
技术分享
别再卷大模型了:Palantir 告诉我们,AI 的进阶是“本体论”
交流图数据库技术?加入 Nebula 交流群请先填写下「你的 Nebula 名片」,Nebula 小助手会拉你进群~~
本文简要介绍本体论的起源及应用,NebulaGraph 将在 4.18 举办「Data+AI」MeetUp,由 NebulaGraph 产品专家@方扬,带来主题为「以本体论重构数据:图技术驱动 AI 理解世界」的 topic,将结合本体论对 NebulaGraph 的 AI 能力进行深度分享。戳此报名,在杭州 Office 与你共话AI~
2月 28 日,美国和以色列对伊朗发动突袭。开战 24 小时内,美军通过 Maven Smart System 识别并打击了超过 1000 个伊朗目标。在 2003 年伊拉克战争中,达成同样的战果需要 2000 名顶级情报分析师通宵达旦地从如山的报告中找线索。
Maven 系统由科技公司 Palantir 耗费 13 亿美元打造,将卫星、无人机、雷达、信号情报全线打通,分类、排序、推荐打击方案由 AI 完成。其CTO Sankar 坦言,这个高精尖武器其实就是一个哲学概念的工程化应用:本体论(Ontology)。
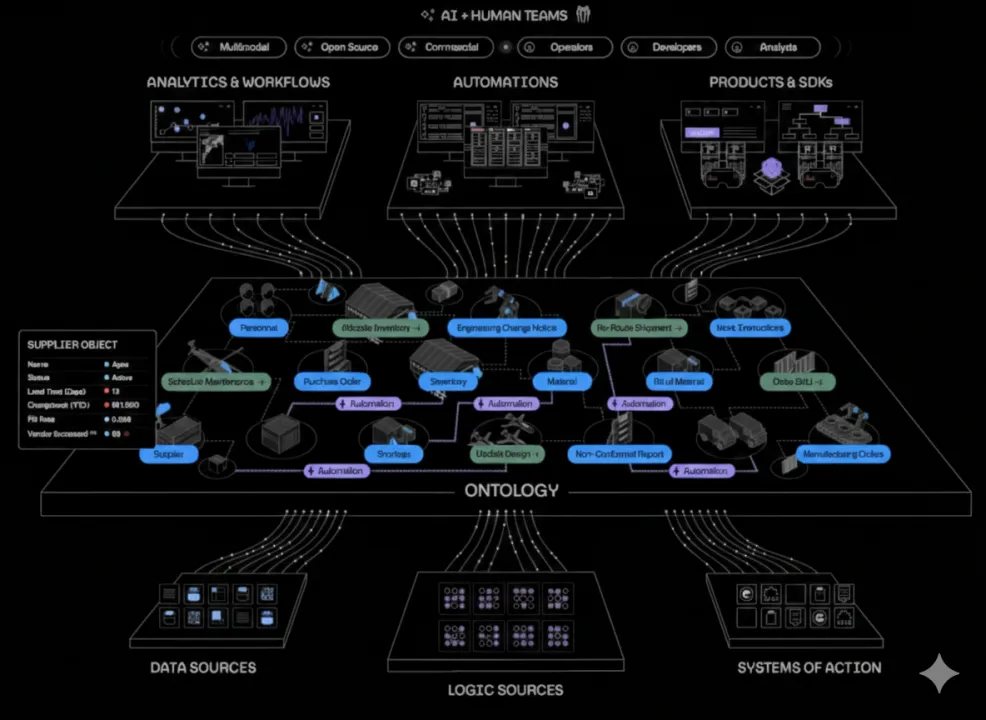
与此同时,越来越多的 AI 产品发布会上,本体论也变成了常客。
为何一个研究了 2000 多年的哲学概念,突然成了解决 AI 幻觉和构建万物互联世界的救命稻草?
一、什么是本体论?
