了 Python 的第一 IDLE 替代项目,并且后来衍生出来了可以在浏览器里做更多事情的笔记本模式。
Jupyter 的笔记本模式改变了数据科学和相关科研、工业领域里人们协作、开发、分享面向数据的工作方式。有了它,我们可以在一个笔记本中可复现、可分享地进行代码执行、科学计算、数据可视化等等操作,是数据科学家、科研工作者的非常喜欢的工具,而且它还早就引入了 Python 之外的很多其他语言作为执行内核支持。
因为在 Jupyter Notebook 中进行 NebulaGraph 的查询、计算、可视化一直是很多社区同学的心愿,在前阵子 NebulaGrpah AI Suite 的开发过程中,我并实现了 Jupyter 中方便进行 NetworkX / PySpark 的计算。既然有图计算了,索性我就把相关的查询、可视化功能一起做掉,并作为 Jupyter 的扩展一起发布出来给大家使用啦。
ipython-ngql 的安装
因为 ipython-ngql 本文就是一个基于 Jupyter Notebook 的扩展,所以它的安装非常简单。只需要在 Jupyter Notebook 中执行 %pip install ipython-ngql ,再加载它就好:
%pip install ipython-ngql
%load_ext ngql
然后,我们就可以用 %ngql 这个 Jupyter Magic word 连接 NebulaGraph 了:
%ngql --address 127.0.0.1 --port 9669 --user root --password nebula #填入 ip 地址和 graphd 的端口号
当成功连接服务之后,SHOW SPACES 的结果会返回在 notebook cell 下。
