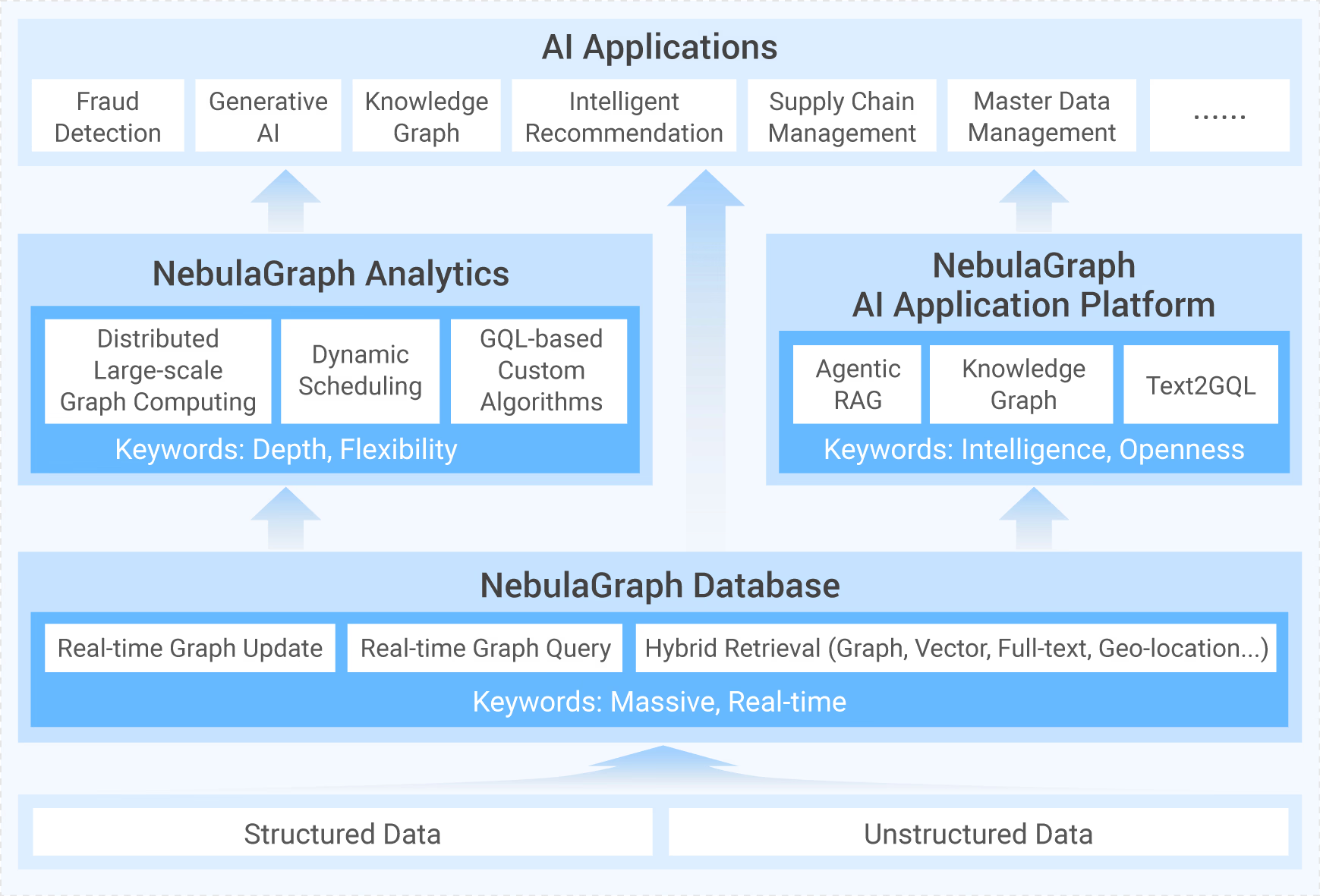
社区动态
Pick of the Week'22 |第 3 周看点:Nebula Explorer 新增 3D 查看模式

每周五 Nebula 为你播报每周看点,每周看点由固定模块:产品动态、社区问答、推荐阅读,和随机模块:本周大事件构成。
年味渐浓的一周,不知道这周你过得如何呢 🌞 出门在外记得做好防护 😷
本周看点
Nebula GitHub star 破 7k

