
行业科普
以 NoSQL 和 NewSQL 为例,讲解如何分析数据模型和考量查询语言
以下文章来源于木鸟杂记 ,作者穆尼奥。

编者按:在前文《一个优秀的数据系统该具备的三个特性:可靠、可扩展、可维护》中,木鸟讲解了同数据系统相关的优秀特性。本文系《DDIA 精读小册》的第二篇,将原先的“数据模型和查询语言”章节拆分成了上下篇。本文为上篇,着重讲解同 SQL、NewSQL、NoSQL 数据库的数据模型以及其查询语言。
本文围绕两个主要概念来展开。
1. 如何分析一个数据模型:
- 基本考察点:数据基本元素,和元素之间的对应关系(一对多,多对多)
- 利用几种常用模型来比较:(最为流行的)关系模型,(树状的)文档模型,(极大自由度的)图模型。其中,图模型将作为“数据模型和查询语言”的下篇主角,和大家见面;
- schema 模式:强 Schema(写时约束);弱 Schema(读时解析)
2. 如何考量查询语言:
- 如何与数据模型关联、匹配
- 声明式(declarative)和命令式(imperative)
数据模型
“A data model is an abstract model that organizes elements of data and standardizes how they relate to one another and to the properties of real-world entities.” - 摘录自 https://en.wikipedia.org/wiki/Data_model”
数据模型:如何组织数据,如何标准化关系,如何关联现实。
它既决定了我们构建软件的方式(实现),也左右了我们看待问题的角度(认知)。
作者开篇以计算机的不同抽象层次来让大家对泛化的数据模型有个整体观感。
大多数应用都是通过不同的数据模型层级累进构建的。
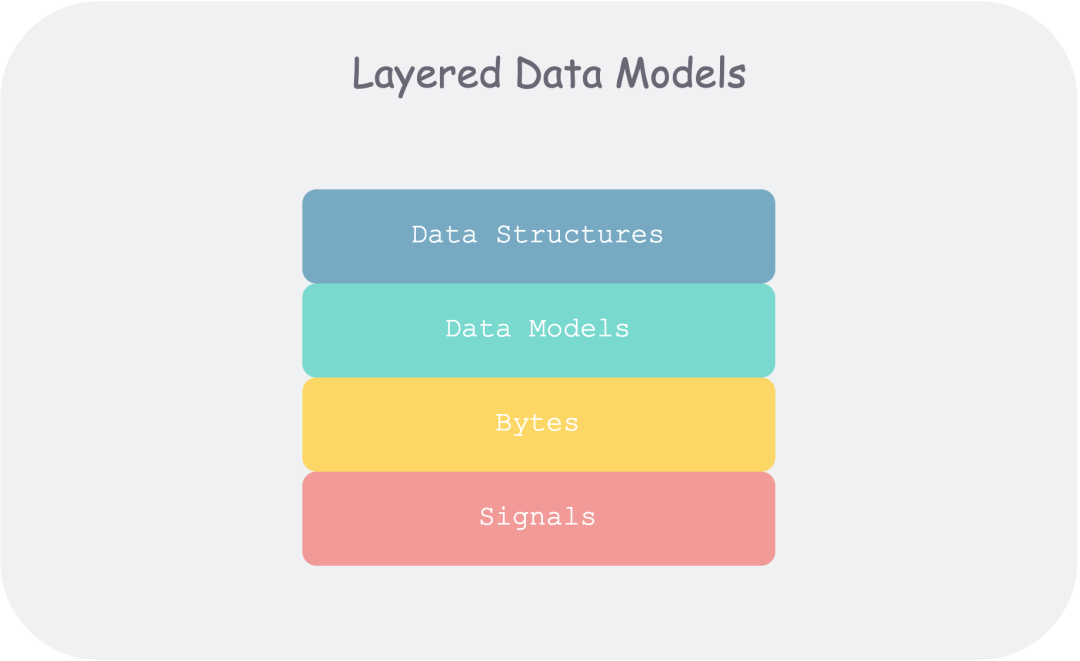
每层模型核心问题:如何用下一层的接口来对本层进行建模?
