
特性讲解
AI 时代的万亿关系分析计算:NebulaGraph Analytics
交流图数据库技术?加入 Nebula 交流群请先填写下「你的 Nebula 名片」,Nebula 小助手会拉你进群~~
2025 年全球图数据库市场规模为 28.5 亿美元,预计将从 2026 年的 36 亿美元增长到 2034 年的 202.9 亿美元。无论是风控、推荐,还是知识图谱,许多公司早已拥有一套图系统,数据动辄几十亿节点、上百亿关系,甚至更大。
但一个很少被公开讲出来的现实是,大多数公司的图,其实“算不动”。
经典的图算法,如 PageRank、社区发现、最短路径,已被广泛应用于生产环境。问题在于,当关系规模真的上来之后,这些算法开始变得不再工程可行,耗时太慢,或者不敢跑全量。
企业真正需要的,已经从把海量关系存下来,转向在海量关系上做计算。并且这个过程不应该再依赖研发和产品层层转译,而是让业务人员自己能制定规则,直接落地更智能、更贴近业务逻辑的分析,同时能够快速构建图算法,把效率真正提上来。
NebulaGraph Analytics,正是在这个背景下出现的。
一、在超大规模图上直接运行复杂算法
NebulaGraph Analytics 切入的核心,是让用户在超大规模图上灵活自定义复杂算法。
这是一款深度运行复杂图算法的图分析平台,相较于 Apache Spark GraphX 资源消耗降低至约 20%,计算性能提升约 5–10 倍,帮助用户高效洞察潜在的结构与模式。