(一)哲学的终极追问
本体论一词源于希腊语 onto(存在)和 logia(学问)。在亚里士多德看来,这是“第一哲学”。它不关心具体的物理定律,而是关心:世界上到底存在什么?这些存在的东西,彼此之间有什么关系?
想象一个简单的场景:你的桌子上有一个苹果。
物理学关心它的质量、加速度。
生物学关心它的细胞、品种。
本体论则关心:这个“苹果”是一个实体(Entity),它属于“水果”这个类(type),它具有“红色”这个属性(Property)。如果我咬了一口,它还是原来的那个“实体”吗?
(二)计算机科学的翻译官
到了 20 世纪 90 年代,人工智能专家 Tom Gruber 给出了一个著名的定义:本体是对概念化说明的显式规范。
翻译成通俗易懂的人话就是:本体论是给机器的一份世界说明书。
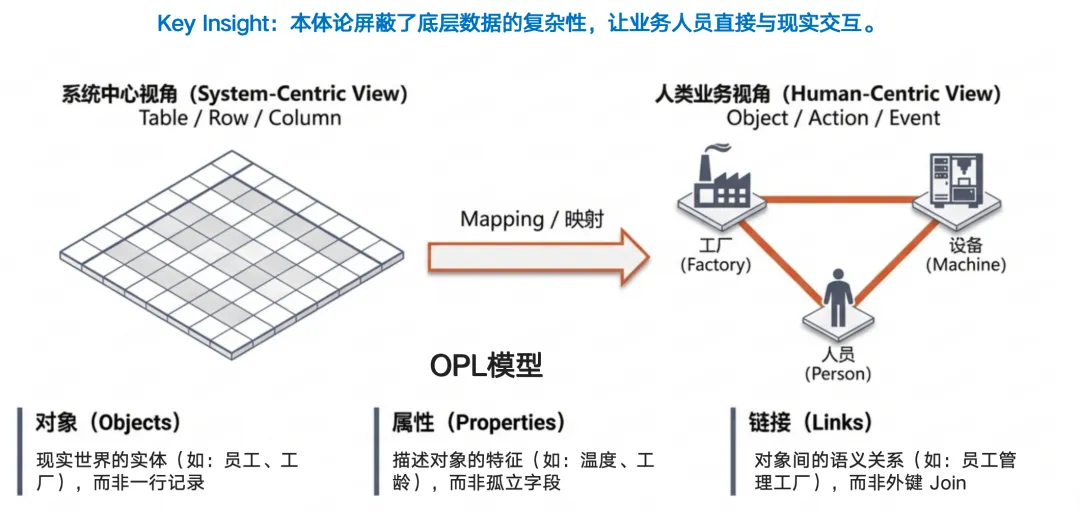
机器不像人类,它天生没有常识。你告诉机器“苹果”,它可能认为是一串二进制代码。本体论的作用,就是构建一套结构化的知识框架,告诉机器:
- 对象(Objects):定义“是什么”。可理解为说明书里的“名词大类”。它划定了世界由哪些基本对象组成。
例子:什么是“人”、什么是“公司”、什么是“城市”。
- 实体实例(Entity instance):定义“哪一个”。这是大类下的具体对象。有了类型,机器才能识别出具体的个体。
例子:在“人”类型下,具体指“张三”;在“城市”类型下,具体指“杭州”。
- 属性(Property):定义“长什么样”。这是每一个实体的特征描述,用来刻画细节。
例子:“张三”的年龄是 30 岁;“杭州”的人口是 1200 万;“公司”的注册资本是 1 亿元。
- 链接(Links):定义“怎么关联”。明确实体之间的联系方式,如“属于”、“导致”、“包含”,它把孤立的点连成网。
例子:“张三”在“NebulaGraph”上班;“NebulaGraph”的总部位于“杭州”。
- 约束(Constraints):定义“规则”。这是逻辑的边界,防止机器产生低级错误。
例子:一般情况下,一个人不能同时在两个互斥的地点上班(你不能同时出现在杭州 office ,又在美国 office);或者“一家公司的成立日期必须早于它的注销日期”。
二、为什么本体论再次出圈?