- 作为应用开发者, 你将现实中的具体问题抽象为一组对象、数据结构(data structure) 以及作用于其上的 API。
- 作为数据库管理员(DBA),为了持久化上述数据结构,你需要将他们表达为通用的数据模型(data model),如文档数据库中的 XML/JSON、关系数据库中的表、图数据库中的图。
- 作为数据库系统开发者,你需要将上述数据模型组织为内存中、硬盘中或者网络中的字节(Bytes) 流,并提供多种操作数据集合的方法。
- 作为硬件工程师,你需要将字节流表示为二极管的电位(内存)、磁场中的磁极(磁盘)、光纤中的光信号(网络)。
在每一层,通过对外暴露简洁的数据模型,我们隔离和分解了现实世界的复杂度。
这也反过来说明了,好的数据模型需有两个特点:
- 简洁直观
- 具有组合性
关系模型与文档模型
关系模型
关系模型无疑是当今最流行的数据库模型。
关系模型是 埃德加·科德(E. F. Codd)于 1969 年首先提出,并用“科德十二定律”来解释。但是商业落地的数据库基本没有能完全遵循的,因此关系模型后来通指这一类数据库。特点如下:
- 将数据以关系呈现给用户(比如:一组包含行列的二维表)。
- 提供操作数据集合的关系算子。
常见分类
- 事务型(TP):银行交易、火车票
- 分析型(AP):数据报表、监控表盘
- 混合型(HTAP)
关系模型诞生很多年后,虽有不时有各种挑战者(比如上世纪七八十年代的网状模型 network model 和层次模型 hierarchical model),但始终仍未有根本的能撼动其地位的新模型。
直到近十年来,随着移动互联网的普及,数据爆炸性增长,各种处理需求越来越精细化,催生了数据模型的百花齐放。
NoSQL 的诞生
NoSQL(最初表示 Non-SQL,后来有人转解为 Not only SQL),是对不同于传统的关系数据库的数据库管理系统的统称。根据 DB-Engines 排名,现在最受欢迎的 NoSQL 前几名为:MongoDB,Redis,ElasticSearch,Cassandra。
其催动因素有:
- 处理更大数据集:更强伸缩性、更高吞吐量
- 开源免费的兴起:冲击了原来把握在厂商的标准
- 特化的查询操作:关系数据库难以支持的,比如图中的多跳分析
- 表达能力更强:关系模型约束太严,限制太多
面向对象和关系模型的不匹配
核心冲突在于面向对象的嵌套性和关系模型的平铺性(该词是作者编造,如果有更好的翻译版,欢迎交流~)。
当然有 ORM 框架可以帮我们搞定这些事情,但仍是不太方便。

换另一个角度来说,关系模型很难直观的表示一对多的关系。比如简历上,一个人可能有多段教育经历和多段工作经历。
文档模型:使用 Json 和 XML 的天然嵌套。
关系模型:使用 SQL 模型就得将职位、教育单拎一张表,然后在用户表中使用外键关联。
在简历的例子中,文档模型还有几个优势:
- 模式灵活:可以动态增删字段,如工作经历。
- 更好的局部性:一个人的所有属性被集中访问的同时,也被集中存储。
- 结构表达语义:简历与联系信息、教育经历、职业信息等隐含一对多的树状关系可以被 JSON 的树状结构明确表达出来。
多对一和多对多
是一个对比各种数据模型的切入角度。
region 在存储时,为什么不直接存储纯字符串:“Greater Seattle Area”,而是先存为 region_id → region name,其他地方都引用 region_id?
- 统一样式:所有用到相同概念的地方都有相同的拼写和样式
- 避免歧义:可能有同名地区
- 易于修改:如果一个地区改名了,我们不用去逐一修改所有引用他的地方
- 本地化支持:如果翻译成其他语言,可以只翻译名字表。
- 更好搜索:列表可以关联地区,进行树形组织
类似的概念还有:面向抽象编程,而非面向细节。
关于用 ID 还是文本,作者提到了一点:ID 对人类是无意义的,无意义的意味着不会随着现实世界的将来的改变而改动。
这在关系数据库表设计时需要考虑,即如何控制冗余(duplication)。会有几种范式(normalization) 来消除冗余。
文档型数据库很擅长处理一对多的树形关系,却不擅长处理多对多的图形关系。如果其不支持 Join,则处理多对多关系的复杂度就从数据库侧移动到了应用侧。
如,多个用户可能在同一个组织工作过。如果我们想找出在同一个学校和组织工作过的人,如果数据库不支持 Join,则需要在应用侧进行循环遍历来 Join。
文档 vs 关系
- 对于一对多关系,文档型数据库将嵌套数据放在父节点中,而非单拎出来放另外一张表。
- 对于多对一和多对多关系,本质上,两者都是使用外键(文档引用)进行索引。查询时需要进行 join 或者动态跟随。
文档模型是否在重复历史?