其核心价值在于开放而灵活的自定义算法能力——用户不仅可以调整参数适配数据特征,更能基于业务需求编写专属算法。
为什么自定义图算法如此关键?
通用算法难以直接落地:绝大多数标准图算法无法直接解决业务问题,需要根据具体场景微调模型、参数甚至算法逻辑。
业务规则需自主可控:风控等场景涉及核心业务规则与敏感逻辑,无法交由外部厂商实现。
算法迭代速度决定风险:风险与业务模式持续变化,算法需快速迭代,等待外部开发周期往往错失最佳时机。
业务效果需紧密耦合:算法优化高度依赖业务经验反复调试,底层厂商难以承接业务效果的交付目标。
因此,能让用户自主编写自定义算法的图计算产品,才是真正契合业务需要的产品。
二、NebulaGraph Analytics 的关键能力
在大规模图计算进入生产环境后,更应该关注这些核心约束。
算法是否可扩展
计算成本是否可控
是否支持业务定制
是否能够融入现有数据体系
是否具备持续运行能力
NebulaGraph Analytics 的能力设计,正围绕这些约束展开。
1.面向业务的自定义图算法能力
在实际应用中,标准图算法往往只能覆盖一部分需求。
例如在风控、资金分析或资产关联场景中,企业通常需要结合业务规则,对算法逻辑进行扩展或重构。这类需求很难通过预置算法直接满足。
NebulaGraph Analytics 提供基于 GQL 的自定义算法能力,允许用户直接定义计算逻辑,让业务人员能够自主构建算法,无需依赖研发与产品团队,将业务规则更智能、更贴合实际地落地到图分析中。