本体论可以为语义异构、知识不可复用、无法自动推理、语义网络理解、领域知识建模等问题提供解决思路,在 AI 时代,其核心价值可概括为以下两点:
(一)解决 AI 幻觉问题
比如,目前的生成式 AI(如 ChatGPT)本质上是概率预测机器。它通过上万亿个词汇的排列组合,猜出下一个字该说什么。
尴尬就在这里:概率不等于逻辑。它可能计算出“林黛玉倒拔垂杨柳”在统计学上是通顺的,但它不理解“林黛玉”这个实体的属性(柔弱)与“倒拔垂杨柳”这个动作(力量型)在本体论逻辑上是冲突的。
引入本体论后,AI 就有了一本逻辑指南。在回答问题前,它会先检索底层的知识图谱,确认实体之间的逻辑关系,从而极大地降低 AI 胡说八道的概率。
再如,传统 RAG 通过向量相似度,只做到了语义相关性检索,但本体论引入了一种确定性逻辑。
Palantir 的 Maven 系统敢应用于实战打击,是因为它在 AI 推荐方案后,会通过本体层进行逻辑验证,如:某个被标记的目标在物理规则上是否可能在 5 分钟内出现在两个地点?这种本体约束是 AI 走向高可靠性的必经之路。
(二)解决数据巴别塔难题
在《圣经》中记载了这样一个故事:人类曾想联合起来修建一座通往天堂的巴别塔,但上帝让人类突然说起了不同的语言,彼此无法沟通,最终计划失败,人群四散。巴别塔的故事,形象地展现了因缺乏通用语言或标准而导致的系统无法整合的状态。
比如,在大型企业中,财务部门有一套数据库,销售部门有一套,研发部门又有一套。同样是“客户”这个词,财务看的是“纳税人识别号”,销售看的是“联系人电话”。
再比如,在图数据库领域,在 ISO-GQL(国际标准图查询语言)未发布之前,每家厂商有各自的图查询语言,Neo4j 是 Cypher,NebulaGraph 是 nGQL,Apache TinkerPop 框架下的图遍历语言则是 Gremlin ,导致用户的学习成本和迁移成本居高不下。
这些现象正是数据孤岛的体现。而本体论提供了一套共用语言,使不同来源的数据能够基于统一的逻辑模型实现互通与理解。
三、本体论的实战工具:NebulaGraph
理论再美,也需要强大的技术底座来实现。
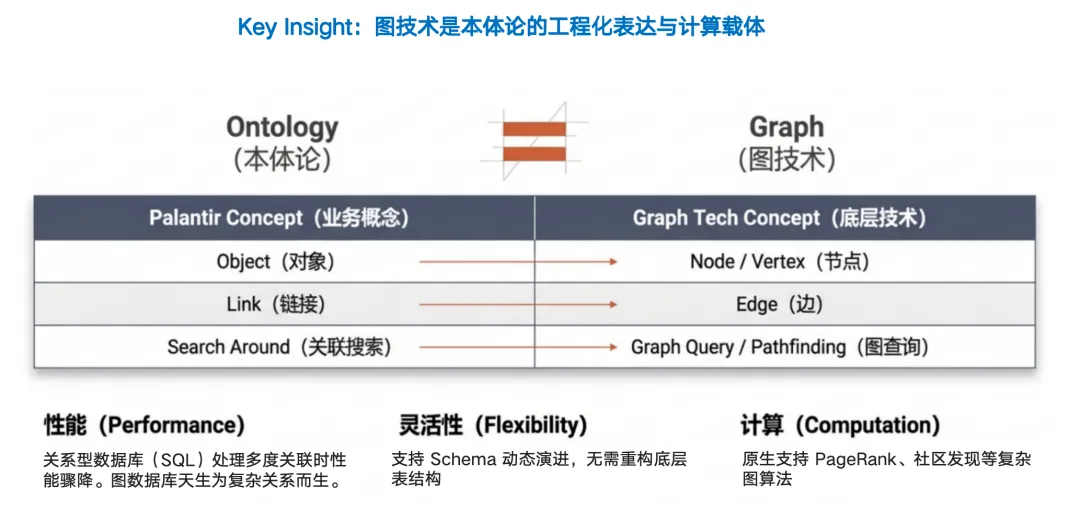
本体论强调的是“关系”,而图数据库(Graph Database)天生就是为了“关系”而生的,是本体论的完美物理映射,让本体可计算、可推理、可进化。
(一)NebulaGraph 介绍
