
行业科普
DDIA精读|分布式数据之多副本的主从模型选择
以下文章来源于木鸟杂记 ,作者穆尼奥

在上一篇《分布式数据之多副本的读写流程》 着重讲 Replication 的数据读写,在本篇内容中,我们将会侧重 Replication 的模型讲解。
目录
多主模型
- 多主模型应用场景
- 多个数据中心
- 离线工作的客户端
- 协同编辑
- 处理写入冲突
- 冲突检测
- 冲突避免
- 冲突收敛
- 自定义解决
- 界定冲突
- 多主复制拓扑
- 多主模型应用场景
无主模型
有节点故障时的写入
- 读时修复和反熵
- Quorum 读写
Quorum 一致性的局限
- 一致性监控
放松的 Quorum 和提示转交
- 多数据中心
并发写入检测
后者胜(Last-Write-Win)
发生于之前(Happens-before)和并发关系
确定 Happens-Before 关系
合并并发值
版本向量
多主模型
单主模型一个最大问题:所有写入都要经过它,如果由于任何原因,客户端无法连接到主副本,就无法向数据库写入。
于是自然产生一种想法:多主行不行?
多主复制(multi-leader replication):有多个可以接受写入的主副本,每个主副本在接收到写入之后,都要转给所有其他副本。即一个系统,有多个写入点。
多主模型应用场景
单个数据中心,多主模型意义不大:复杂度超过了收益。总体而言,由于一致性等问题,多主模型应用场景较少,但有一些场景,很适合多主:
数据库横跨多个数据中心
需要离线工作的客户端
协同编辑
多个数据中心
假设一个数据库的副本,横跨多个数据中心,如果使用单主模型,在写入时的延迟会很大。那么每个数据中心能不能各配一个主副本?
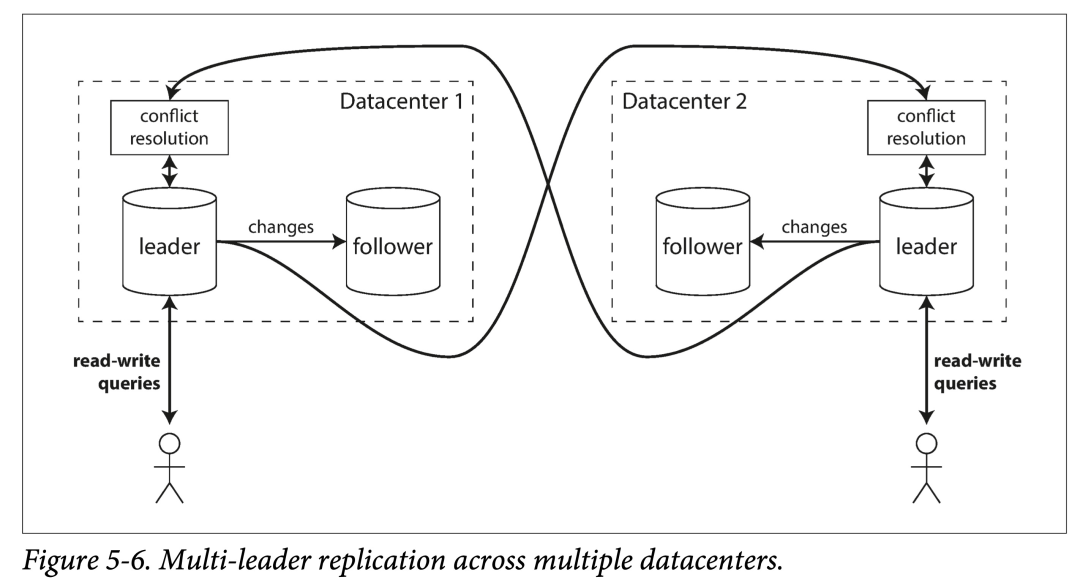
单主和多主,在多数据中心场景下的对比:

但是多主模型在一致性方面有很大缺陷:如果两个数据中心同时修改同样的数据,必须合理解决写冲突。另外,对于数据库来说,多主很难保证一些自增主键、触发器和完整性约束的一致性。因此在工程实践中,多主用的相对较少。
离线工作的客户端
离线工作的一个应用的多个设备上的客户端,如果也允许继续写入数据。如:日历应用。在电脑上和手机上离线时如果也支持添加日程。则在各个设备联网时,需要互相同步数据。
