
社区动态
Pick of the Week'22 |第 2 周看点:酷炫可视化工具在线等你试用

每周五 Nebula 为你播报每周看点,每周看点由固定模块:产品动态、社区问答、推荐阅读,和随机模块:本周大事件构成。
新的一年,我们重新开启之前的每周看点模块,同以往一样和大家一起回顾下本周有什么实用 pr 以及大事件需要关注。不知道元旦放假回来的第一周,你的工作状态如何呢?🌝 Nebula 的研发同学状态杠杠的~~
本周看点
DB-Engine 一月排名上线
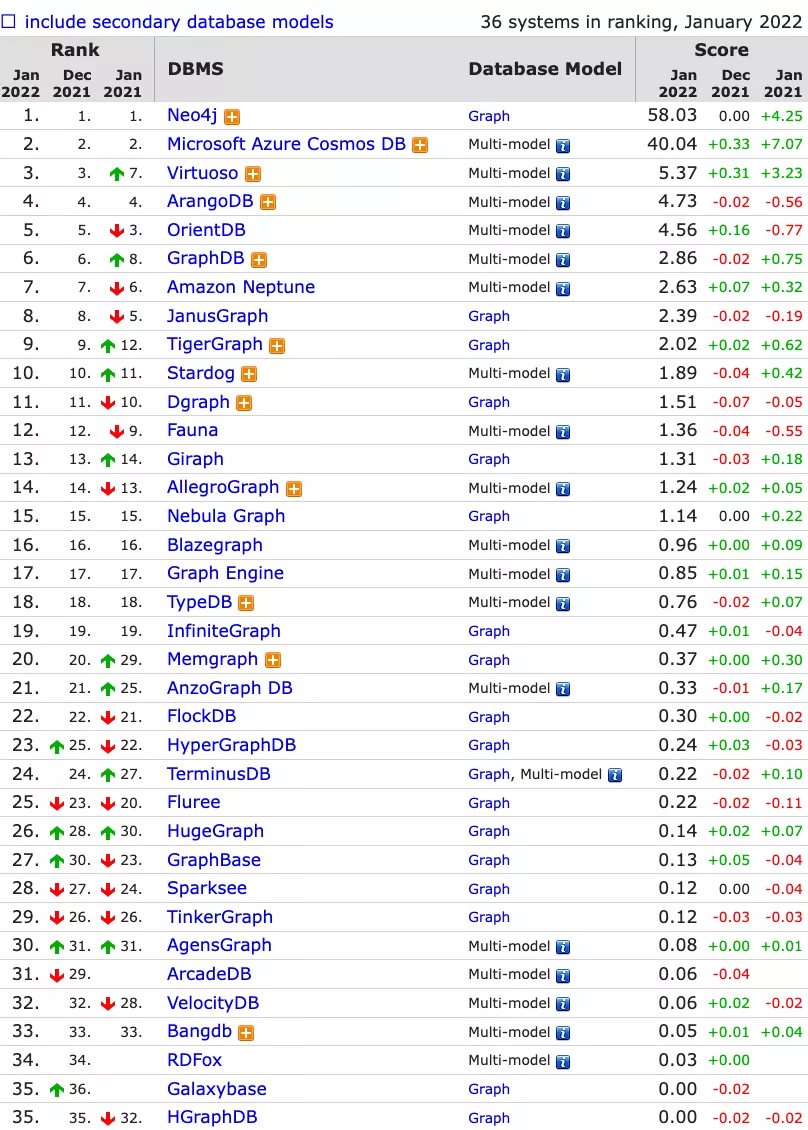
许久不见的 DB-Engines 排名 Nebula 位列第 15 名,希望下个月我们一起加油 👊
Nebula 可视化工具企业版现可申请 15 天免费试用
作为 Nebula 可视化工具“新生” Nebula Dashboard 和 Nebula Explorer 现面向 Nebula 社区开放为期 15 天的免费申请试用。下图分别为 Nebula Dashboard 和 Nebula Explorer 的酷炫截图:
- Nebula Dashboard:Nebula 集群全生命周期管理,多维度指标监控大盘,线上稳定性心中有数;
- Nebula Explorer:酷炫的图探索工具,新增 3D 视图、Snapshot 快照、Console 控制台等功能;
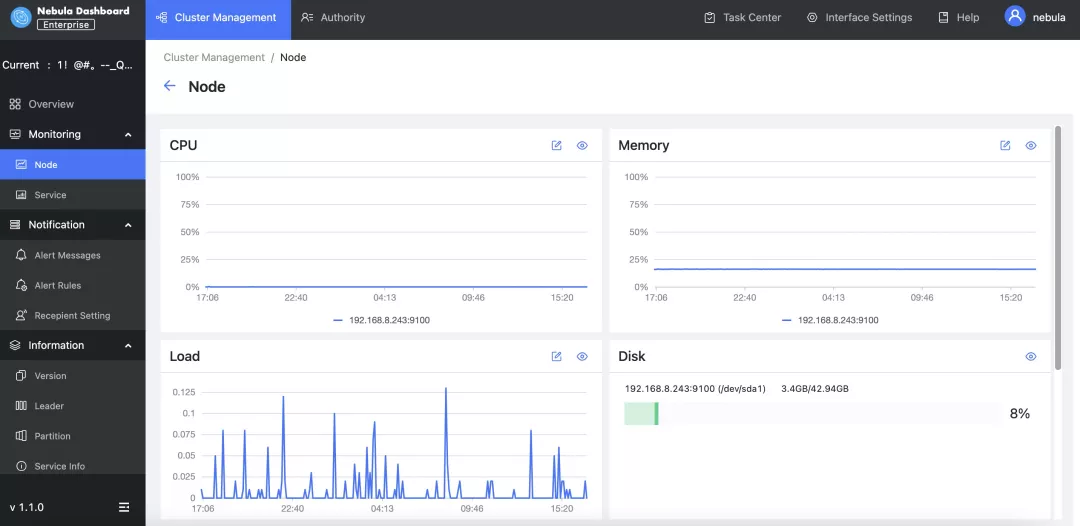
Nebula Dashboard 在线“巡逻”中

2D 版 Nebula Explorer 深藏不漏
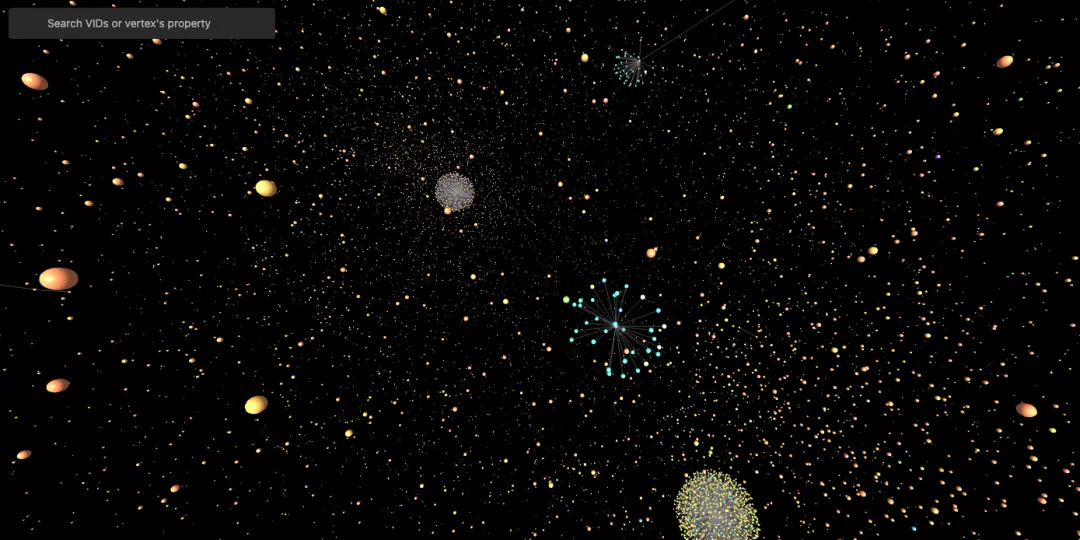
3D 版 Nebula Explorer(贼酷炫 😎 )
点击链接:
- Nebula Explorer 试用申请链接:https://wj.qq.com/s2/10158890/69a8
- Nebula Dashboard 试用申请链接:https://wj.qq.com/s2/10158890/69a8
填写申请,试用可视化产品
产品动态
本周 Nebula 主要有这些产品动态:
- #社区用户 MyHeart 贡献 💐 # 支持
LOOKUP下推 topN,标签:内核,具体 pr 见:https://github.com/vesoft-inc/nebula/pull/3499 - 压测工具 k6 升级,支持 SSL 连接,标签:
压测,具体 pr 参见:https://github.com/vesoft-inc/k6-plugin/pull/10 - 客户端支持删除查询指定参数功能,标签:
Client,具体 pr 参见:https://github.com/vesoft-inc/nebula-console/pull/127、https://github.com/vesoft-inc/nebula-java/pull/412 - 增加用户登录 Nebula 时,可输入密码尝试次数限制,标签:
内核&安全,具体 pr 参见:https://github.com/vesoft-inc/nebula/pull/3629 - 支持单进程部署 Nebula 服务,可无需单独部署 metad、graphd、storaged,标签:
内核&部署,具体 pr 参见:https://github.com/vesoft-inc/nebula/pull/3310
社区问答
Pick of the Week 每周会从官方论坛、知乎、微信群、微信公众号及开源中国等渠道精选问题同你分享。
主题分享
本周分享的主题是【Python 多线程查询】,由社区用户 Chuaco 提出,Nebula 研发解答。
“Chuaco 提问:我需要使用 Python 对 Nebula 进行多次的查询,由于单次查询速度较慢,这里准备使用多线程进行查询,不过当前所使用 threadpool 方式并没有比单纯的循环方法快出多少,请问有没有正确使用 Nebula 进行多线程查询的方法?代码如下:
def nebula_lookup_func(self, attribute):
nebula = NebulaGraph.graph
nebula_session = nebula.start_session()
nebula_session.execute("USE graph_space_name")
res = nebula_session.execute("LOOKUP ON {}".format(attribute))
nebula_session.release()
return res
def nebula_multithread_func(self):
res_store = []
attri_list = ["tag1", "tag2"]
with ThreadPoolExecutor(200) as executor:
jobs = []
results = []
for attribute in attri_list:
jobs.append(executor.submit(self.nebula_lookup_func, testclass, attribute))