作为开源图数据库的领军者,NebulaGraph 的出现,真正让大规模本体模型的存储和实时查询成为了可能。
1. 天然契合本体结构
在 NebulaGraph 中,数据由点(Vertex)和边(Edge)组成。点对应本体论中的“实体”,边对应“关系”。这种结构与人类大脑思考问题的方式、与本体论的建模逻辑高度统一。
2. 动态 Schema
属性灵活,可为顶点动态添加属性,非破坏性更新完美适配知识图谱中“概念”的增量演进特性;类型即约束,虽设计灵活,但其强类型的边设计,确保了关系的语义严谨性,避免关系泛滥导致的本体论失真。
3. 逻辑一致性
NebulaGraph 5.x 是首个原生支持 ISO-GQL 的图数据库,这不仅是查询语言的统一,更是本体论中“关系语义”的标准化。
4. 极致的关联查询性能
利用 NebulaGraph,可以在毫秒级完成千亿数据集的多条查询(即“朋友的朋友的朋友…”)的查询,这是传统数据库无法企及的。
5. 赋能上下文图谱
NebulaGraph 基于本体论,通过构建企业级的上下文图谱(Context Graph),作为大模型的“外挂大脑”,让 AI 理解,“过去发生了什么”,以及“为什么允许发生”,真正解决传统向量 RAG 只做检索,无法形成关键认知的难题。
(二)NebulaGraph 信贷反欺诈 Demo
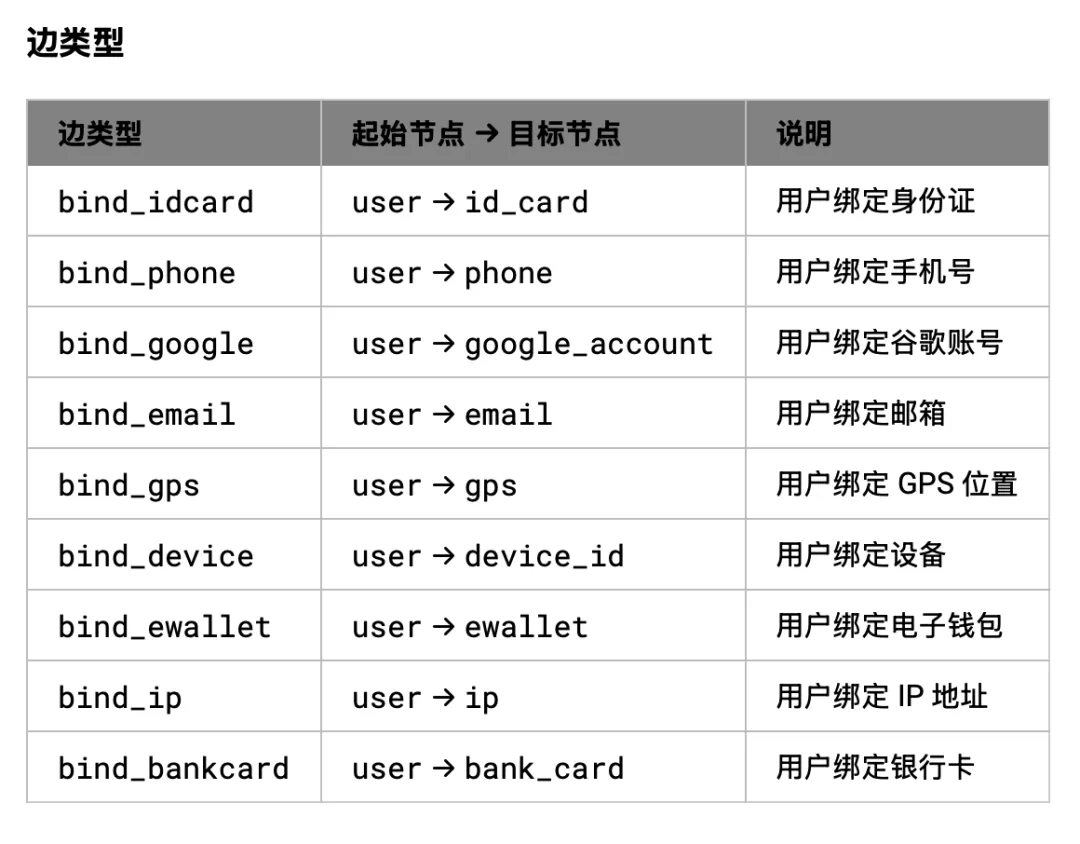
以信贷反欺诈为场景,用 NebulaGraph 建立包含用户、身份证、手机号、设备、IP 等实体的风险关联网络,帮助风控人员快速评估金融信贷欺诈风险。
1. 设计图模型
在 NebulaGraph 中,点(Vertex)用来保存实体对象,边(Edge)用来连接点,表示两个点之间的关系或行为。这与本体论的基本逻辑完全一致。

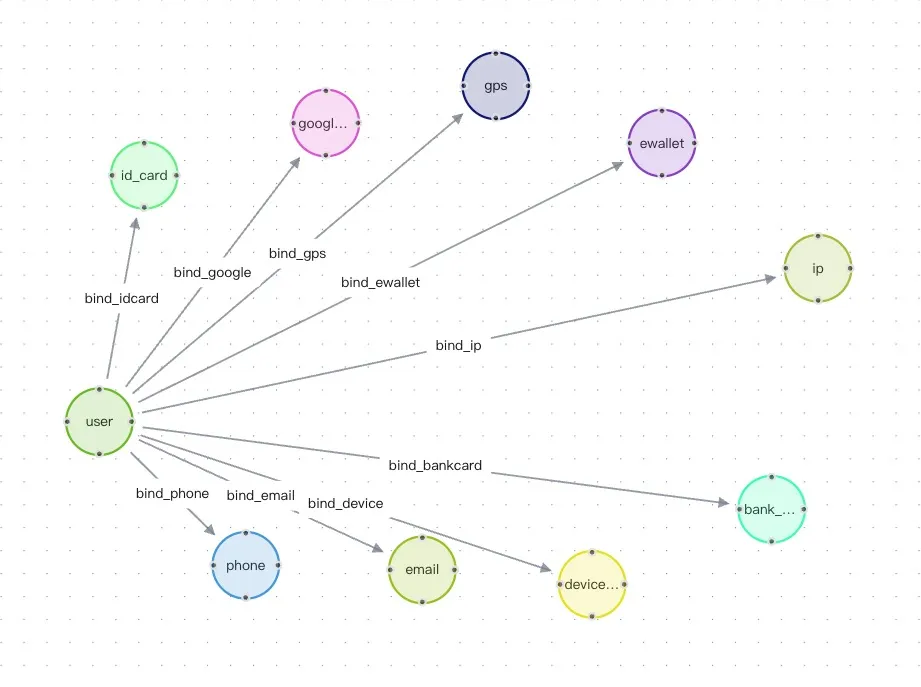
2. 创建图空间并定义点、边
先创建图类型与图空间,并执行以下语句定义节点、边结构及属性:
CREATE GRAPH TYPE IF NOT EXISTS `financial_risk_type` AS {
NODE TYPE `user` (LABEL `user`{`user_id` STRING NOT NULL, `name` STRING DEFAULT NULL, `is_blacklist` BOOL DEFAULT NULL, `is_overdue` BOOL DEFAULT NULL, `credit_limit_increase_times` INT64 DEFAULT NULL, `is_credited` BOOL DEFAULT NULL, PRIMARY KEY (`user_id`)}),