层次模型 (hierarchical model)
20 世纪 70 年代,IBM 的信息管理系统 IMS。
“A hierarchical database model is a data model in which the data are organized into a tree-like structure. The data are stored as records which are connected to one another through links. A record is a collection of fields, with each field containing only one value. The type of a record defines which fields the record contains. — wikipedia”
几个要点:
- 树形组织,每个子节点只允许有一个父节点
- 节点存储数据,节点有类型
- 节点间使用类似指针方式连接
可以看出,它跟文档模型很像,也因此很难解决多对多的关系,并且不支持 Join。
为了解决层次模型的局限,人们提出了各种解决方案,最突出的是:
- 关系模型
- 网状模型
网状模型(network model)
network model 是 hierarchical model 的一种扩展:允许一个节点有多个父节点。它被数据系统语言会议(CODASYL)的委员会进行了标准化,因此也被称为 CODASYL 模型。
多对一和多对多都可以由路径来表示。访问记录的唯一方式是顺着元素和链接组成的链路进行访问,这个链路叫访问路径 (access path)。难度犹如在 n-维空间中进行导航。
内存有限,因此需要严格控制遍历路径。并且需要事先知道数据库的拓扑结构,这就意味着得针对不同应用写大量的专用代码。
关系模型
在关系模型中,数据被组织成元组(tuples),进而集合成关系(relations);在 SQL 中分别对应行(rows)和表(tables)。
- 不知道大家好奇过没,明明看起来更像表模型,为什叫关系模型?表只是一种实现。关系(relation)的说法来自集合论,指的是几个集合的笛卡尔积的子集。 R ⊆(D1×D2×D3 ··· ×Dn)(关系用符号 R 表示,属性用符号 Ai 表示,属性的定义域用符号 Di 表示)
其主要目的和贡献在于提供了一种声明式的描述数据和构建查询的方法。
即,相比网络模型,关系模型的查询语句和执行路径相解耦,查询优化器(Query Optimizer 自动决定执行顺序、要使用的索引),即将逻辑和实现解耦。