将算法表达与图结构统一在同一语义体系内,业务人员只需聚焦业务逻辑,而非底层计算框架。
基于 GQL 语言实现,门槛远低于 C++ 等语言,业务人员仅需极小的学习成本,即可读懂、编写、修改。
结合大模型能力,提供对应的 skills,输入自然语言,直接生成可运行的算法,显著缩短算法开发、排期、上线周期,将原本数周的工作压缩至低成本、短时间完成。
避免在外部系统中重复构建计算逻辑,支持面向具体业务问题的算法高效定制。
从系统视角来看,这意味着图分析能力从调用已有算法,演进为构建面向业务的图计算模型——让算法开发回归业务本身,而非技术的复杂度。
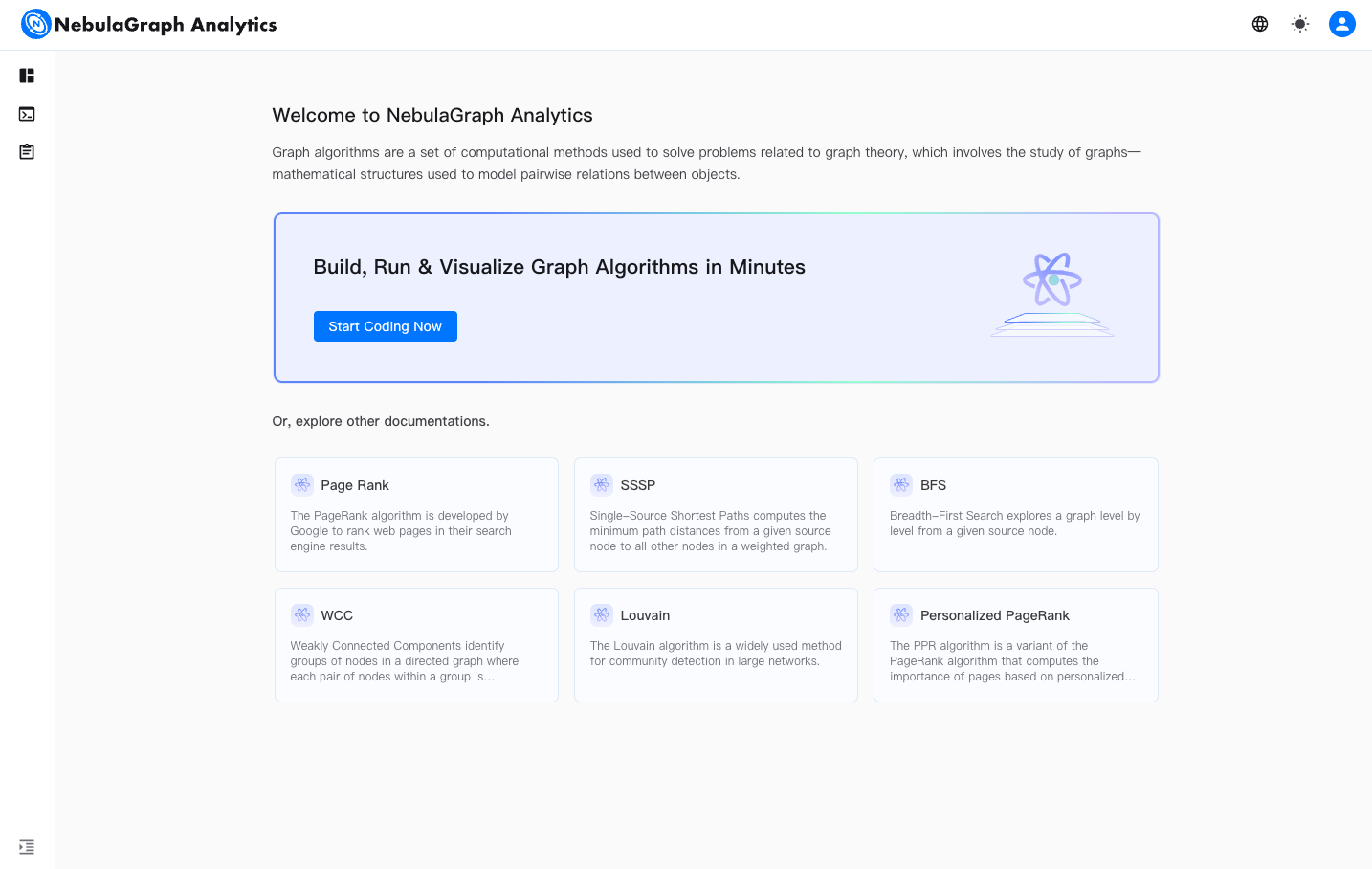
在欢迎页面,单击「立即开始」按钮,即可跳转业务开发页面,在业务开发页面中可直接创建和运行分析作业。
此外,欢迎页面还提供了常用算法的链接。单击某个算法链接,快速查看其代码实现,并通过自定义来创建自己的分析作业。
进入任务开发页面,项目面板用于管理项目和文件,编辑器面板用于编辑所选文件中的过程,以临时模式运行过程,或创建作业以定时运行过程。
2. 面向异构环境的数据接入能力
企业数据通常分布在多个存储系统中,包括图数据库、数据湖以及对象存储等。
如何在异构环境下高效接入数据,是图分析落地的前提。
NebulaGraph Analytics 提供多源数据接入能力,支持从以下数据源导入数据:
NebulaGraph 图数据库
本地存储系统
HDFS
Amazon S3
Google Cloud Storage