除了上面的扩展安装方法之外,你可以从 Docker 桌面版的扩展市场里搜索 NebulaGraph,一键安装本地开发环境。安装完毕之后,进入 NebulaGraph Docker 扩展内部,点击 NebulaGraph AI ,点击 Install NX Mode 安装本地的 NebulaGraph + Jupyter Notebook 开发环境。
数据查询
ipython-ngql 现在支持两种语法 %ngql 接单行查询和 %%ngql 接多行查询。
单行查询
例如:
%ngql USE basketballplayer;
%ngql MATCH (v:player{name:"Tim Duncan"})-->(v2:player) RETURN v2.player.name AS Name;
多行查询
例如:
%%ngql
ADD HOSTS "storaged3":9779,"storaged4":9779;
SHOW HOSTS;
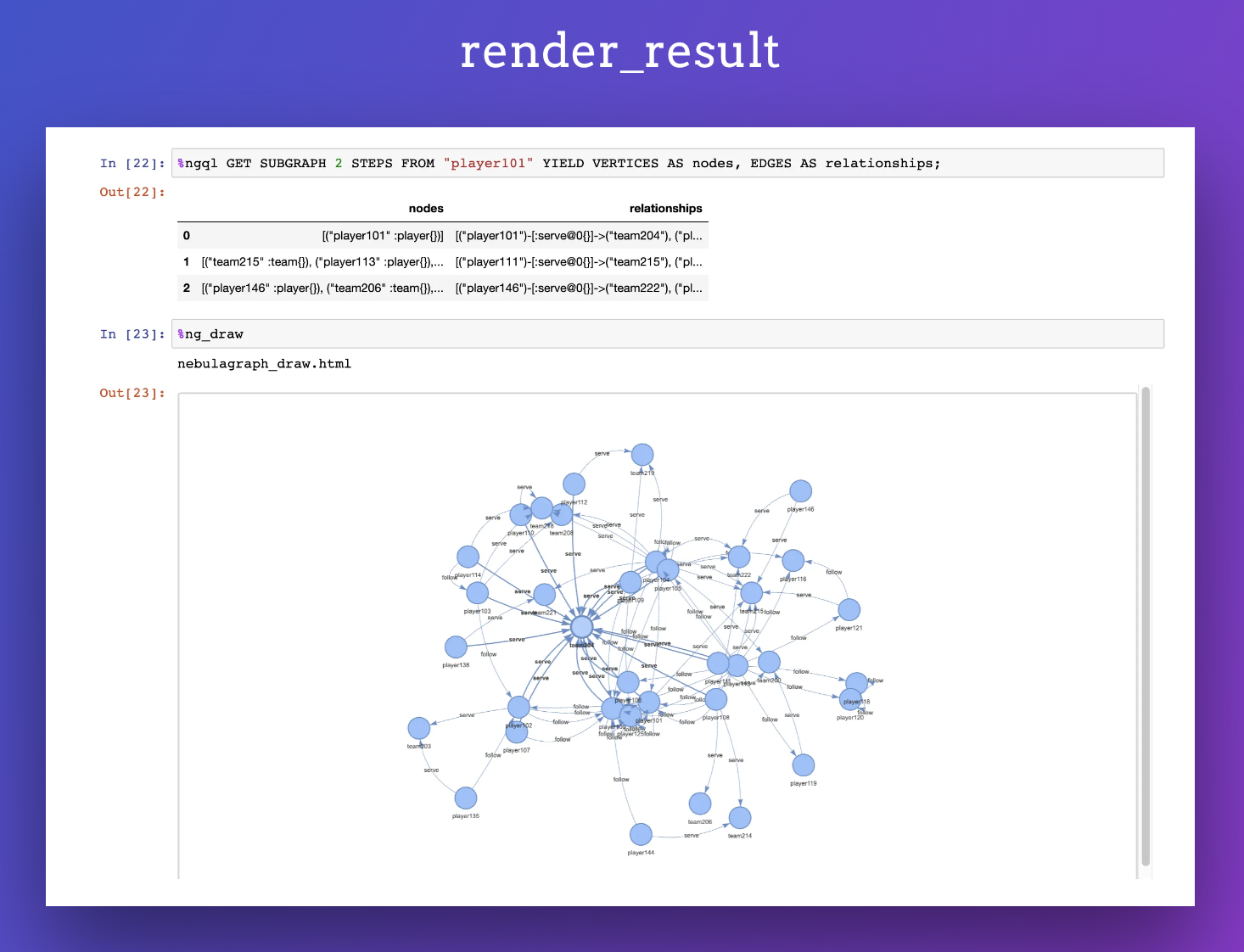