举个例子:如果想使用新的方式对你的数据集进行查询,你只需要在新的字段上建立一个索引。那么在查询时,你并不需要改变的你用户代码,查询优化器便会动态的选择可用索引。
文档型 vs 关系型
根据数据类型来选择数据模型
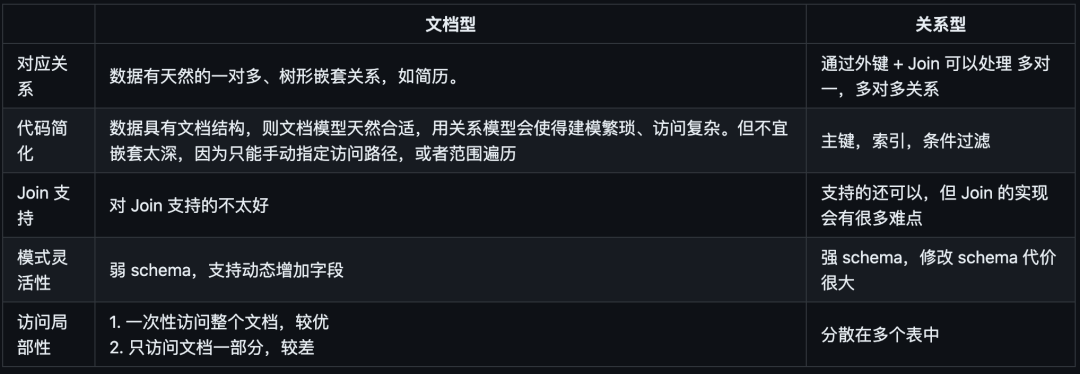
对于高度关联的数据集,使用文档型表达比较奇怪,使用关系型可以接受,使用图模型最自然。
文档模型中 Schema 的灵活性
说文档型数据库是 schemaless 不太准确,更贴切的应该是 schema-on-read。

文档型数据库使用场景特点:
- 有多种类型的数据,但每个放一张表又不合适。
- 数据类型和结构又外部决定,你没办法控制数据的变化。
查询时的数据局部性
如果你同时需要文档中所有内容,把文档顺序存会效率比较高。
但如果你只需要访问文档中的某些字段,则文档仍需要将文档全部加载出。
但运用这种局部性不局限于文档型数据库。不同的数据库,会针对不同场景,调整数据物理分布以适应常用访问模式的局部性。
- 如 Spanner 中允许表被声明为嵌入到父表中——常见关联内嵌
- HBase 和 Cassandra 使用列族来聚集数据——分析型
- 图数据库中,将点和出边存在一个机器上——图遍历
关系型和文档型的融合
- MySQL 和 PostgreSQL 开始支持 JSON。原生支持 JSON 可以理解为,MySQL 可以理解 JSON 格式。如 Date 格式一样,可以把某个字段作为 JSON 格式,可以修改其中的某个字段,可以在其中某个字段建立索引。
- RethinkDB 在查询中支持 relational-link Joins
科德(Codd):nonsimple domains,记录中的值除了简单类型(数字、字符串),还可以一个嵌套关系(表)。这很像 SQL 对 XML、JSON 的支持。
数据查询语言
获取动物表中所有鲨鱼类动物。
function getSharks() {
var sharks = [];
for (var i = 0; i < animals.length; i++) {
if (animals[i].family === 'Sharks') {
sharks.push(animals[i]);
}
}
return sharks;
}
SELECT * FROM animals WHERE family = 'Sharks';
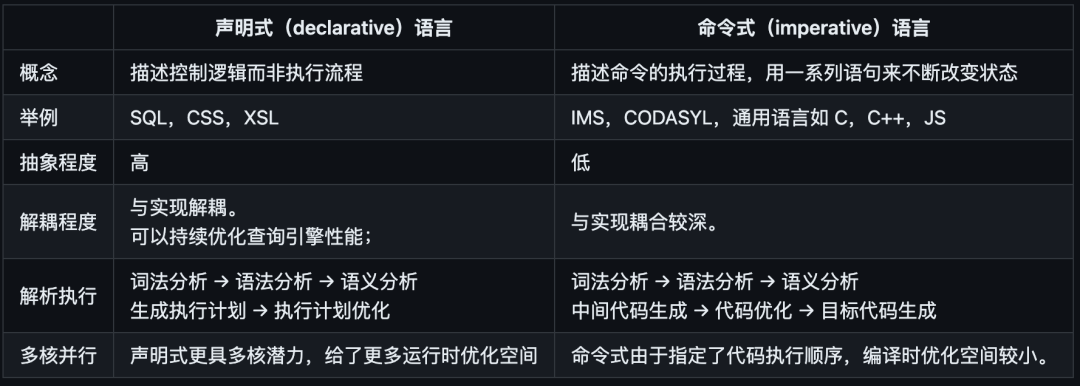
Q:相对声明式语言,命令式语言有什么优点?