这种离线后还继续工作的多个副本,本质上就是一个多主模型:每个主都可以独立的写入数据,然后在网络连通后解决冲突。但,如何支持离线后正常地工作,联网后优雅地解决冲突,是一个难题。
Apache CouchDB 的一个特点便是支持多主模型。
协同编辑
Google Docs 等类似 SaaS 模式的在线协同应用越来越流行。
这种应用允许多人在线同时编辑文档或者电子表格,其背后的原理,与上一节离线工作的客户端很像。
为了实现协同,并解决冲突,可以:
悲观方式:加锁以避免冲突,但粒度需要尽可能小,否则无法允许多人同时编辑一个文档。
乐观方式:允许每个用户无脑写入,然后如果有冲突,交由用户解决。
Git 也是一个类似的协议。
处理写入冲突
多主模型最大的问题是:如何解决冲突。
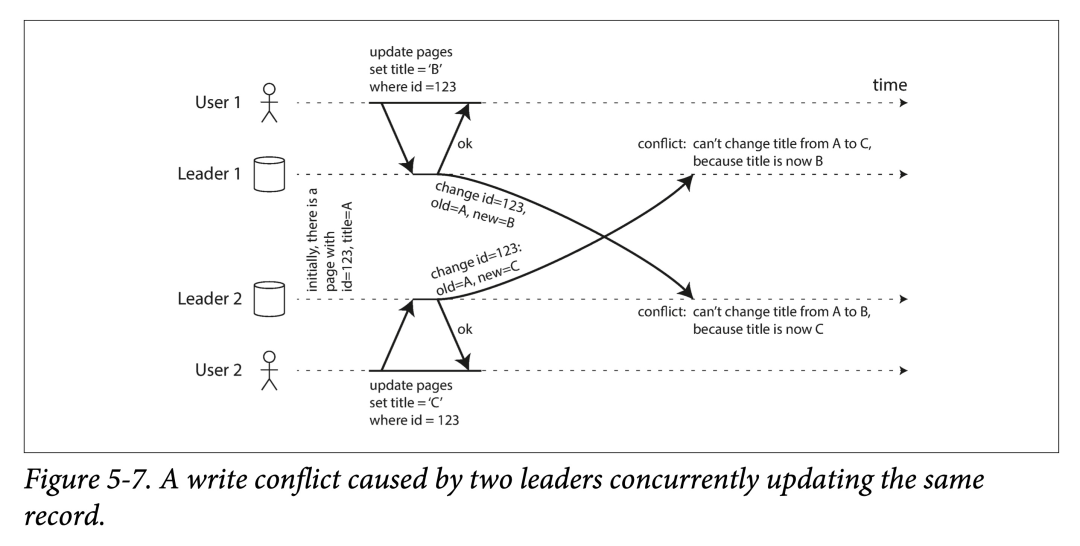
考虑 wiki 一个页面标题的修改:
- 用户 1 将该页面标题从 A 修改到 B
- 用户 2 将该页面标题从 A 修改到 C
两个操作在本地都修改成功,然后异步同步时,会出现冲突。
冲突检测
有同步或者异步的方式进行冲突检测。
对于单主模型,当检测到冲突时,由于只有一个主副本,可以同步地检测冲突,从而解决冲突:
让第二个写入阻塞,直到第一个写完成。
让第二个写入失败,进行重试。
但对于多主模型,两个写入可能会在不同主副本立即成功。然后异步同步时,发现冲突,但为时已晚(没有办法简单决定如何解决冲突)。
虽然,可以在多主间使用同步方式写入所有副本后,再返回请求给客户端。但这会失掉多主模型的主要优点:允许多个主副本独立接受写入。此时,蜕化成单主模型。
冲突避免
解决冲突最好的方式是在设计上避免冲突。
由于多主模型在冲突发生后再去解决会有很大的复杂度,因此常使用冲突避免的设计。
假设你的数据集可以分成多个分区,让不同分区的主副本放在不同数据中心中,那么从任何一个分区的角度来看,变成了单主模型。
举个栗子:对于服务全球用户的应用,每个用户就近固定路由到附近的数据中心。则,每个用户信息都有唯一的主副本。
但如果:
用户从一个地点迁移到了另一个地
点某个数据中心损坏,导致路由变化
就会对该设计提出一些挑战。
冲突收敛
在单主模型中,所有事件比较容易进行定序,因此我们总可以用后一个写入覆盖前一个写入。