在本周 Nebula 主仓 GitHub star 突破 7k 大关,目前 star 7051 👏👏
和 Nebula 一起交流图计算 & nebula-algorithm
图计算一直是社区热门的话题,论坛也常有小伙伴问及图算法相关问题。这次 Nebula 技术团队的两位图计算研发同学将在直播中同你交流问题。如果你有什么问题想问,记得公众号回复「提问」向两位研发同学提问,或者回复「图计算」查看活动详情。

产品动态
本周 Nebula 主要有这些产品动态:
- LDBC 测试用例增至 32 个,标签:
LDBC,具体 pr 参见:https://github.com/vesoft-inc/nebula/pull/3537 - 支持
LOOKUP聚合算子下推,标签:内核,具体 pr 参见:https://github.com/vesoft-inc/nebula/pull/3504 - K6 压测工具支持 v1.x 版本,标签:
压测,具体用法参见:https://github.com/vesoft-inc/k6-plugin/tree/nebula_v1 - Explorer 支持 3D 查看模式,标签:
可视化&Nebula Explorer,点击链接:https://wj.qq.com/s2/10158890/69a8 来申请试用体验新功能
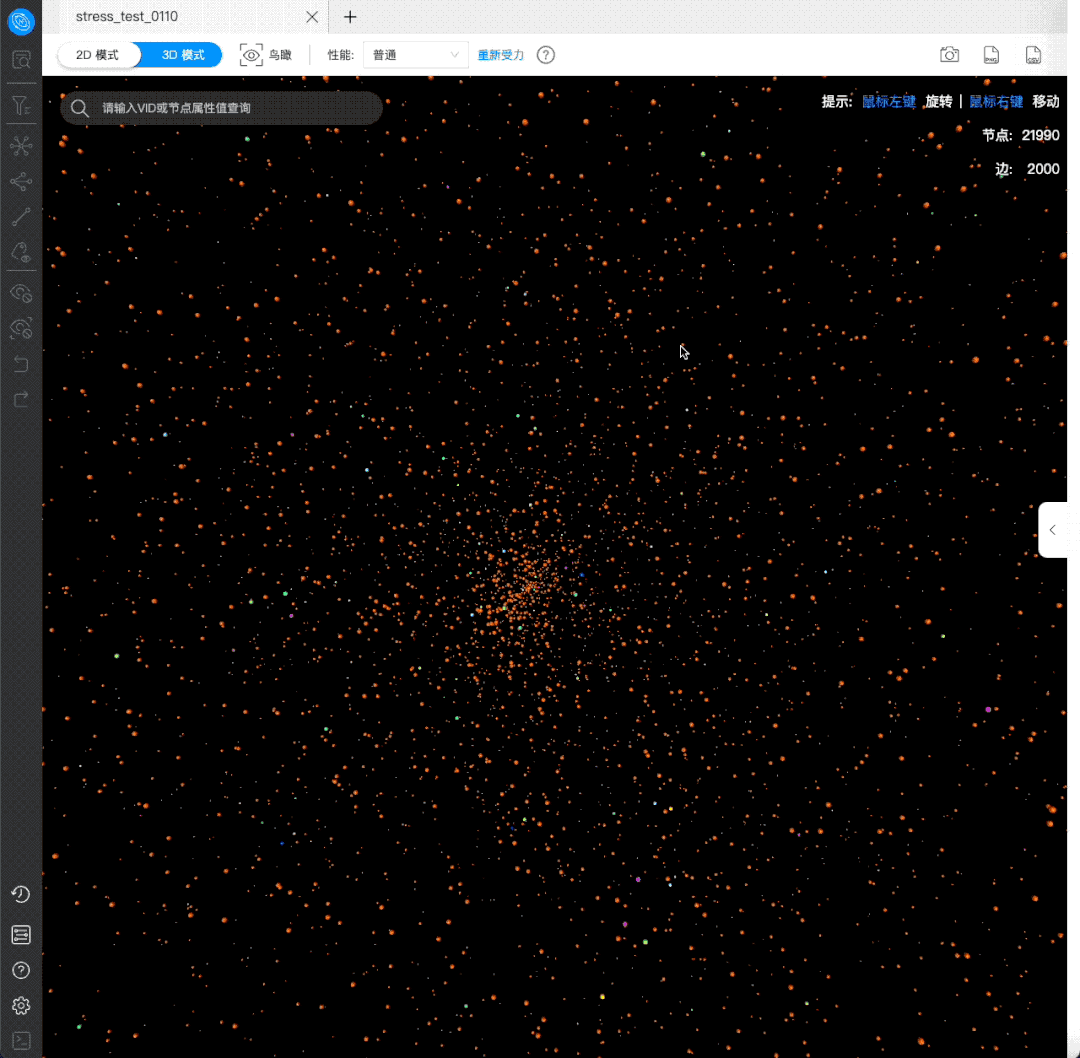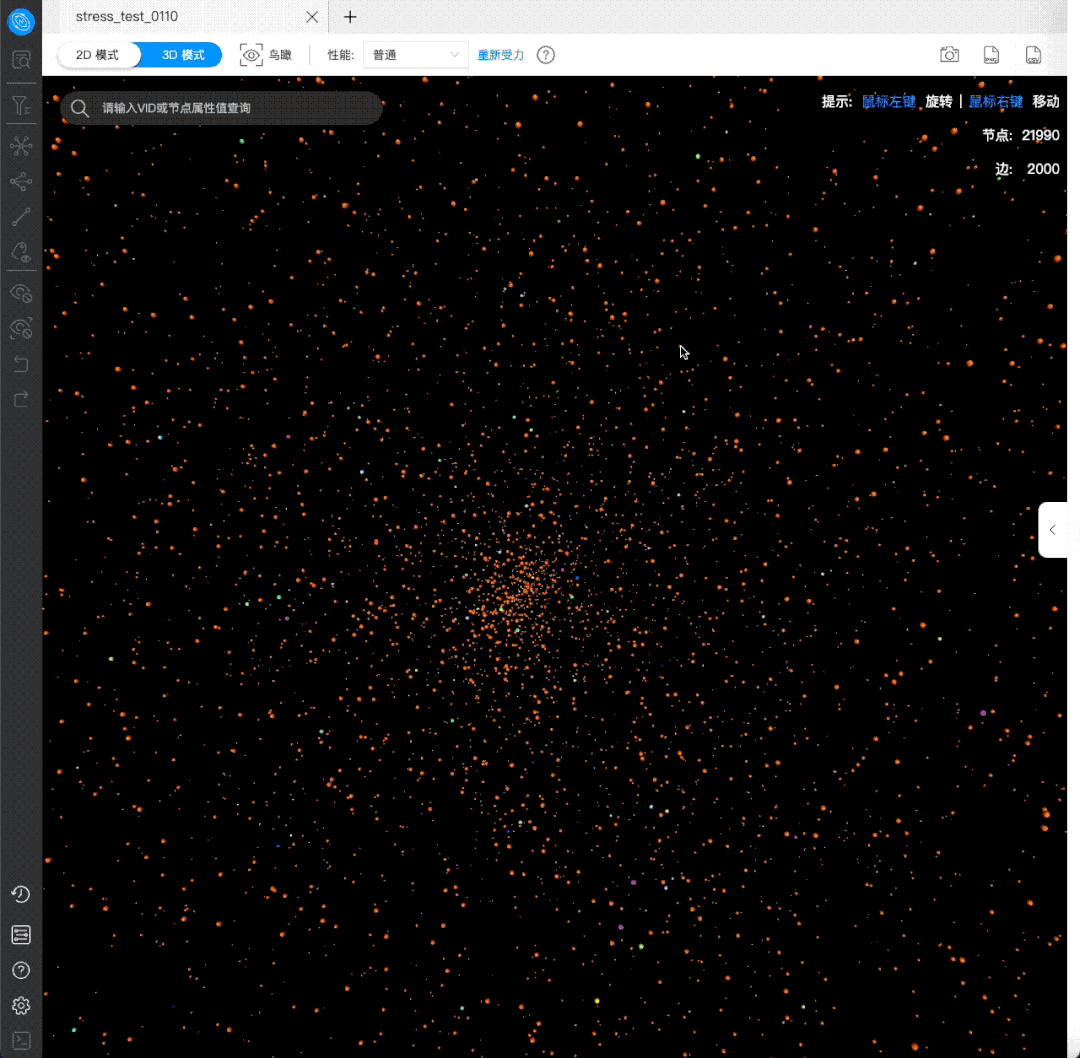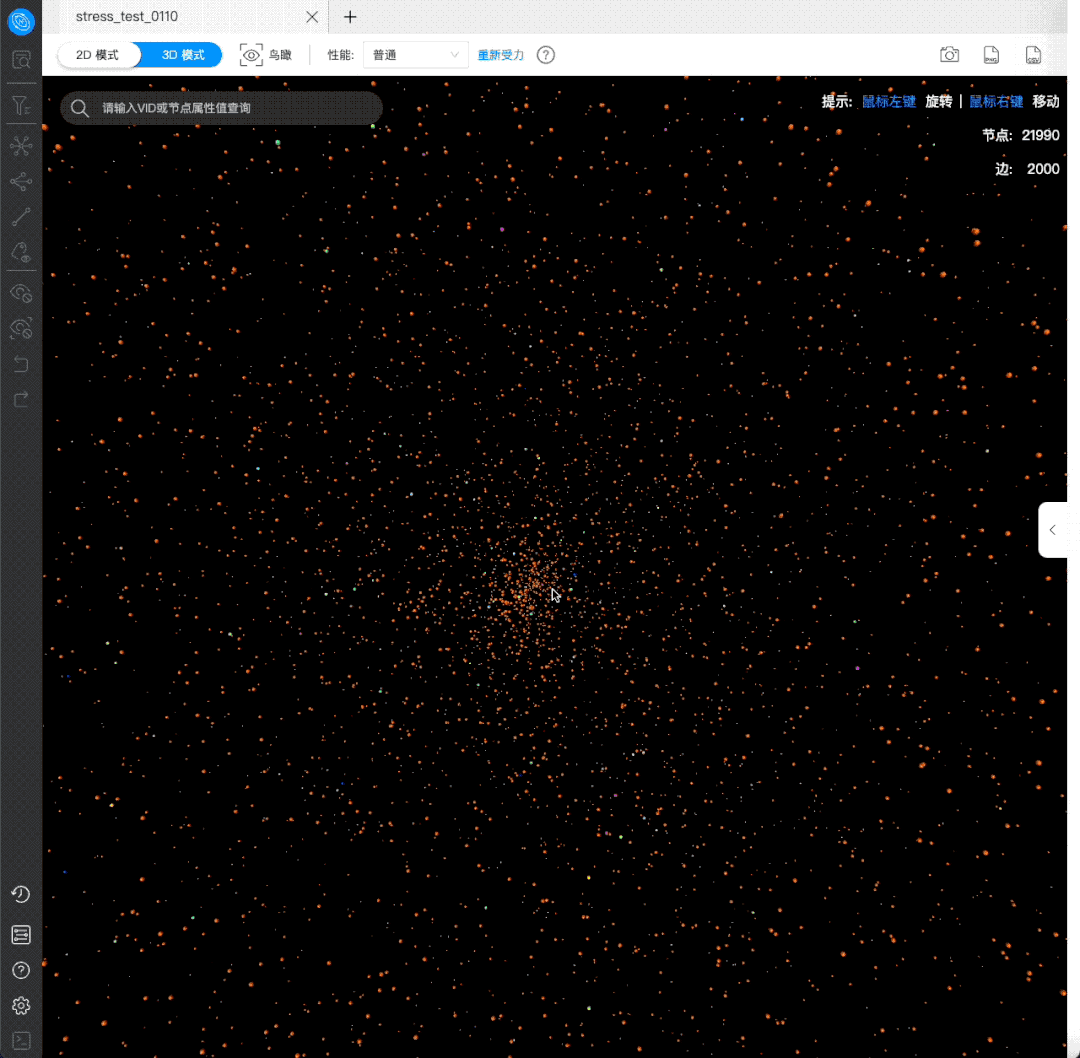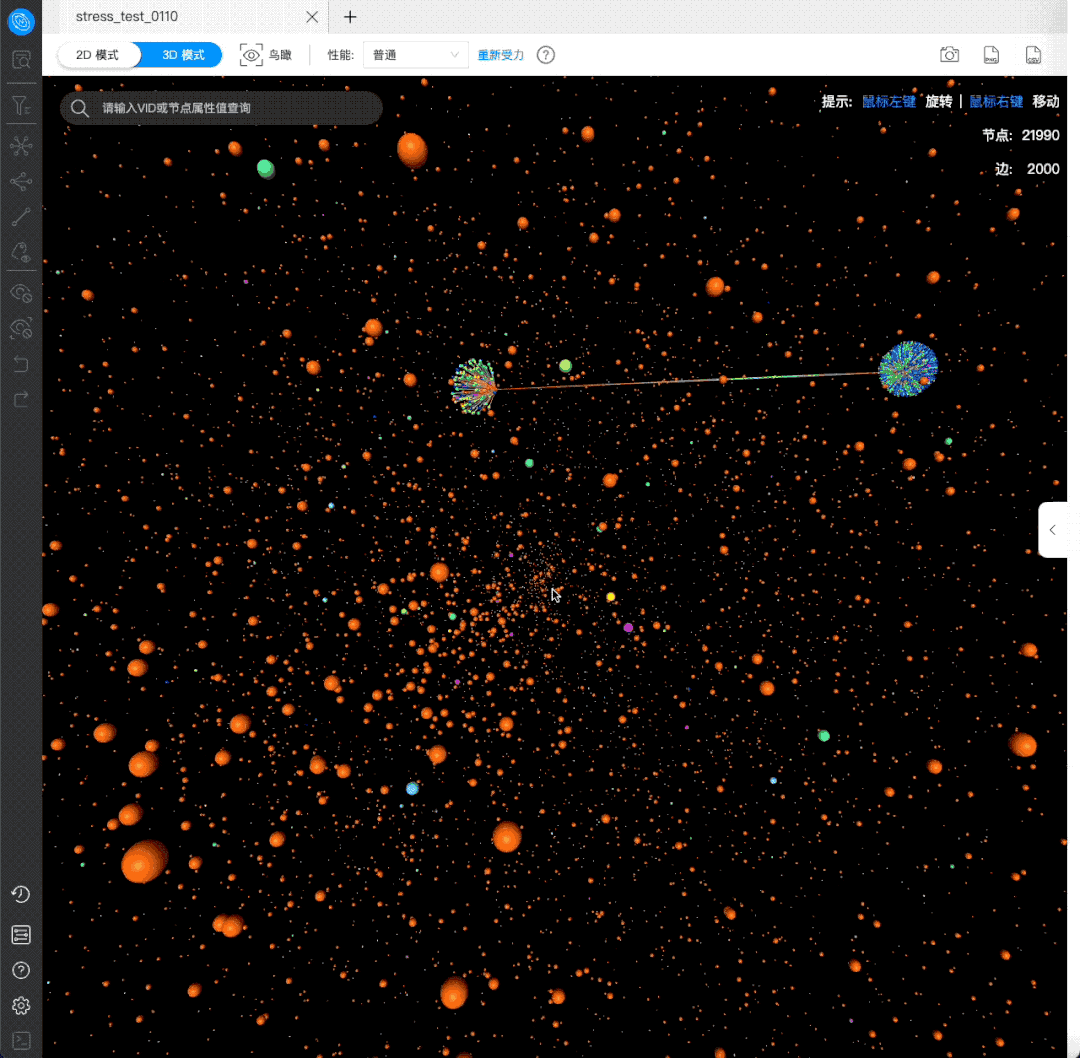
社区问答
Pick of the Week 每周会从官方论坛、知乎、微信群、微信公众号及开源中国等渠道精选问题同你分享。
主题分享
本周分享的主题是【单副本多机器的快照问题】,由社区用户 sworduo 提出,Nebula 研发解答。
sworduo 提问:假如我有一个 space,单副本 10 个 partition 分布在 3 台机器上,这时候 create snapshot 后,show snapshots 显示快照在三台机器上都有,但是实际上是不是每个机器上快照的内容都不相同?