当描述的目标变得复杂时,声明式表达能力不够。
实现命令式的语言往往不会和声明式那么泾渭分明,通过合理抽象,通过一些编程范式(函数式),可以让代码兼顾表达力和清晰性。
数据库以外:Web 中的声明式
需求:选中页背景变蓝。
<ul>
<li class="selected">
<p>Sharks</p>
<ul>
<li>Great White Shark</li>
<li>Tiger Shark</li>
<li>Hammerhead Shark</li>
</ul>
</li>
<li>
<p>Whales</p>
<ul>
<li>Blue Whale</li>
<li>Humpback Whale</li>
<li>Fin Whale</li>
</ul>
</li>
</ul>
如果使用 CSS,则只需(CSS selector):
li.selected > p {
background-color: blue;
}
如果使用 XSL,则只需(XPath selector):
<xsl:template match="li[@class='selected']/p">
<fo:block background-color="blue">
<xsl:apply-templates/>
</fo:block>
</xsl:template>
但如果使用 JavaScript(而不借助上述 selector 库):
var liElements = document.getElementsByTagName('li');
for (var i = 0; i < liElements.length; i++) {
if (liElements[i].className === 'selected') {
var children = liElements[i].childNodes;
for (var j = 0; j < children.length; j++) {
var child = children[j];
if (child.nodeType === Node.ELEMENT_NODE && child.tagName === 'P') {
child.setAttribute('style', 'background-color: blue');
}
}
}
}
MapReduce 查询
Google 的 MapReduce 模型
- 借鉴自函数式编程。
- 一种相当简单的编程模型,或者说原子的抽象,现在不太够用。
- 但在大数据处理工具匮乏的蛮荒时代(03 年以前),谷歌提出的这套框架相当有开创性。
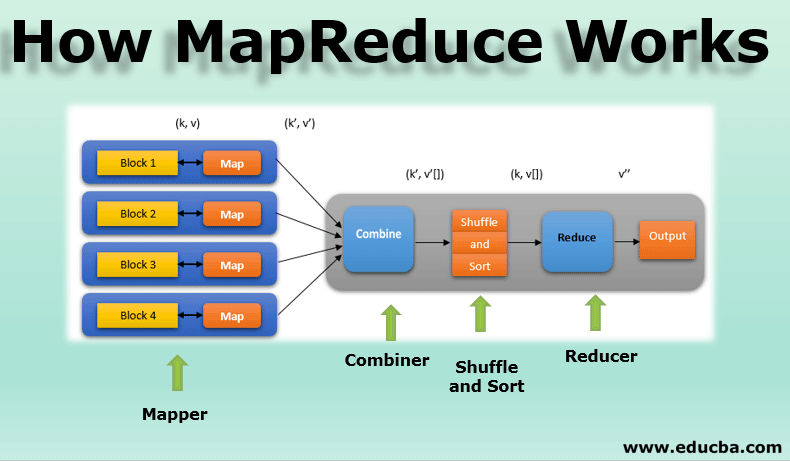
MongoDB 的 MapReduce 模型
MongoDB 使用的 MapReduce 是一种介于
- 声明式:用户不必显式定义数据集的遍历方式、shuffle 过程等执行过程。
- 命令式:用户又需要定义针对单条数据的执行过程。
两者间的混合数据模型。
需求:统计每月观察到鲨类鱼的次数。
查询语句:
PostgresSQL
SELECT date_trunc('month', observation_timestamp) AS observation_month,
sum(num_animals) AS total_animals
FROM observations
WHERE family = 'Sharks' GROUP BY observation_month;
MongoDB
db.observations.mapReduce(
function map() {
// 2. 对所有符合条件 doc 执行 map
var year = this.observationTimestamp.getFullYear();
var month = this.observationTimestamp.getMonth() + 1;
emit(year + '-' + month, this.numAnimals); // 3. 输出一个 kv pair
},
function reduce(key, values) {
// 4. 按 key 聚集
return Array.sum(values); // 5. 相同 key 加和
},
{
query: { family: 'Sharks' }, // 1. 筛选
out: 'monthlySharkReport', // 6. reduce 结果集
}
);
上述语句在执行时,经历了:筛选 → 遍历并执行 map → 对输出按 key 聚集(shuffle) → 对聚集的数据注意 reduce → 输出结果集。
MapReduce 一些特点:
- 要求 Map 和 Reduce 是纯函数。即无任何副作用,在任意地点、以任意次序执行任何多次,对相同的输入都能得到相同的输出。因此容易并发调度。
- 非常底层、但表达力强大的编程模型。可基于其实现 SQL 等高级查询语言,如 Hive。
但要注意:
- 不是所有的分布式 SQL 都基于 MapReduce 实现。
- 不是只有 MapReduce 才允许嵌入通用语言(如 js)模块。
- MapReduce 是有一定理解成本的,需要熟悉其执行逻辑才能让两个函数紧密配合。
MongoDB 2.2+ 进化版,aggregation pipeline:
db.observations.aggregate([
{ $match: { family: 'Sharks' } },
{
$group: {
_id: {
year: { $year: '$observationTimestamp' },
month: { $month: '$observationTimestamp' },
},
totalAnimals: { $sum: '$numAnimals' },
},
},
]);
谢谢你读完本文(///▽///)
如果你想尝鲜图数据库 NebulaGraph,记得去 GitHub 下载、使用、(^з^)-☆ star 它 -> GitHub;如果你有更高的性能、易用性、运维实施等方面的需求,你也可以随时 联系我们,获取进一步的帮助哦~