NODE TYPE `id_card` (LABEL `id_card`{`card_no` STRING NOT NULL, `is_black` BOOL DEFAULT NULL, PRIMARY KEY (`card_no`)}),
NODE TYPE `phone` (LABEL `phone`{`phone_no` STRING NOT NULL, `is_black` BOOL DEFAULT NULL, PRIMARY KEY (`phone_no`)}),
NODE TYPE `google_account` (LABEL `google_account`{`gaid` STRING NOT NULL, `is_black` BOOL DEFAULT NULL, PRIMARY KEY (`gaid`)}),
NODE TYPE `email` (LABEL `email`{`email_addr` STRING NOT NULL, `is_black` BOOL DEFAULT NULL, PRIMARY KEY (`email_addr`)}),
NODE TYPE `gps` (LABEL `gps`{`gps_coord` STRING NOT NULL, `is_black` BOOL DEFAULT NULL, PRIMARY KEY (`gps_coord`)}),
NODE TYPE `device_id` (LABEL `device_id`{`device_no` STRING NOT NULL, `is_black` BOOL DEFAULT NULL, PRIMARY KEY (`device_no`)}),
NODE TYPE `ewallet` (LABEL `ewallet`{`wallet_no` STRING NOT NULL, `is_black` BOOL DEFAULT NULL, PRIMARY KEY (`wallet_no`)}),
NODE TYPE `bank_card` (LABEL `bank_card`{`bank_no` STRING NOT NULL, `is_black` BOOL DEFAULT NULL, PRIMARY KEY (`bank_no`)}),
