
社交推荐 Demo 使用教程
交流图数据库技术?加入 Nebula 交流群请先填写下「你的 Nebula 名片」,Nebula 小助手会拉你进群~~
⚠️本文档中的图模型(点、边及属性)主要为演示图数据库在社交场景下的表达能力而设计,实际业务中可根据数据规模与查询需求按需简化或扩展。 如社区(Community)通常可作为用户的属性字段存储,此处将其建模为独立节点,是为了更直观地展示「用户–社群–内容」之间的多跳关系与图谱结构。 请勿直接照搬上述 Schema 作为生产环境定义,建议结合实际业务与数据量进行合理设计~
背景
在社交媒体与内容平台中,信息过载是普遍挑战。传统的基于流行度或协同过滤的推荐系统,往往忽略了用户之间复杂的社交关系、兴趣传导和影响力路径,导致推荐结果缺乏个性化和解释性。
图数据库能够将用户、内容、社群、标签等实体以及它们之间的好友、关注、互动等关系构建成一个动态的兴趣社交网络,并通过图遍历和路径分析挖掘潜在的兴趣社群、识别内容传播路径,从而生成更精准、更具社交说服力的推荐。
本 Demo 以社交推荐为场景,建立包含用户、内容、社群、标签等实体的兴趣关联网络,并演示多种图查询,帮助产品与算法人员快速构建和验证社交推荐逻辑。
图模型设计
💡在实际使用场景中,可对 Schema 进行相应修改与管理,为便于在线体验本 Demo 暂不支持。
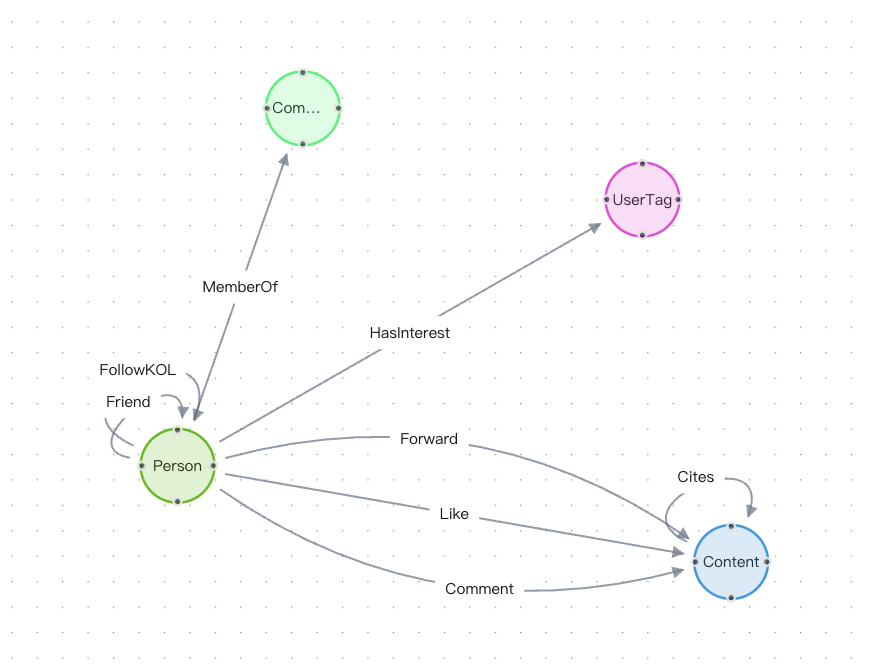
首先创建图类型与图空间,并执行以下语句定义节点、边结构及属性:
CREATE GRAPH TYPE IF NOT EXISTS `social_recommendation` AS {
NODE TYPE `Person` (LABEL `Person`{`person_id` STRING NOT NULL, `name` STRING DEFAULT NULL, `city` STRING DEFAULT NULL, `register_time` ZONED DATETIME DEFAULT NULL, PRIMARY KEY (`person_id`)}),
NODE TYPE `Community` (LABEL `Community`{`community_id` STRING NOT NULL, `name` STRING DEFAULT NULL, `topic` STRING DEFAULT NULL, `created_time` ZONED DATETIME DEFAULT NULL, PRIMARY KEY (`community_id`)}),
NODE TYPE `Content` (LABEL `Content`{`content_id` STRING NOT NULL, `title` STRING DEFAULT NULL, `category` STRING DEFAULT NULL, `publish_time` ZONED DATETIME DEFAULT NULL, PRIMARY KEY (`content_id`)}),
NODE TYPE `UserTag` (LABEL `UserTag`{`tag_name` STRING NOT NULL, PRIMARY KEY (`tag_name`)}),
EDGE TYPE `Friend` (`Person`)-[LABEL `Friend`{`since_time` ZONED DATETIME NOT NULL, `closeness` DOUBLE DEFAULT NULL, MULTIEDGE KEY(`since_time`)}]->(`Person`),
EDGE TYPE `MemberOf` (`Person`)-[LABEL `MemberOf`{`join_time` ZONED DATETIME NOT NULL, `role_name` STRING DEFAULT NULL, MULTIEDGE KEY(`join_time`)}]->(`Community`),
EDGE TYPE `Forward` (`Person`)-[LABEL `Forward`{`forward_time` ZONED DATETIME NOT NULL, `action_weight` DOUBLE DEFAULT NULL, MULTIEDGE KEY(`forward_time`)}]->(`Content`),
EDGE TYPE `Like` (`Person`)-[LABEL `Like`{`like_time` ZONED DATETIME NOT NULL, `score` DOUBLE DEFAULT NULL, MULTIEDGE KEY(`like_time`)}]->(`Content`),
EDGE TYPE `Comment` (`Person`)-[LABEL `Comment`{`comment_time` ZONED DATETIME NOT NULL, `content_text` STRING DEFAULT NULL, MULTIEDGE KEY(`comment_time`)}]->(`Content`),
EDGE TYPE `FollowKOL` (`Person`)-[LABEL `FollowKOL`{`follow_time` ZONED DATETIME NOT NULL, `interaction_level` DOUBLE DEFAULT NULL, MULTIEDGE KEY(`follow_time`)}]->(`Person`),
EDGE TYPE `HasInterest` (`Person`)-[LABEL `HasInterest`{`weight` DOUBLE DEFAULT NULL}]->(`UserTag`),