如果是 3 副本,5 机器,创建快照。一个机器上有 partition 2 3 4 的快照,另一个机器有 3 4 5 的快照,如果我想把所有 partition 的快照集中在一起,但是每个 partition 的快照只有一个,有什么办法可以做到吗?
然而我看了 checkpoints 和 data 目录,在数据层面似乎没有记录本机有哪些 partition 的情况,这种情况下,是不是只能按照原来的拓扑结构进行恢复?
Nebula:首先解释一下你的几个问题:
- “但是实际上是不是每个机器上快照的内容都不相同?”
是的,对于 space 做一次快照后,所有的分片的快照分散在 partition 所在机器上本地,而没有收束到一个物理位置。
- “partition 的快照集中在一起,但是每个 partition 的快照只有一个,有什么办法可以做到吗?“
现在暂时没有办法,我们在做 br,能将所有 partition 快照集中在一起。但仍然是 partition 有几个副本,快照就会存储几个冗余,也即完全的物理克隆,然后收束到一块。
- “然而我看了 checkpoints 和 data 目录,在数据层面似乎没有记录本机有哪些 partition 的情况,这种情况下,是不是只能按照原来的拓扑结构进行恢复?”
是的,你理解的很对。现在恢复最大的问题就是只能按照原来的拓扑结构进行恢复。这种做法的优势在于备份和恢复速度很快,劣势在于受限于之前集群物理拓扑。
关于如何更好的备份,我们也在探讨。近期会出一个 br 工具,但是仍然是按照物理拓扑直接备份的。如果你有更好的 idea,在兼顾大数据量备份恢复速度的同时,能做到逻辑备份,欢迎来社区贡献。
追问:如果是副本数量=机器数量的情况,比如 3 副本 3 机器,是不是只需要保存一台机器上的快照就行了,因为一台机器上就含有所有的分片数据。
现在的结构我觉得快照冗余是不可避免的,因为 RocksDB 层面就没有把分区区分开来。如果想避免冗余,就得让 RocksDB 那里区分 partition,这样就可以做到每个分片只保存一份,然后根据 show hosts 的信息进行恢复。但是如果要在数据层面区分 partition,似乎就得一个 partition 启动一个 RocksDB 才行,这样看起来不太好。
另外你们有实验过 create snapshots 的速度吗,假如一个 space 有几百 g 甚至几个 T 的数据,这个命令一般耗时多少?我试过 4G 的 space,耗时 1s 多,但是不敢在线上测试。怕阻塞时间太长了影响服务。”
Nebula:回复如下:
- “是不是只需要保存一台机器上的快照就行了。”
如果都拷贝到一台机器上,得要求用户配置 ssh 免密,才能用 scp 之类的工具自动拷贝。但是如果存到对象存储等其他外存上,是可以做到的,只需要配置下对象存储的身份信息即可。这个年后会发布一款 br 工具,实现相关功能。
- “似乎就得一个 partition 启动一个 RocksDB 才行,这样看起来不太好。”
你说的很对~ 的确是首先得把同一个 space 中 partition 物理分开,才能做到去重。
- “这个命令一般耗时多少?”