NODE TYPE `ip` (LABEL `ip`{`ip_addr` STRING NOT NULL, `is_black` BOOL DEFAULT NULL, PRIMARY KEY (`ip_addr`)}),
EDGE TYPE `bind_idcard` (`user`)-[LABEL `bind_idcard`{}]->(`id_card`),
EDGE TYPE `bind_phone` (`user`)-[LABEL `bind_phone`{}]->(`phone`),
EDGE TYPE `bind_google` (`user`)-[LABEL `bind_google`{}]->(`google_account`),
EDGE TYPE `bind_email` (`user`)-[LABEL `bind_email`{}]->(`email`),
EDGE TYPE `bind_gps` (`user`)-[LABEL `bind_gps`{}]->(`gps`),
EDGE TYPE `bind_device` (`user`)-[LABEL `bind_device`{}]->(`device_id`),
EDGE TYPE `bind_ewallet` (`user`)-[LABEL `bind_ewallet`{}]->(`ewallet`),
EDGE TYPE `bind_ip` (`user`)-[LABEL `bind_ewallet`{}]->(`ip`),
EDGE TYPE `bind_bankcard` (`user`)-[LABEL `bind_bankcard`{}]->(`bank_card`)
}
"""
CREATE GRAPH `financial_risk_graph` :: `financial_risk_type`
"""
3. 导入数据
使用 INSERT 语句分别导入用户、证件、设备、账户等关联数据。
-- 导入用户节点
TABLE `t` { `user_id`, `name`, `is_blacklist`, `is_overdue`, `credit_limit_increase_times`, `is_credited` } =
("u001", "张x", "FALSE", "TRUE", "2", "TRUE"),
("u002", "李x", "TRUE", "TRUE", "5", "FALSE"),
...