渲染结果
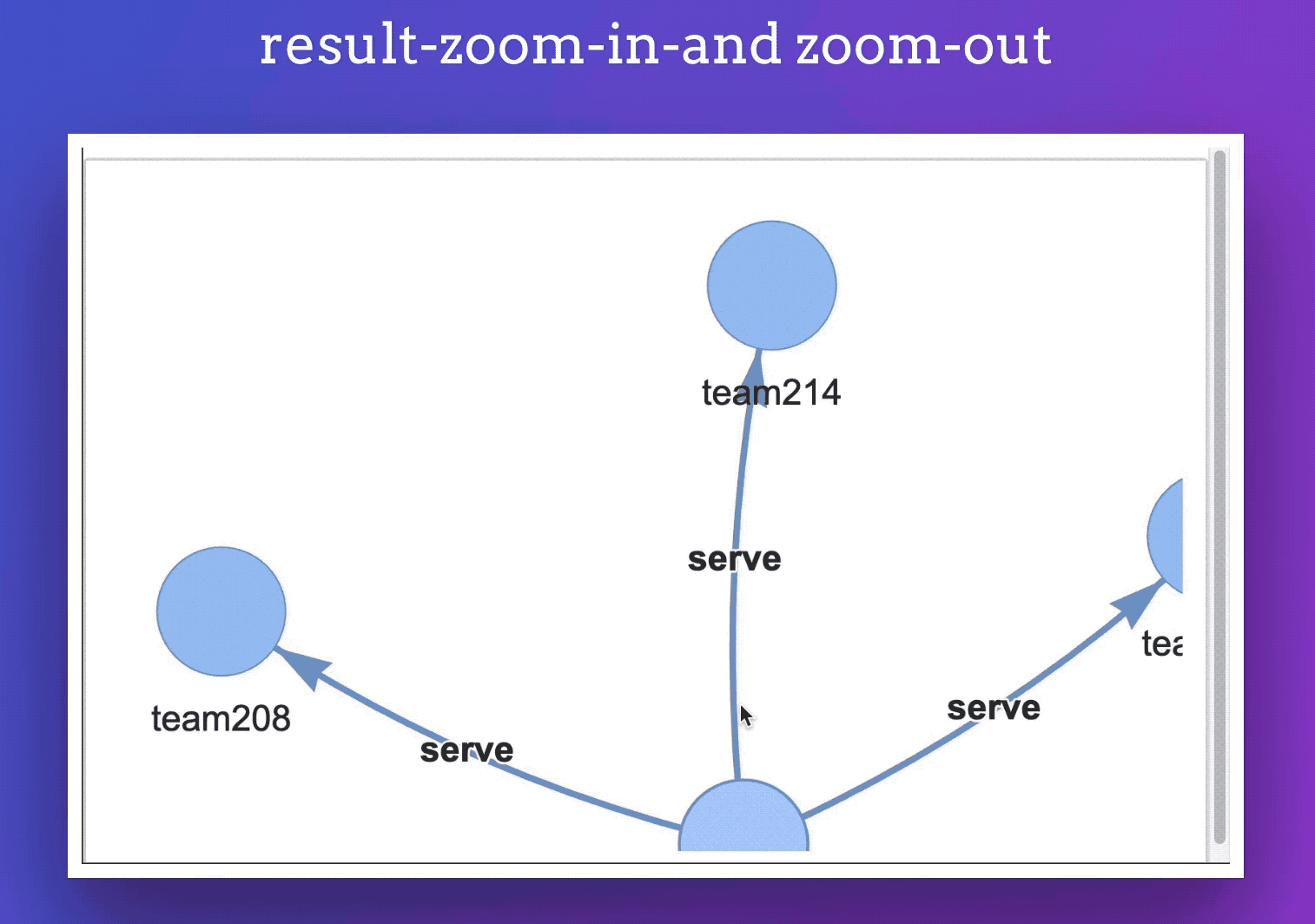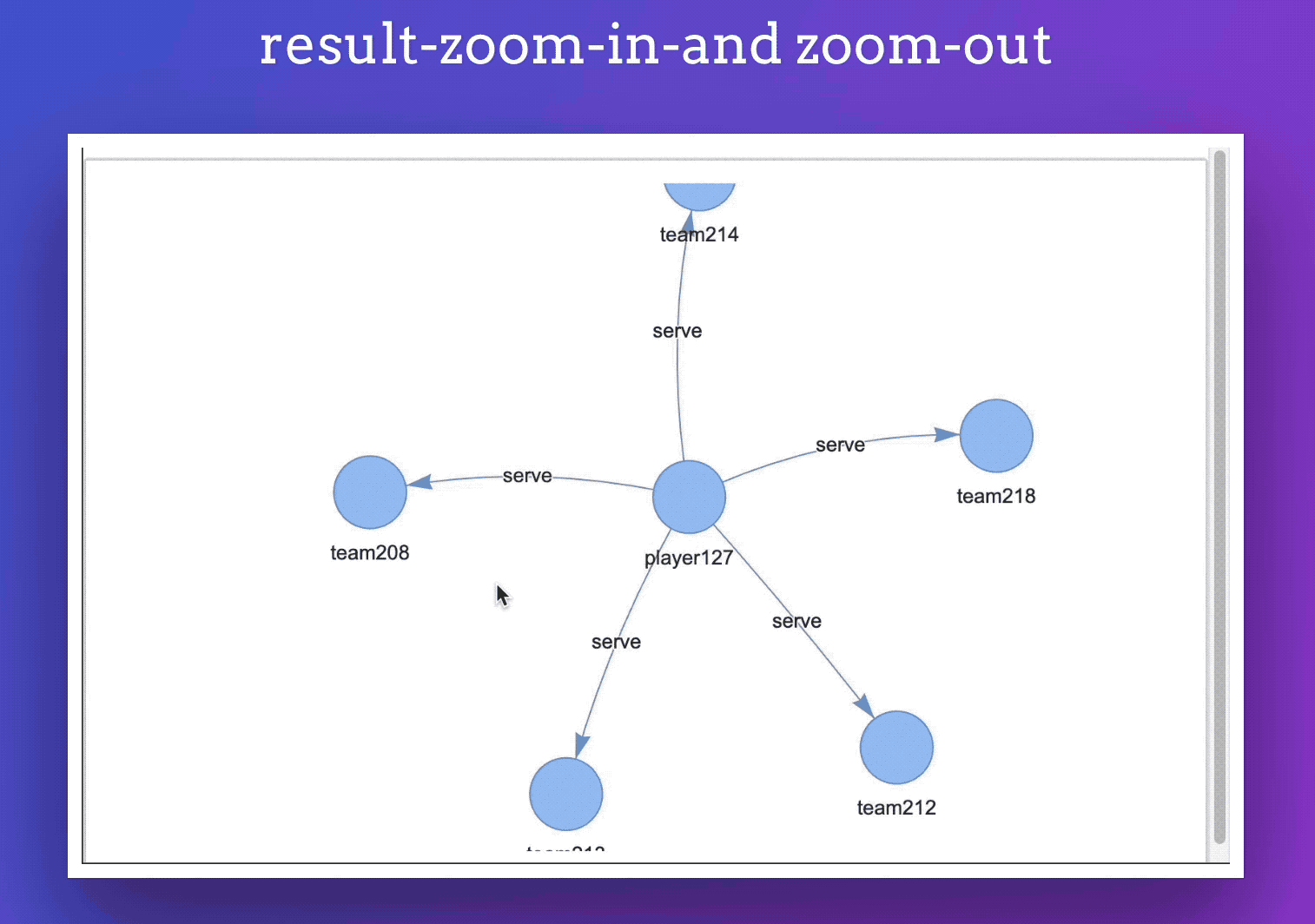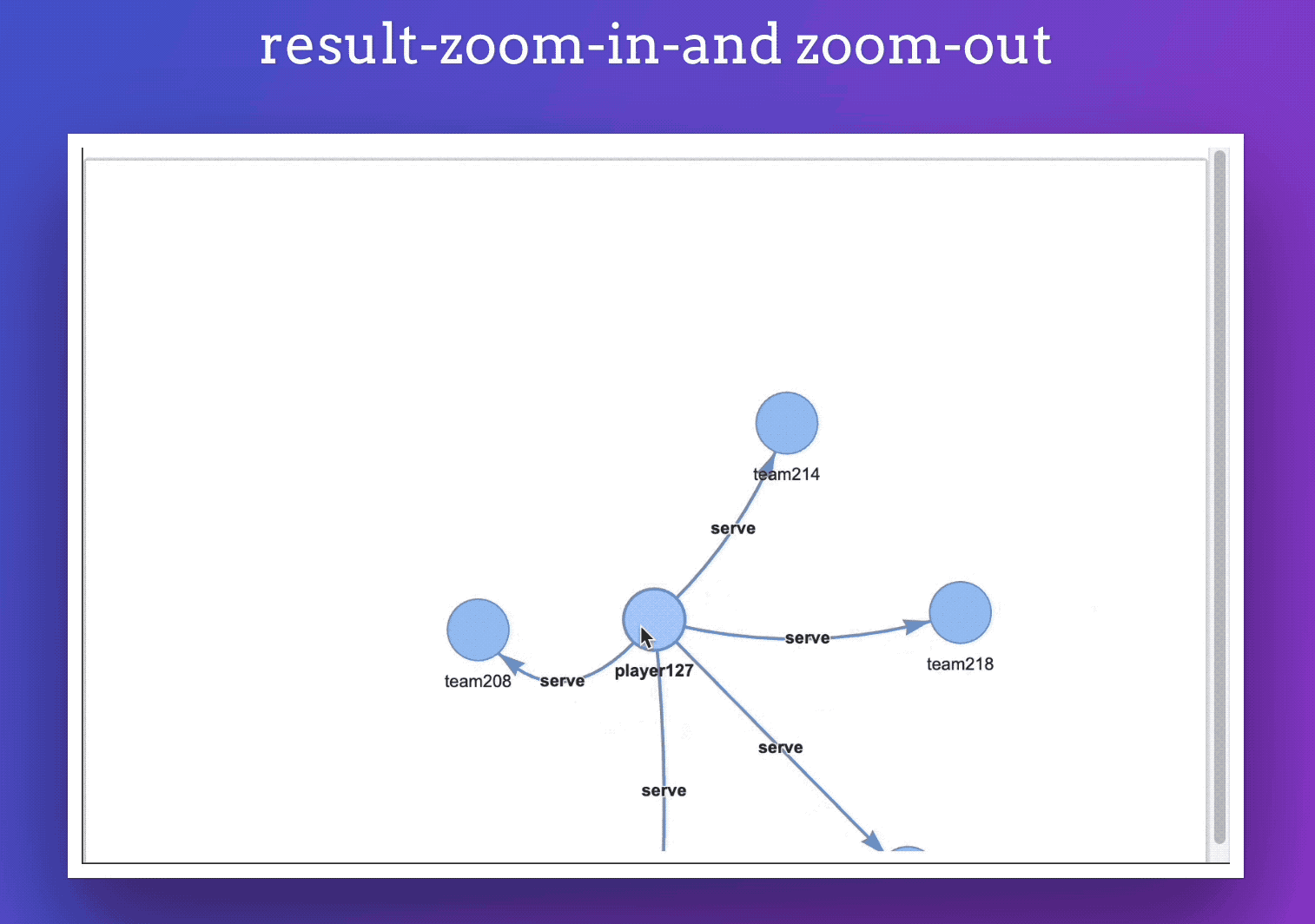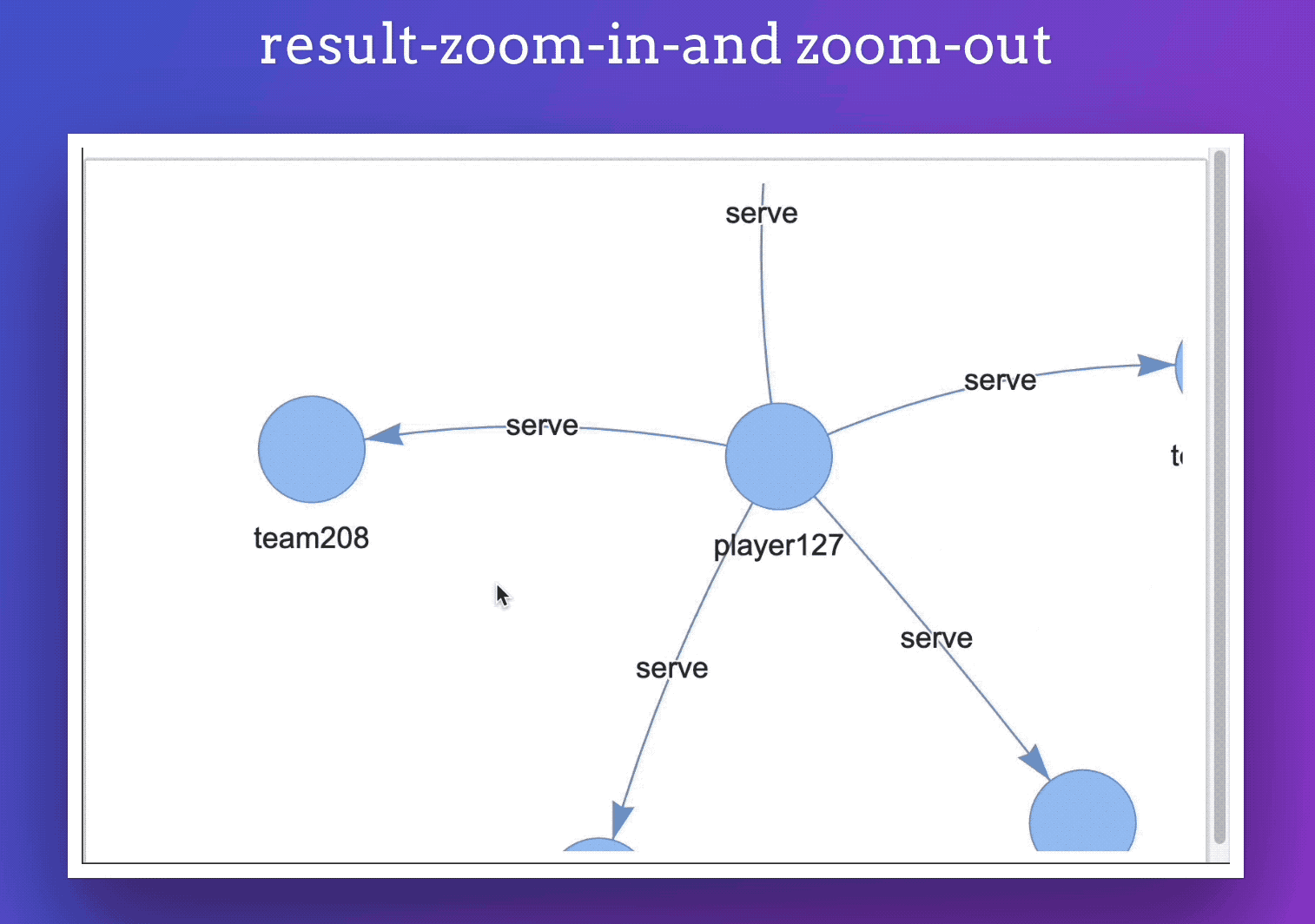
在任意一个查询后面紧跟着一个 %ng_draw 指令,就可以把结果可视化渲染出来。像是这样:
# one query
%ngql GET SUBGRAPH 2 STEPS FROM "player101" YIELD VERTICES AS nodes, EDGES AS relationships;
%ng_draw
# another query
%ngql match p=(:player)-[]->() return p LIMIT 5