这个实现上都是对 sst 和 wal 的硬链接,所以应该耗时不会太久。至于有没有测过不同量级数据的备份时间,这里可以给出一个大概上限:1T 左右的数据用时不会超过一分钟。当然用时和 partition 的数量(partition 多 sst 就多)、sst 的数量(每个做硬连接)、机器的数量(发 rpc到不同机器)呈正相关。
Nebula 进阶技能
本周的 Nebula 进阶技能分享一个稠密点处理,来源于文档:https://docs.nebula-graph.com.cn/2.6.1/8.service-tuning/super-node/。
数据库端的常见办法:
- 截断: 只访问一定阈值的边,超过该阈值的其他边则不返回。
- Compact:重新组织 RocksDB 中数据的排列方式,减少随机读,增加顺序读。
应用端的常见办法:
根据业务意义,将一些超级顶点拆分:
- 删除多条边,合并为一条
- 例如,一个转账场景:(账户 A)-[转账]->(账户 B)。每次转账建模为一条 AB 之间的边,那么(账户 A)和(账户 B)之间会有着数万十次转账的场景。按日、周、或者月为粒度,合并陈旧的转账明细。也就是批量删除陈旧的边,改为少量的边“月总额”和“次数。而保留最近月的转账明细。
- 拆分相同类型的边,变为多种不同类型的边
- 例如,(机场)<-[depart]-(航班)场景,每个架次航班的离港,都建模为一条航班和机场之间的边。那么大型机场的离港航班会极多。根据不同的航空公司将 depart 这个 Edge type 拆分更细的 Edge type,如 depart_ceair,depart_csair 等。在查询(图遍历)时,指定离港的航空公司。
- 切分顶点本身
- 例如,对于(人)-[借款]->(银行)的借款网络,某大型银行 A 的借款次数和借款人会非常的多。可以将该大行节点 A 拆分为多个相关联的子节点A1、A2、A3,
- (人 1)-[借款]->(银行 A1)、(人 2)-[借款]->(银行 A2)、(人 2)-[借款]->(银行 A3)
- (银行 A1)-[属于]->(银行 A)、(银行 A2)-[属于]->(银行 A)、(银行 A3)-[属于]->(银行 A)
- 这里的 A1、A2、A3 既可以是 A 真实的三个分行(例如北京、上海、浙江),也可以是三个按某种规则设立的虚拟分行,例如按借款金额划分 A1: 1-1000, A2: 1001-10000, A3: 10000+。这样,查询时对于 A 的任何操作,都转变为为对于 A1、A2、A3 的三次单独操作。
- 例如,对于(人)-[借款]->(银行)的借款网络,某大型银行 A 的借款次数和借款人会非常的多。可以将该大行节点 A 拆分为多个相关联的子节点A1、A2、A3,
推荐阅读
- 《Nebula 性能问题排查和性能调优》
- 推荐理由:经过多家企业验证过的性能问题排查小秘籍,一定要收藏好;
- 《泰康在线的 NebulaGraph 业务实践》
- 推荐理由:多个图数据库应用场景全解析;
- 《Write once, run anywhere | Nebula Hackathon 2021 背后的参赛者们》
- 推荐理由:用户自定义函数,让你定制化你的 Nebula 数据库。
星云·小剧场
为什么给图数据库取名 Nebula?
Nebula 是星云的意思,很大嘛,也是漫威宇宙里面漂亮的星云小姐姐。对了,Nebula 的发音是:[ˈnɛbjələ]
本文星云图讲解–《超新星遗迹─延髓星云》

CTB-1 是大约 10,000 年前,仙后座方向一颗大质量恒星发生爆炸,所形成的超新星遗迹,因为形似延髓而有延髓星云的称号,而至如今在可见光波段,仍能见到扩张碎片云冲撞周遭星际气体所发出的光。
影像提供与版权:Russell Croman 作者与编辑:Robert Nemiroff (MTU) & Jerry Bonnell (UMCP)
交流图数据库技术?加入 Nebula 交流群请先填写下你的 Nebula 名片,Nebula 小助手会拉你进群~~