("u100", "吴x", "FALSE", "TRUE", "2", "FALSE")
USE `financial_risk_graph`
FOR re IN `t`
INSERT (@`user` {`user_id`: re.`user_id`, `name`: re.`name`, `is_blacklist`: CAST(re.`is_blacklist` AS BOOLEAN), `is_overdue`: CAST(re.`is_overdue` AS BOOLEAN), `credit_limit_increase_times`: CAST(re.`credit_limit_increase_times` AS INT), `is_credited`: CAST(re.`is_credited` AS BOOLEAN)})
-- 导入身份证绑定关系
TABLE `t` { `user_id`, `card_no` } =
-- 前20个用户每人绑定1-3个身份证,制造关联
("u001", "110101xxxx01010xxx"),
("u002", "110101xxxx01020xxx"),
("u002", "110101xxxx01030xxx"), -- u002绑定2个身份证
...
("u014", "110101xxxx01050xxx") -- u014共享u004的第一个身份证
USE `financial_risk_graph`
FOR re IN `t`
MATCH (v1@`user`{`user_id`: re.`user_id`}), (v2@`id_card`{`card_no`: re.`card_no`})
INSERT (v1)-[@`bind_idcard` {}]->(v2)
"""
MATCH (u:user {user_id: 'u001'}), (c:id_card {card_no: '110101198001010011'})
INSERT (u)-[:bind_idcard {}]->(c);
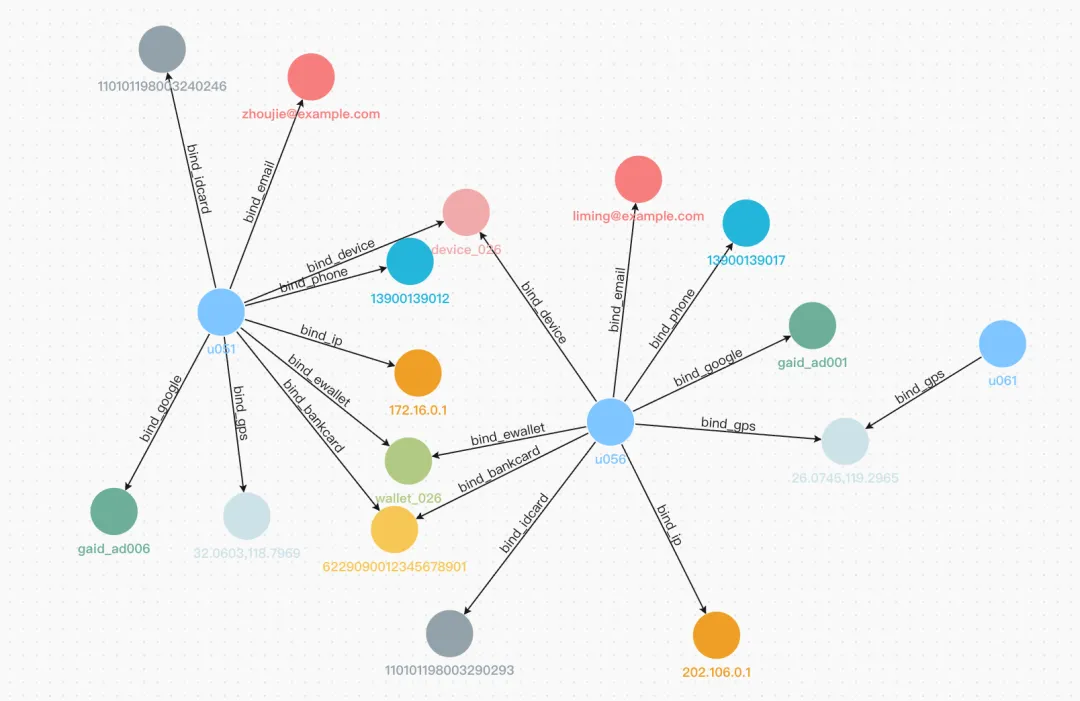
4. 进行查询