但在多主模型中,很多冲突无法定序:从每个主副本来看,事件顺序是不一致的,并且没有哪个更权威一些,那么就无法让所有副本最终收敛(convergent)。
此时,我们就需要一些规则,来让其收敛:
- 给每个写入一个序号,并且后者胜。本质上是使用外部系统对所有事件进行定序。但可能会产生数据丢失。举个例子,对于一个账户,原有 10 元,客户端 A - 8,客户端 B - 3,任何一个单独成功都有问题。
- 给每个副本一个序号,序号更高的副本有更高的优先级。这也会造成低序号副本的数据丢失。
- 提供一种自动的合并冲突的方式。如,假设结果是字符串,则可以将其排序后,使用连接符进行链接,如在之前 Wiki 的冲突中,合并后的标题为“B/C”。
- 使用程序定制一种保留所有冲突值信息的冲突解决策略。也可以将这个定制权,交给用户。
自定义解决
由于只有用户知道数据本身的信息,因此较好的方式是,将如何解决冲突交给用户。即,允许用户编写回调代码,提供冲突解决逻。该回调可以在:
写时执行。在写入时发现冲突,调用回调代码,解决冲突后写入。这些代码通常在后台执行,并且不能阻塞,因此不能在调用时同步的通知用户。但打个日志之类的还是可以的。
读时执行。在写入冲突时,所有冲突都会被保留(如使用多版本)。下次读取时,系统会将所有数据本版本返回给用户,进行交互式的或者自动的解决冲突,并将结果写回系统。
上述冲突解决只限于单个记录、行、文档层面。
界定冲突
有些冲突显而易见:并发写同一个 Key。
有些冲突则更隐晦,考虑一个会议室预定系统。预定同一个会议室不一定会发生冲突,只有预定时间段有交叠,才会有冲突。
多主复制拓扑
复制拓扑(replication topology)描述了数据写入从一个节点到另一个节点的传播路径。
在只有两个主副本时,拓扑是确定的,如图 5-7。Leader1 和 Leader 都得把数据发给对方。但随着副本数的增多,数据复制拓扑就会有多种选择,如下图:
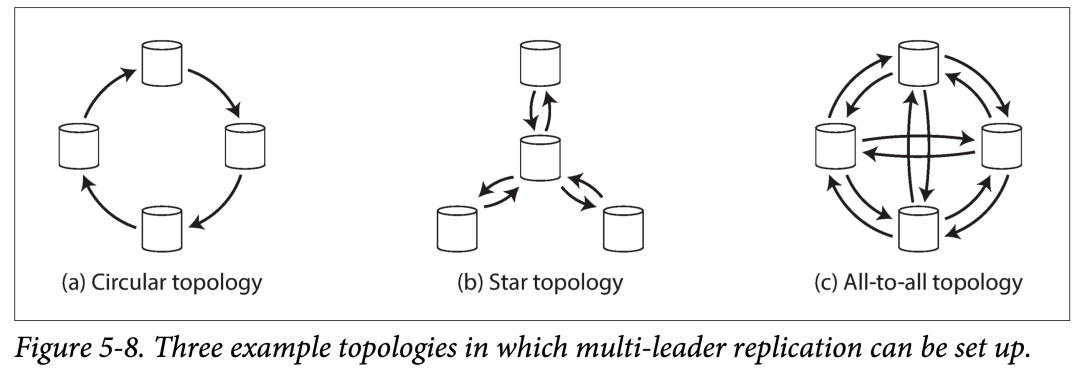
上图表示了 ≥ 4 个主副本时,常见的复制拓扑:
环形拓扑。通信跳数少,但是在转发时需要带上拓扑中前驱节点信息。如果一个节点故障,则可能中断复制链路。
星型拓扑。中心节点负责接受并转发数据。如果中心节点故障,则会使得整个拓扑瘫痪。