%ng_draw
效果:
此外,你的渲染的结果还会被保存为单文件 html ,方便我们可以内嵌到任意网页中。
像是下面,其实就是一个内嵌的页面:
高阶用法
下面,我们来展示一些便捷的高阶用法。比如 %ngql help,可以获得更多帮助信息。
操作查询结果为 pandas DF
你的每次查询,返回的结果会被存到 _ 变量中,方便我们对它进行读取。像是这样:
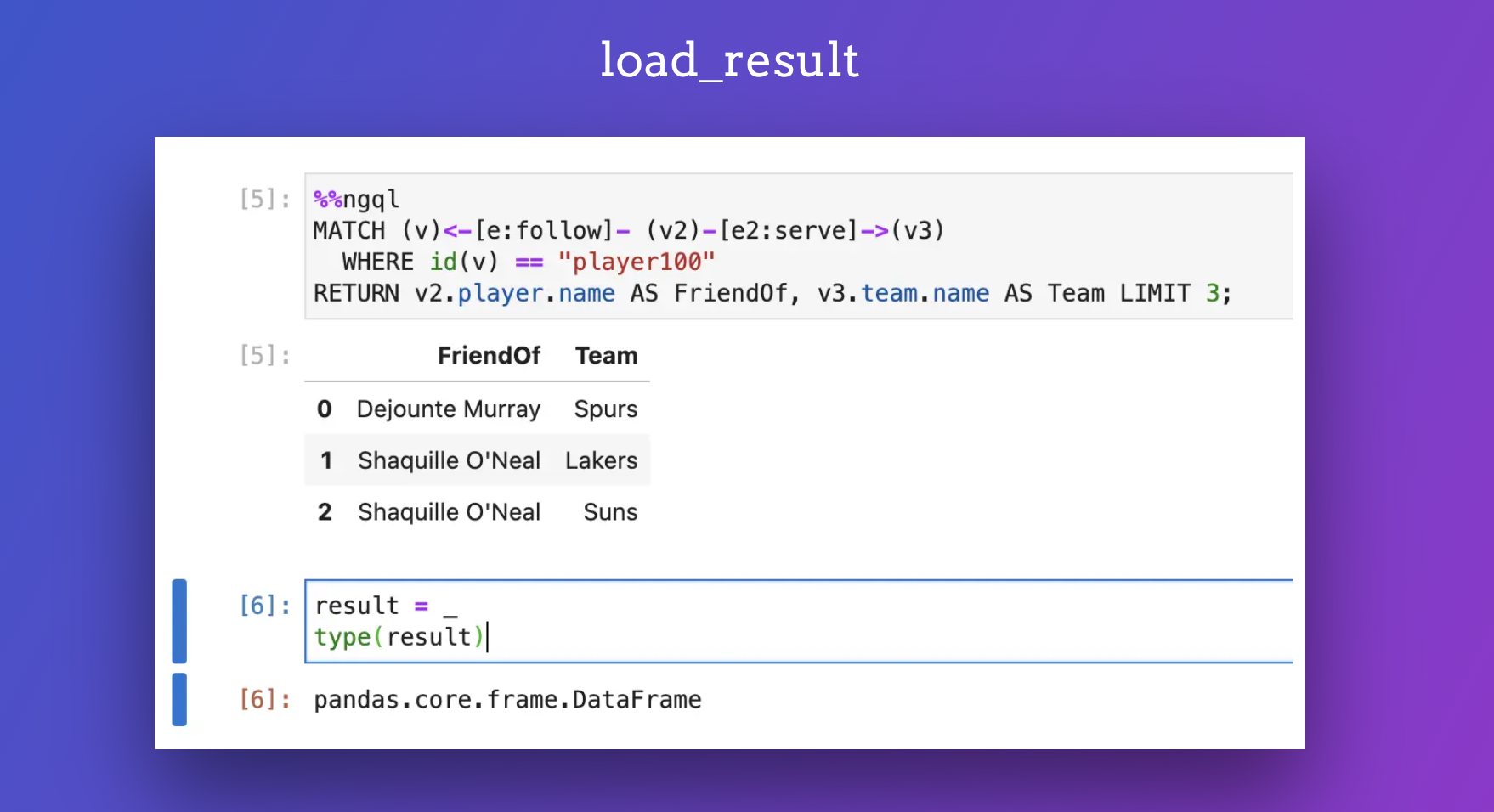
返回原始 ResultSet
ipython-ngql 默认返回的结果格式是 pandas DF,如果我们想在 Jupyter Notebook 中交互地调试 Python 的 NebulaGraph 应用代码,可以将返回结果设置为原始的 ResultSet 格式,方便直观进行 query 与结果解析。例如:
In [1] : %config IPythonNGQL.ngql_result_style="raw"
In [2] : %%ngql USE pokemon_club;
...: GO FROM "Tom" OVER owns_pokemon YIELD owns_pokemon._dst as pokemon_id
...: | GO FROM $-.pokemon_id OVER owns_pokemon REVERSELY YIELD owns_pokemon._dst AS Trainer_Name;
...:
...:
Out[3]:
ResultSet(ExecutionResponse(
error_code=0,
latency_in_us=3270,
data=DataSet(
column_names=[b'Trainer_Name'],
rows=[Row(
values=[Value(
sVal=b'Tom')]),
...