for job in futures.as_completed(jobs):
result_done = job.result()
results.append(result_done)
for result in results:
res_store.append(result)
return res_store
Nebula:Python 客户端从网络中解码是比较耗 CPU 的,如果你 LOOKUP 的数据比较大,加上 Python 里的 GIL,即便是多线程,其实也没有快很多。
你可以看一下运行过程中,是不是单核已经跑满了。
另外就是网络传输是共用的,看一下是不是因为数据量大,瓶颈在网络上。
改善的话:
- 看一下是什么业务,是不是可以放 nGQL 里,比如 count 或者其他。只看语句的话,这个是扫全表了。
- 语句上加
LIMIT、WHERE。 - 多进程。(如果瓶颈在网络上,提升不明显)
Nebula 进阶技能
本周的 Nebula 进阶技能分享一个 Exchange Debug 小技巧——在生成 SST 时程序报错,提示 org.rocksdb.RocksDBException: While open a file for appending: /path/sst/1-xxx.sst: No such file or directory,该怎么办?
试试下面两个方式 debug:
- 检查 /path 是否存在
- 检查 Spark 每台机器的当前用户对 /path 是否有操作权限
推荐阅读
- 《中科大脑知识图谱平台建设及业务实践》
- 推荐理由:为了支持城市复杂场景下各类需求,中科大脑知识图谱团队设计开发了一套包含本体可视化设计、数据映射、数据抽取、数据写入、图数据探索的一体化平台,而本文则详细介绍了他们的业务背景、技术选型、平台建设等内容。
星云·小剧场
为什么给图数据库取名 Nebula?
Nebula 是星云的意思,很大嘛,也是漫威宇宙里面漂亮的星云小姐姐。对了,Nebula 的发音是:[ˈnɛbjələ]
本文星云图讲解–《M31 特写》

作为最邻近我们的大螺旋星系,处女座云气 M31 的黝黑尘埃带、明亮泛黄的核心和散布着明亮泛蓝星团的螺旋臂,都是我们很熟悉的景观。
影像提供与版权 : Daniel López / IAC
作者与编辑:Robert Nemiroff (MTU) & Jerry Bonnell (UMCP)
交流图数据库技术?加入 Nebula 交流群请先填写下你的 Nebula 名片,Nebula 小助手会拉你进群~~