全连接拓扑。每个主库都要把数据发给剩余主库。通信链路冗余度较高,能较好的容错。
对于环形拓扑和星型拓扑,为了防止广播风暴,需要对每个节点打上一个唯一标志(ID),在收到他人发来的自己的数据时,及时丢弃并终止传播。
全连接拓扑也有自己问题:尤其是所有复制链路速度不一致时。考虑下面一个例子:
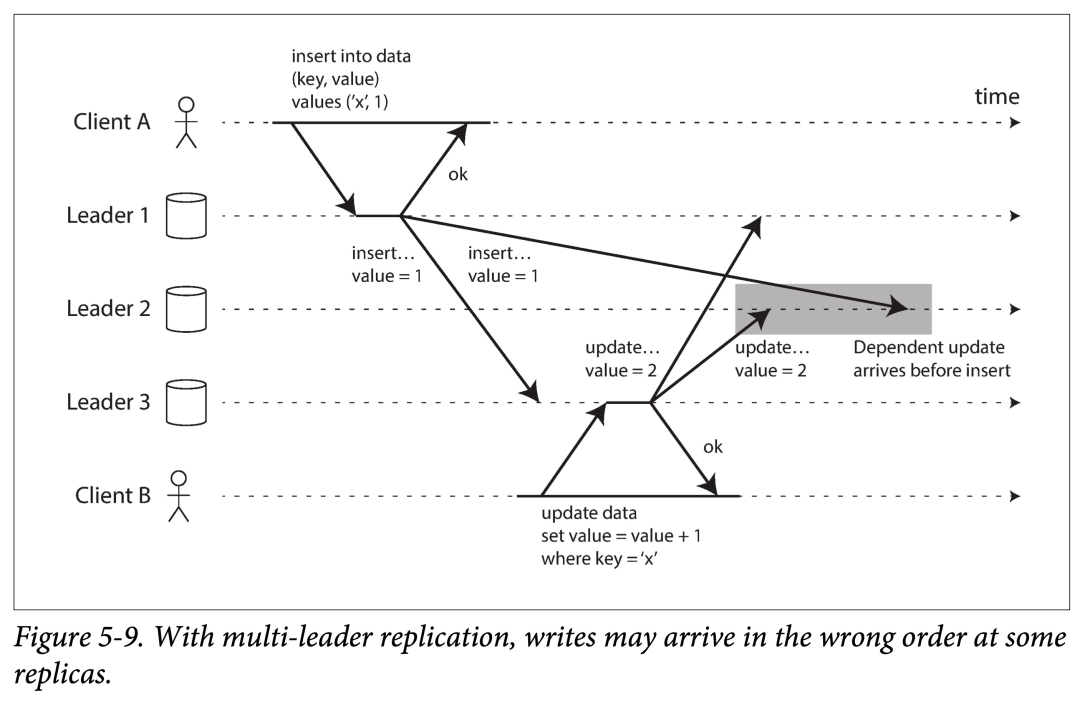
两个有因果依赖的(先插入,后更新)的语句,在复制到 Leader 2 时,由于速度不同,导致其接收到的数据违反了因果一致性。
要想对这些写入事件进行全局排序,仅用每个 Leader 的物理时钟是不够的,因为物理时钟:
可能不能够充分同步
同步时可能会发生回退
可以用一种叫做版本向量(version vectors) 的策略,对多个副本的事件进行排序,解决因果一致性问题。下一节会详细讨论。
最后忠告:如果你要使用基于多主模型的系统,一定要知晓上面提到的问题,多做测试,确保其提供的保证符合你的使用场景。
无主模型
有主模型中,由主副本决定写入顺序,从副本在写入上不直接和客户端打交道,只是重放其对应的主副本的写入顺序(也可以理解为主副本为从副本的客户端)。
而无主模型,则允许任何副本接受写入。
在关系数据库时代,无主模型已经快被忘却。从 Amazon 的 Dynamo 论文开始,无主模型又重新大放异彩,Riak,Cassandra 和 Voldemort 都受其启发,可以统称为 Dynamo 流(Dynamo-style)。
奇特的是,Amazon 的一款数据库产品 DynamoDB,和 Dynamo 并不是一个东西。
通常来说,在无主模型中,写入时可以:
由客户端直接写入副本。
由协调者(coordinator) 接收写入,转发给多副本。但与主副本不同,协调者并不负责定序。
有节点故障时的写入
基于主副本(leader-based)的模型,在有副本故障时,需要进行故障切换。
但在无主模型中,简单忽略它就行。
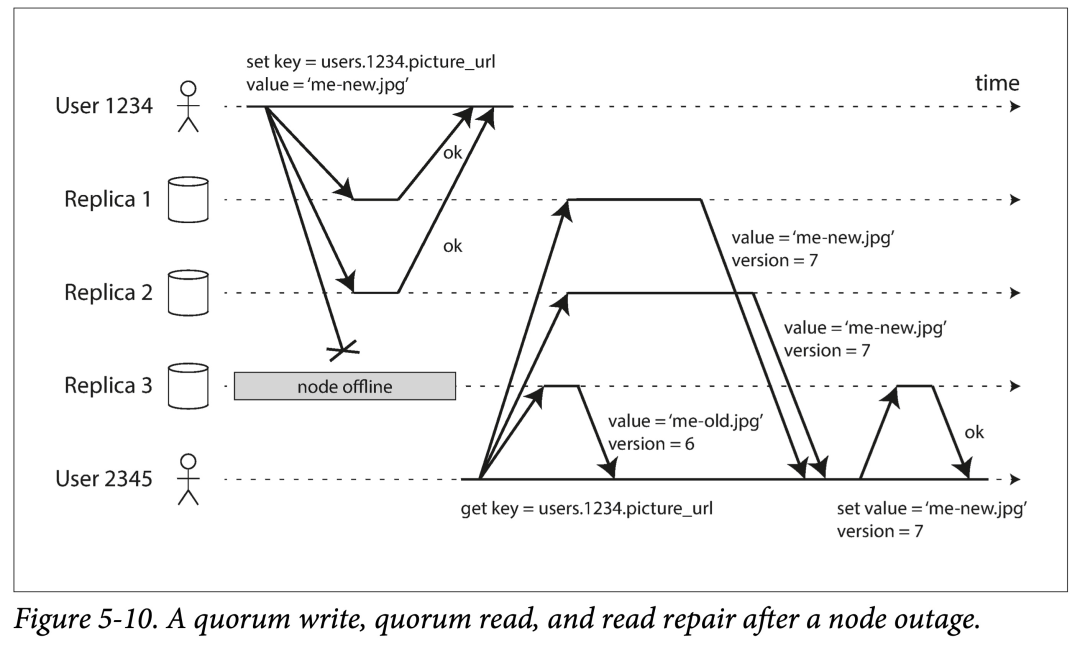
多数派写入,多数派读取,以及读时修复。
由于写入时,简单的忽略了宕机副本;在读取时,就要多做些事情了:同时读取多个副本,选取最新版本的值。
读时修复和反熵
无主模型也需要维持多个副本数据的一致性。在某些节点宕机重启后,如何让其弥补错过的数据?