Row(
values=[Value(
sVal=b'Wey')])]),
space_name=b'pokemon_club'))
In [4]: r = _
In [5]: r.column_values(key='Trainer_Name')[0].cast()
Out[5]: 'Tom'
查询模板
除了上面那些功能,我还支持了模板功能,语法沿用了 Jinja2 的 {{ variable }}。详见这个例子:
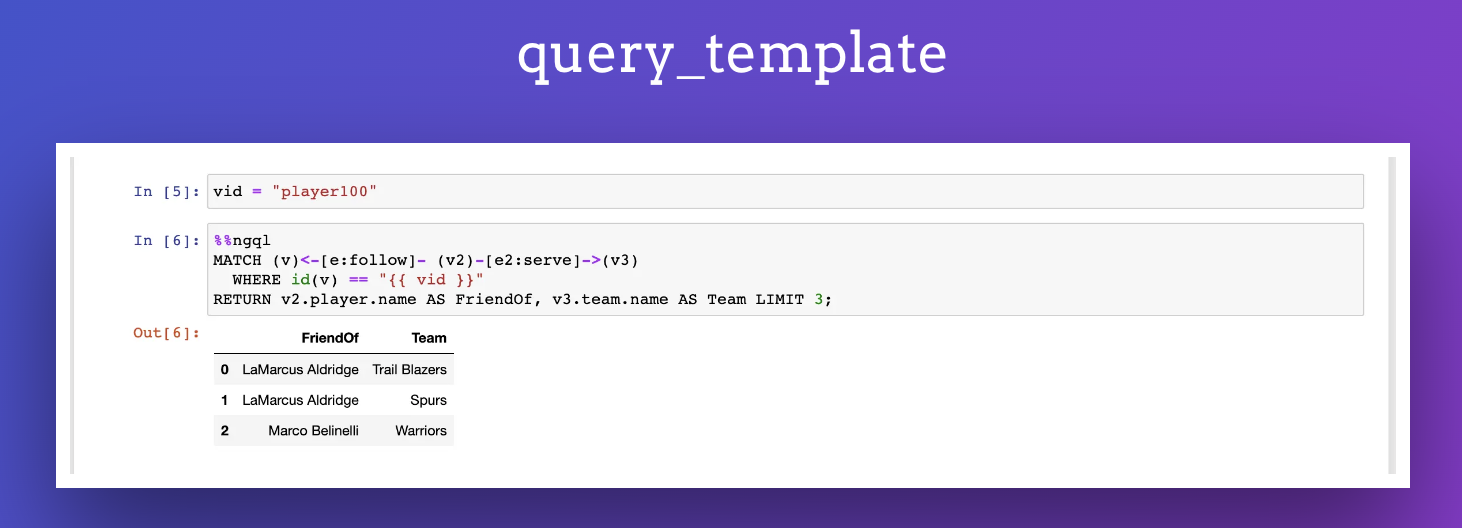
未来
后续,我打算增强可视化的自定义选项,也欢迎社区里的大伙来贡献新的 feature、idea。
项目的 repo 在 👉🏻https://github.com/wey-gu/ipython-ngql