查询用户 3 跳内所有关联路径,以全面掌握目标用户的关联网络范围,发现潜在的风险传导路径。
use financial_risk_graph match p=(n@user{user_id:"u067"})-[]-{1,3}(e) return p
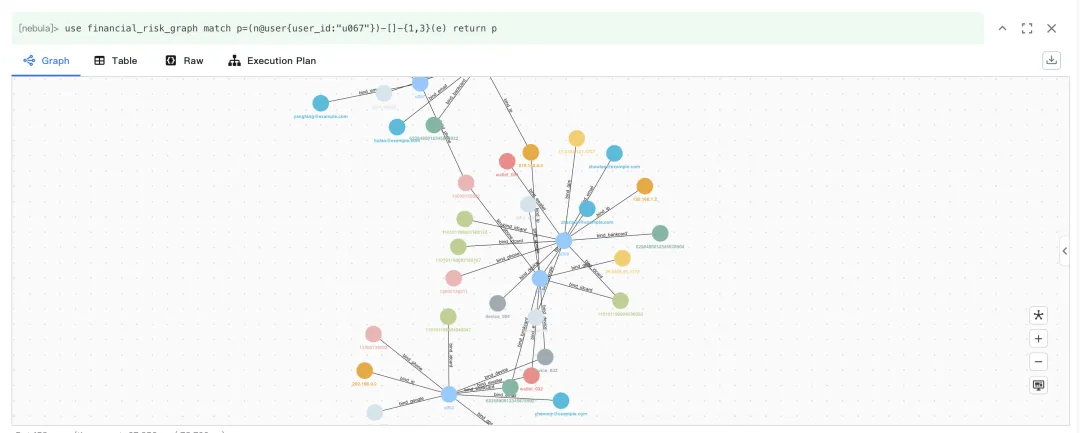
通过可视化界面,清晰展示出从用户 u067 出发,经过 1 到 3 跳能到达的所有节点及路径。
💡该 Demo 已在 NebulaGraph 官网上线,欢迎体验 https://www.nebula-graph.com.cn/posts/financial-risk-management
四、本体论如何改变我们的未来?
(一)Web3 链上分析:穿透匿名地址的马甲
在去中心化金融世界中,攻击者常通过多个看似独立的匿名地址进行洗钱或拉高出货。通过本体论建模,我们可以定义“同一实体操控”、“资金流向路径”等逻辑关系,将这些分散地址背后的真实关联网络一网打尽,让链上犯罪无所遁形。
(二)工业 4.0:数字孪生的灵魂
在波音飞机的制造中,几百万个零件之间存在着复杂的逻辑依赖。本体论可以定义零件之间的父子关系、物料清单(BOM)关系。当一个螺丝的设计发生变更,系统能通过图数据库立刻推演出这会影响到哪些传感器,甚至哪个航线的安全性。
(三)个性化医疗:精准到基因的关系网
每个人的基因、病史、用药、生活习惯都是碎片化的。通过本体论构建人体健康图谱,医生(或 AI 医生)可以发现:由于你带有某项基因特征,某种药物对你可能产生的副作用。这种深度的因果关联,只有基于本体论的图谱才能揭示。
五、结语:重构世界的秩序
本体论从两千年前的哲学辩论,演变成今天驱动 AI 的基石,说明了一个深刻的道理:世界的本质不在于孤立的数据,而在于数据之间的连接。
在这个信息爆炸、真假难辨的时代,谁能更清晰地梳理出“世界存在的方式”,谁就掌握了通往高阶智能的钥匙。
无论你是技术开发者、企业管理者,还是对世界充满好奇的观察者,拥抱本体论,其实就是拥抱一个更具逻辑、更加透明的未来。
交流图数据库技术?加入 Nebula 交流群请先填写下「你的 Nebula 名片」,Nebula 小助手会拉你进群~~