Dynamo 流派的存储中通常有两种机制:
读时修复(read repair),本质上是一种捎带修复,在读取时发现旧的就顺手修了。
反熵过程(anti-entropy process),本质上是一种兜底修复,读时修复不可能覆盖所有过期数据,因此需要一些后台进程,持续进行扫描,寻找陈旧数据,然后更新。这个博文对该词有展开描述:https://www.influxdata.com/blog/eventual-consistency-anti-entropy/。
Quorum 读写
如果副本总数为 n,写入 w 个副本才认定写入成功,并且在查询时最少需要读取 r 个节点。只要满足 w + r > n,我们就能读到最新的数据(鸽巢原理)。此时 r 和 w 的值称为 quorum 读写。即这个约束是保证数据有效所需的最低(法定)票数。
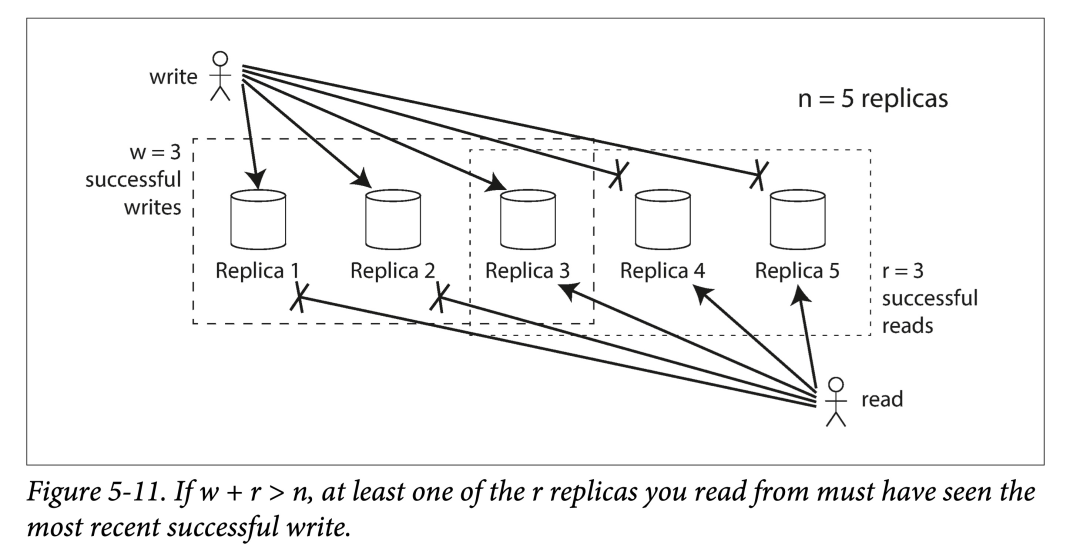
在 Dynamo 流派的存储中,n、r 和 w 通常是可以配置的:
n 越大冗余度就越高,也就越可靠
r 和 w 都常都选择超过半数,如 (n+1)/2
w = n 时,可以让 r = 1。此时是牺牲写入性能换来读取性能。
考量满足 w+r > n 系统对节点故障的容忍性:
如果 w < n,则有节点不可用时,仍然能正常写入。
如果 r < n,则有节点不可用时,仍然能正常读取。
特化一下:
如果 n = 3,r = w = 2,则系统可以容忍最多一个节点宕机。
如果 n = 5,r = w = 3,则系统可以容忍最多两个节点宕机。
通常来说,我们会将读或者写并行的发到全部 n 个副本,但是只要等到法定个副本的结果,就可以返回。
如果由于某种原因,可用节点数少于 r 或者 w,则读取或者写入就会出错。
Quorum 一致性的局限
由于 w + r > n 时,总会至少有一个节点(读写子集至少有一个节点的交集)保存了最新的数据,因此总是期望能读到最新的。
当 w + r ≤ n 时,则很可能会读到过期的数据。
但在 w + r > n 时,有一些边角情况(corner case),也会导致客户端读不到最新数据:
使用宽松的 Quorum 时(n 台机器范围可以发生变化),w 和 r 可能并没有交集。
对于写入并发,如果处理冲突不当时。比如使用 last-win 策略,根据本地时间戳挑选时,可能由于时钟偏差造成数据丢失。
对于读写并发,写操作仅在部分节点成功就被读取,此时不能确定应当返回新值还是旧值。
如果写入节点数 < w 导致写入失败,但并没有对数据进行回滚时,客户端读取时,仍然会读到旧的数据。