同时支持多种主流数据格式,包括:
CSV
Parquet
ORC
这一能力使图分析可以在不改变现有数据架构的前提下进行扩展,降低系统集成成本。从架构角度看,能高效地将图计算能力嵌入现有数据体系。
3. 面向生产环境的作业管理与调度能力
图分析在实际业务中通常不是一次性计算,而是持续运行的分析流程。
例如:
定期更新图指标(如中心性、社区结构)
持续监测异常模式
支持下游系统实时或准实时调用结果
NebulaGraph Analytics 提供可视化作业管理能力,用于:
图分析任务的开发与配置
作业执行过程管理
定时调度与自动化运行
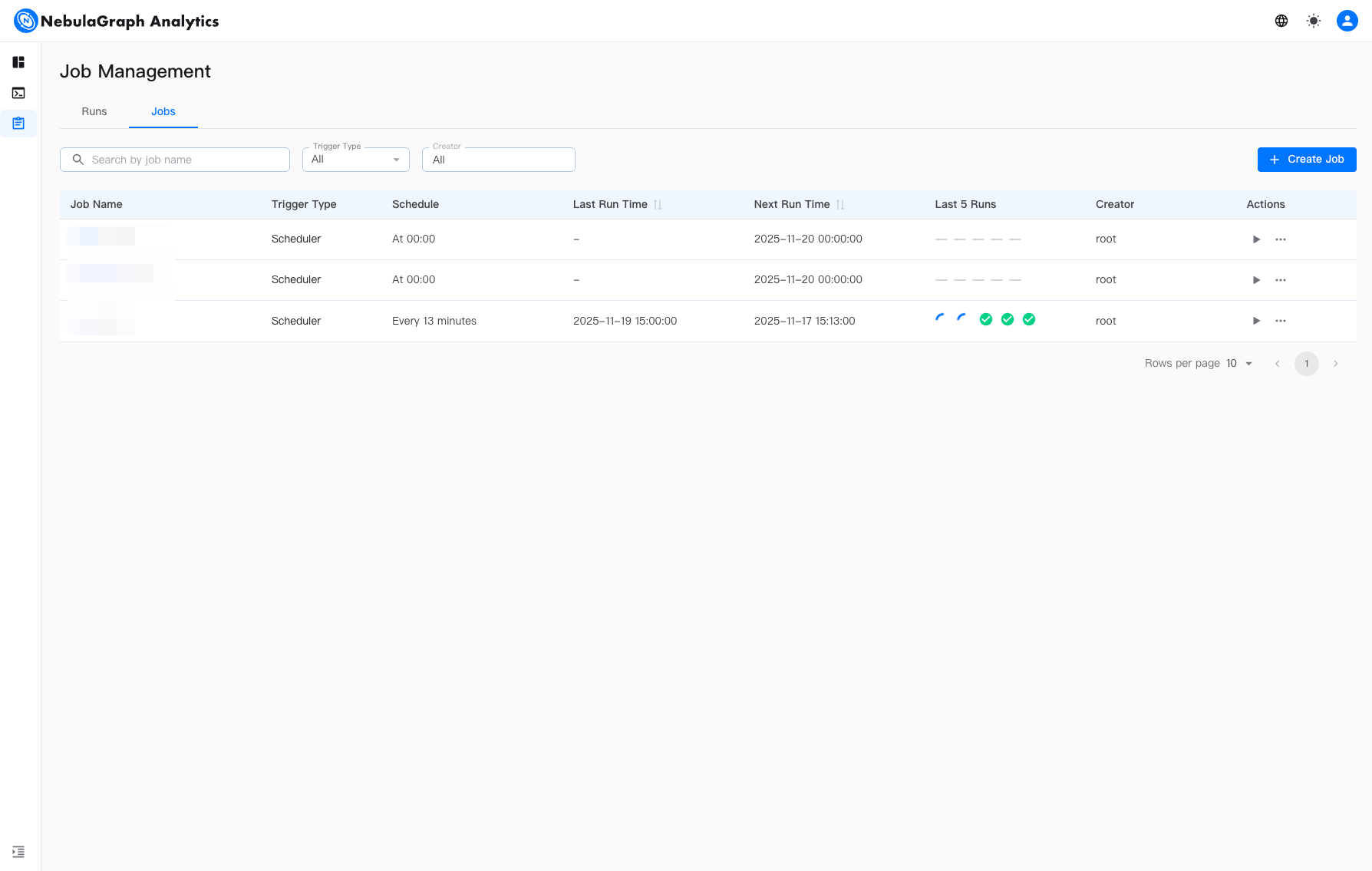
作业管理页面包含两个页签:作业和运行记录。
如上图所示,作业页签展示了所有作业。可按名称搜索作业,并按触发类型过滤作业,并对作业进行增删改查、暂停中止等作业管理工作,
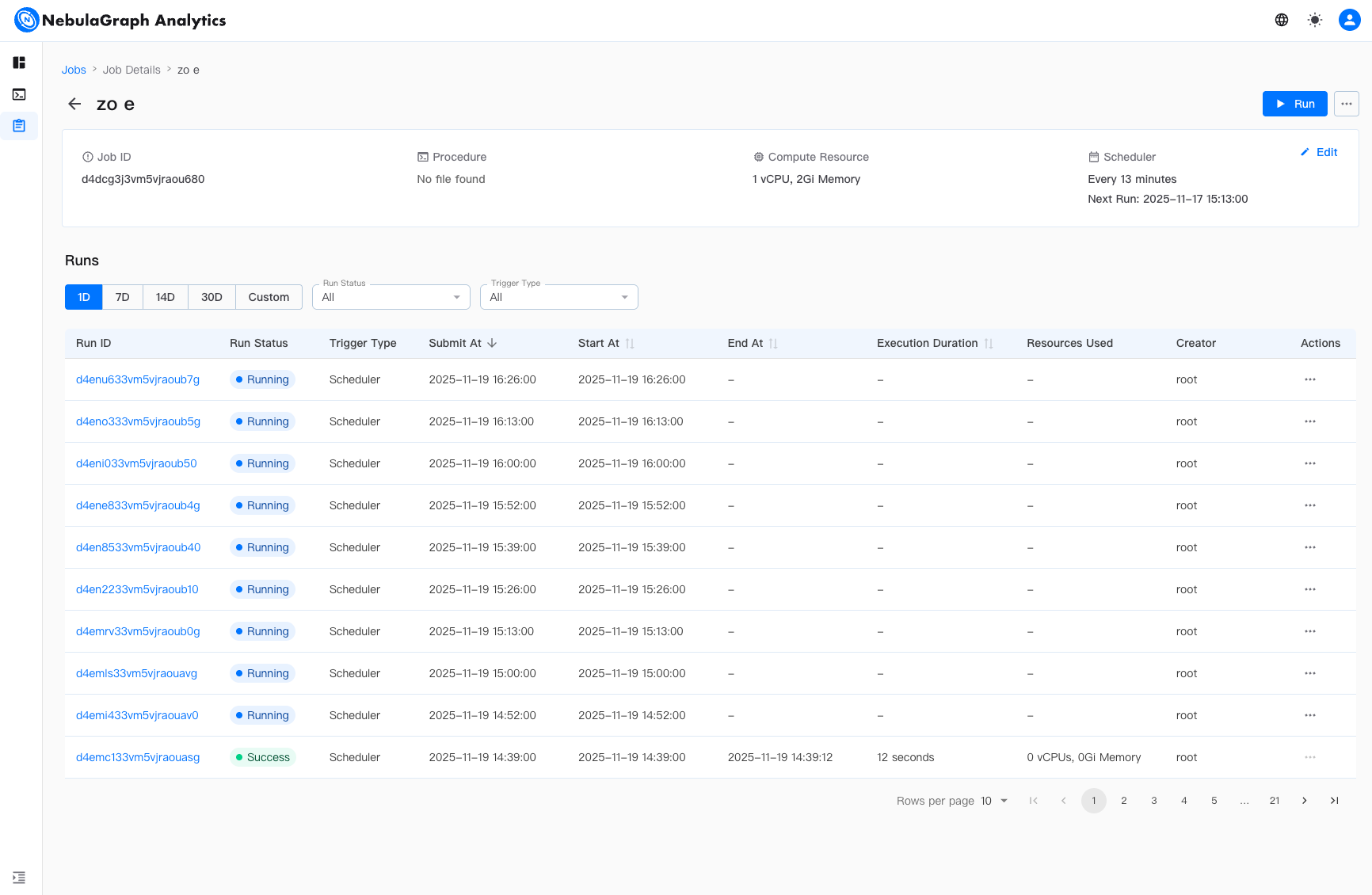
作业详情页,将提供作业 ID、过程、计算资源、定时、运行记录等信息。

运行记录页签提供运行记录,可自定义时间范围进行筛选,并支持搜索由特定作业触发的运行,或按状态或触发类型过滤运行记录。
三、NebulaGraph Analytics 的应用场景
NebulaGraph Analytics 的应用场景,本质上集中在高关系复杂度与高结构依赖的业务领域。
在用户管理中,用户价值不再只是行为结果,而是其所处关系网络的位置。通过图分析,可以识别关键影响节点和高价值群体,从而支撑更精准的运营策略。