虽然写入时,成功节点数 > w,但中间有故障造成了一些副本宕机,导致成功副本数 < w,则在读取时可能会出现问题。
即使都正常工作,也有可能出现一些关于时序(timing)的边角情况。
因此,虽然 Quorum 读写看起来能够保证返回最新值,但在工程实践中,有很多细节需要处理。
如果数据库不遵守之前副本滞后小节引入的几个一致性保障,前面提到的异常仍然可能会发生。
一致性监控
对副本数据陈旧性监控,能够让你了解副本的健康情况,当其落后太多时,可以及时调查原因。
基于领导者的多副本模型,由于每个副本复制顺序一致,则可以方便的给出每个副本的落后(lag)进度。
但对于无主模型,由于没有固定写入顺序,副本的落后进度变得难以界定。如果系统只使用读时修复策略,则对于一个副本的落后程度是没有限制的。读取频率很低数据可能版本很老。
最终一致性是一种很模糊的保证,但通过监控能够量化“最终”(比如到一个阈值),也是很棒的。
放松的 Quorum 和提示转交
正常的 Quorum 能够容忍一些副本节点的宕机。但在大型集群(总节点数目 > n)中,可能最初选中的 n 台机器,由于种种原因(宕机、网络问题),导致无法达到法定读写数目,则此时有两种选择:
对于所有无法达到 r 或 w 个法定数目的读写,直接报错。
仍然接受写入,并且将新的写入暂时交给一些正常节点。
后者被认为是一种宽松的法定数目 (sloppy quorum):写和读仍然需要 w 和 r 个成功返回,但是其所在节点集合可以发生变化。
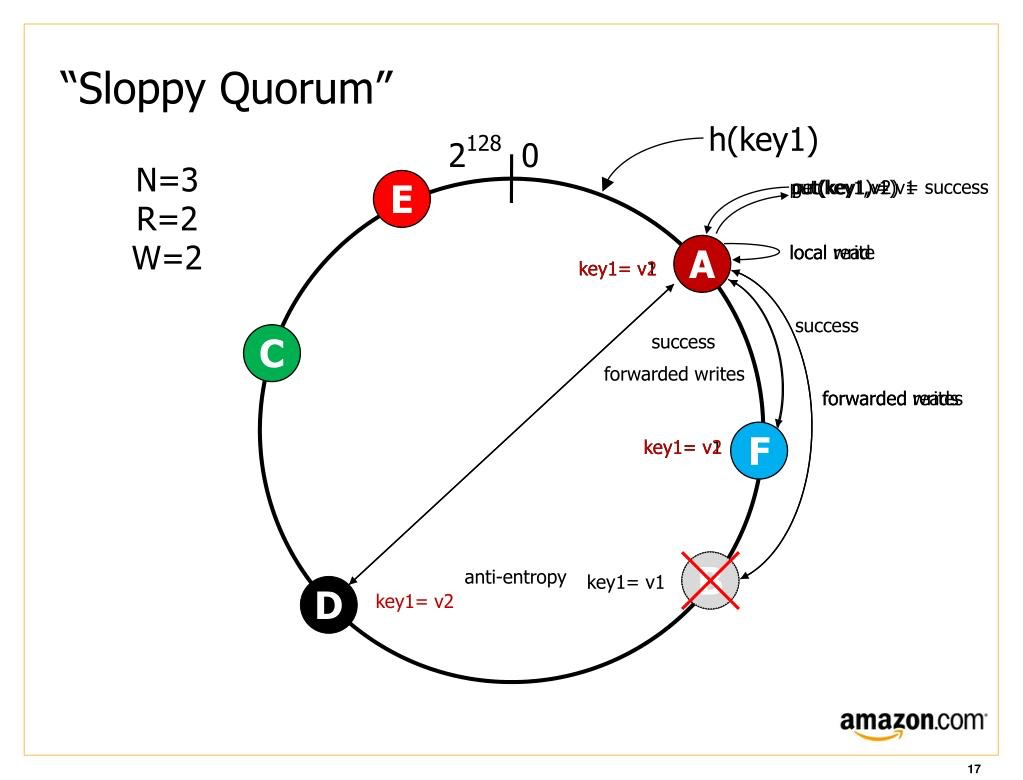
一旦问题得到解决,数据将会根据线索移回其应该在的节点(D—> B),我们称之为提示移交(hinted handoff)。这个移交过程是由反熵 anti-entropy 后台进程完成的。
这是一种典型的牺牲部分一致性,换取更高可用性的做法。在常见的 Dynamo 实现中,放松的法定人数是可选的。在 Riak 中,它们默认是启用的,而在 Cassandra 和 Voldemort 中它们默认是禁用的。
多数据中心
无主模型也适用于系统多数据中心部署。
为了同时兼顾多数据中心和写入的低延迟,有一些不同的基于无主模型的多数据中心的策略:
其中 Cassandra 和 Voldemort 将 n 配置到所有数据中心,但写入时只等待本数据中心副本完成就可以返回。
Riak 将 n 限制在一个数据中心内,因此所有客户端到存储节点的通信可以限制到单个数据中心内,而数据复制在后台异步进行。
并发写入检测
由于 Dynamo 允许多个客户端并发写入相同 Key,则即使使用严格的 Quorum 读写,也会产生冲突:对于时间间隔很短(并发)的相同 key 两个写入,不同副本上收到的顺序可能不一致。
此外,读时修复和提示移交时,也可能产生冲突。
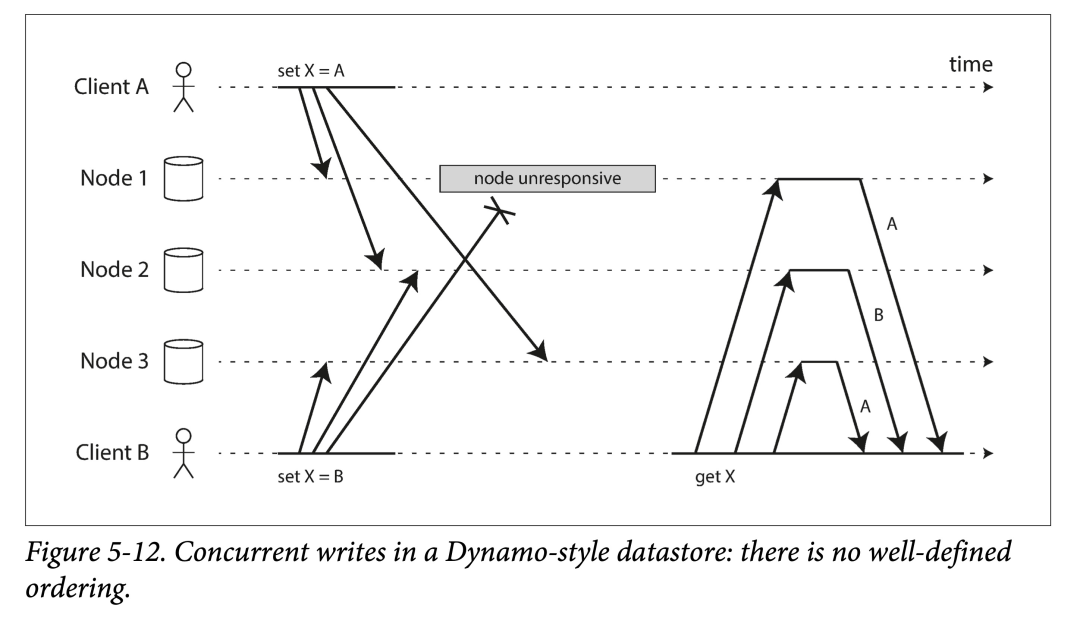
如上图,如果每个节点不去检查顺序,而是简单的接受写入请求,就落到本地,不同副本间可能就会出现永久不一致:上图 Node1 和 Node3 上副本 X 的值是 A,Node2 上副本 X 的值是 B。
为了使所有副本最终一致,需要有一种手段来解决并发冲突。
后者胜(Last-Write-Win)
后者胜(LWW,last write wins)的策略是,通过某种手段确定一种全局唯一的顺序,然后让后面的修改覆盖之前的修改。
如,为所有写入附加一个全局时间戳,如果对于某个 key 的写入有冲突,可以挑选具有最大时间戳的数据保留,并丢弃较早时间戳的写入。
LWW 有一个问题,就是多个并发写入的客户端,可能都认为自己成功了,但是最终只有一个值被保留了,其他都在后台被丢弃了。即,其迅速再读,会发现不是自己写入的数据。
使用 LWW 唯一安全的方法是:key 是一次可写,后变为只读。如 Cassandra 建议使用一个 UUID 作为主键,则每个写操作都只会有一个唯一的键。
发生于之前(Happens-before)和并发关系
考虑之前的两个图:
在 5-9 中,由于 client B 的更新依赖于 client A 的插入,因此他们是因果关系。
在 5-12 中,set X = A 和 set X = B 是并发的,因为他们都互相不知道对方存在,也不存在因果关系。
系统中任意的两个写入 A 和 B,只可能存在三种关系:
A happens before B
B happens before A
A B 并发
从另外一个角度来说(集合运算)
A 和 B 并发 < === > A 不 happens-before B && B 不 happens-before A
如果两个操作可以定序,则 last write win ;如果两个操作并发,则需要进行冲突解决。
Lamport 时钟相关论文中有详细推导相关概念关系。为了定义并发,事件发生的绝对时间先后并不重要,只要两个事件都意识不到对方的存在,则称两个操作“并发”。从狭义相对论上来说,只要两个事件发生的时间差,小于光在两者距离传播所用时间,则两个事件不可能互相影响。推广到计算机网络中,只要由于网络问题导致,在事件发生时间差内,两者不能互相意识到,则称其是并发的。
确定 Happens-Before 关系
我们可以用某种算法来确定系统中任意两个事件,是否存在 happens-before 关系,还是并发关系。以一个两个 client 并发添加购物车例子来看:
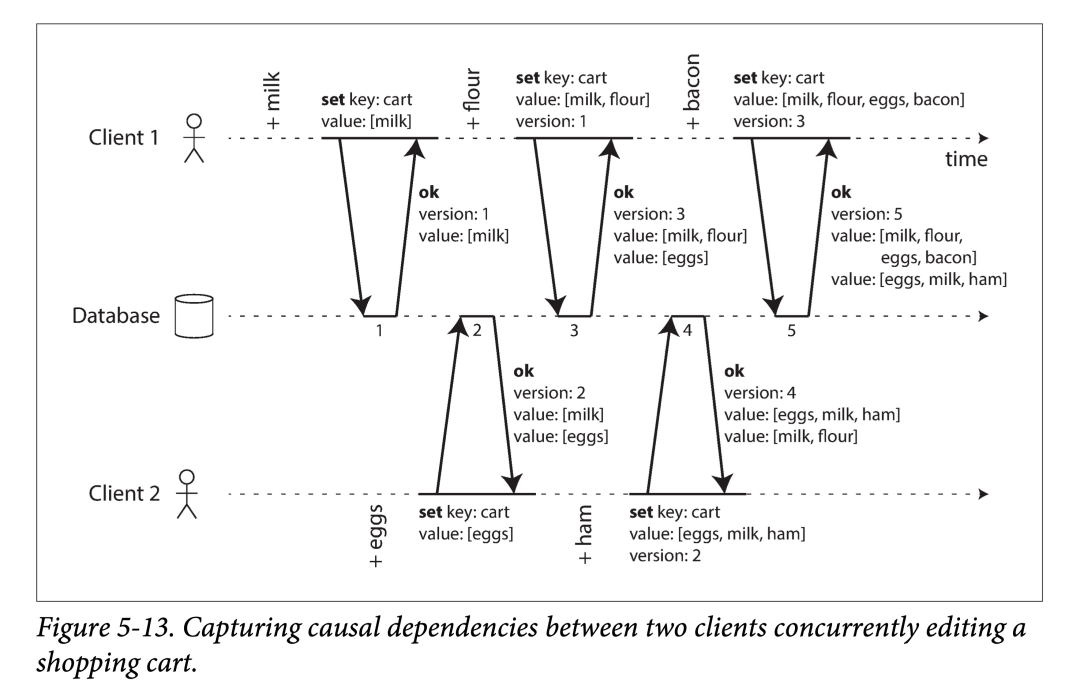
需要注意:
不会主动读取,只有主动写入,通过写入的返回值读取数据库当前状态。
客户端下一次写入,依赖于(因果关系)本客户端上一次写入后获取的返回值。
对于并发,数据库不会覆盖,而是保留多个并发值(每个 client 一个)。
上图中的数据流,如下图所示。箭头表示 happens-before 关系。本例中,客户端永远没办法完全获知服务器数据,因为总有另外的客户端进行并发操作。但是旧版本的值会被覆盖,并且不会丢失写入。
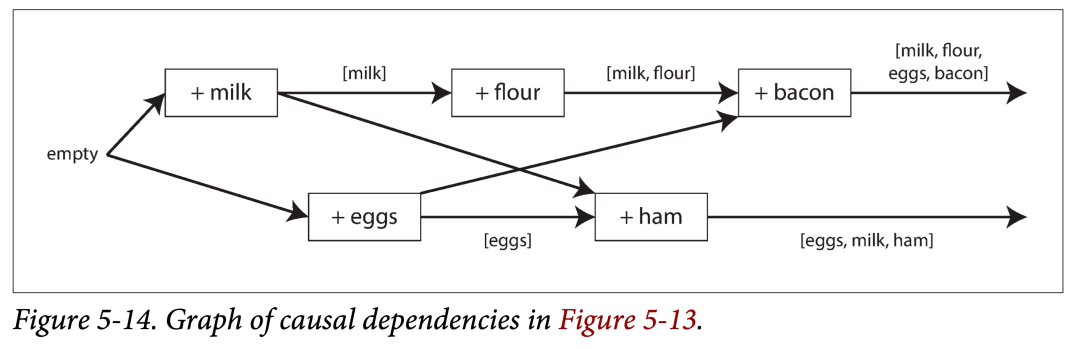
总结下,该算法如下:
- 服务器为每个键分配一个版本号 V,每次该键有写入时,将 V + 1,并将版本号与写入的值一块保存。
- 当客户端读取该键时,服务器将返回所有未被覆盖的值以及最新的版本号。
- 客户端在进行下次写入时,必须包含之前读到的版本号 Vx (说明基于哪个版本进行新的写入),并将读取的值合并到一块。
- 当服务器收到特定版本号 Vx 的写入时,可以用其值碧盖所有 V Vx 的值。
如果又来一个新的写入,不基于任何版本号,则该写入不会覆盖任何内容。
合并并发值
该算法可以保证所有数据都不会被无声的丢弃。但,需要客户端在随后写入时合并之前的值来清理多个值。如果简单基于时间戳进行 LWW,则有些数据又会被丢掉。
因此需要根据实际情况,选择一些策略来解决冲突,合并数据。
- 对于上述购物车中只增加物品的例子,可以使用“并集”来合并冲突数据。
- 如果购物车汇总还有删除操作,就不能简单并了,但是可以将删除变为增加(写一个 tombstone 标记)。
版本向量
上面例子只有单个副本。将该算法扩展到无主多副本模型时,只使用一个版本值显然不够,这时需要给每个副本的键都引入版本号,对于同一个键来说,不同副本的版本会构成版本向量(version vector)。
key1
A Va
B Vb
C Vc
key1: [Va, Vb, Vc]
[Va-x, Vb-y, Vc-z] <= [Va-x1, Vb-y1, Vc-z1] <==>
x <= x1 && y <= y1 && z <= z1
每个副本在遇到写入时,会增加对应键的版本号,同时跟踪从其他副本中看到的版本号,通过比较版本号大小,来决定哪些值要覆盖哪些值要保留。
谢谢你读完本文(///▽///)
如果你想尝鲜图数据库 NebulaGraph,记得去 GitHub 下载、使用、(^з^)-☆ star 它 -> GitHub;如果你有更高的性能、易用性、运维实施等方面的需求,你也可以随时 联系我们,获取进一步的帮助哦~