在风险控制中,欺诈往往呈现为网络结构而非单点异常。通过社区发现、路径分析等方法,可以在全图范围内识别协同欺诈与资金链路,实现从单点识别,向结构识别的转变。
在资金与审计中,图分析可以还原复杂资金流路径,识别异常链路与关键节点,使原本难以追踪的过程具备可计算性。
而在资产管理与金融场景中,图结构则用于刻画隐性关联与风险传导路径,从而支持系统性风险评估与决策优化。
四、总结:场景化、规模化、平台化
NebulaGraph Analytics 围绕大规模图计算构建了完整的系统能力,包括:
通过自然语言自定义图算法
面向大规模数据的计算效率
对多数据源的兼容能力
可视化管理平台
当关系规模进入万亿时代,图算法的核心挑战不再是如何实现,而是如何高效计算。NebulaGraph Analytics 通过 GQL 与大模型能力的结合,显著降低了算法开发门槛,业务人员可以直接聚焦业务逻辑,将算法开发周期从数周缩短至数小时。
技术复杂度被系统吸纳,业务意图得以直达计算核心,让图算法真正成为可落地、可被业务自主驾驭的基础设施。
NebulaGraph Analytics 为企业版 5.x 全新推出的图分析平台,如需咨询更多产品性能及报价,请填写商务咨询问卷~ https://www.nebula-graph.com.cn/contact
交流图数据库技术?加入 Nebula 交流群请先填写下「你的 Nebula 名片」,Nebula 小助手会拉你进群~~