EDGE TYPE `Cites` (`Content`)-[LABEL `Cites`{`cite_time` ZONED DATETIME DEFAULT NULL}]->(`Content`)
}
CREATE GRAPH `social_recommendation` :: `social_recommendation`
1. 节点类型
| 节点类型 | 标签 | 核心属性 |
|---|---|---|
| 用户(自然人) | Person |
person_id (唯一标识), name (昵称/姓名), city (所在城市), register_time (注册时间) |
| 社区/圈子 | Community |
community_id (唯一标识), name (社区名称), topic (主题分类), created_time (创建时间) |
| 内容/帖子 | Content |
content_id (唯一标识), title (标题), category (内容分类), publish_time (发布时间) |
| 用户兴趣标签 | UserTag |
tag_name (标签名,如“AI”、“旅行”) |
2. 边类型
| 边类型 | 起始节点 → 目标节点 | 说明 |
|---|---|---|
Friend |
Person → Person |
好友关系(双向社交) |
FollowKOL |
Person → Person |
关注 KOL/大V(单向社交) |
MemberOf |
Person → Community |
加入社区/群组 |
Forward |
Person → Content |
转发/分享内容 |
Like |
Person → Content |
点赞/喜欢内容 |
Comment |
Person → Content |
评论内容 |
HasInterest |
Person → UserTag |
用户兴趣标签 |
Cites |
Content → Content |
内容引用/关联 |
数据导入
💡本 Demo 仅预置 30 名用户及数千条社交关系,实际导入时,数据量可达亿级。
-- 导入用户节点
TABLE `person_data` { `person_id`, `name`, `city`, `register_time` } =
("p001", "Alice", "Beijing", "2024-01-05T09:00:00 +0800"),
("p002", "Bob", "Beijing", "2024-01-06T10:30:00 +0800"),
...
("p030", "Derek", "Hangzhou", "2024-02-03T13:00:00 +0800");
USE `social_recommendation`
FOR re IN `person_data`
INSERT (@`Person` {`person_id`: re.`person_id`, `name`: re.`name`, `city`: re.`city`, `register_time`: CAST(re.`register_time` AS ZONED DATETIME)});
-- 导入社群节点
TABLE `community_data` { `community_id`, `name`, `topic`, `created_time` } =
("c001", "AI与大模型研究", "Technology", "2023-12-01T08:00:00 +0800"),
("c002", "电商运营交流", "Business", "2023-12-05T09:00:00 +0800"),
("c003", "硬核数码科技", "Hardware", "2023-12-10T10:00:00 +0800"),
("c004", "城市慢生活", "Lifestyle", "2023-12-15T11:00:00 +0800");
USE `social_recommendation`
FOR re IN `community_data`
INSERT (@`Community` {`community_id`: re.`community_id`, `name`: re.`name`, `topic`: re.`topic`, `created_time`: CAST(re.`created_time` AS ZONED DATETIME)});
-- 导入内容节点
TABLE `content_data` { `content_id`, `title`, `category`, `publish_time` } =
("ct001", "图数据库在AI时代的机遇", "Tech", "2024-03-01T08:00:00 +0800"),
("ct002", "2024电商新风向标", "Business", "2024-03-02T09:00:00 +0800"),
("ct003", "深度解析PageRank算法", "Tech", "2024-03-03T10:00:00 +0800"),
...
("ct010", "如何高效管理时间", "Life", "2024-03-10T17:00:00 +0800");
USE `social_recommendation`
FOR re IN `content_data`
INSERT (@`Content` {`content_id`: re.`content_id`, `title`: re.`title`, `category`: re.`category`, `publish_time`: CAST(re.`publish_time` AS ZONED DATETIME)});
-- 导入兴趣标签节点
TABLE `tag_data` { `tag_name` } =
("人工智能"),
("电商运营"),
("数码测评"),
("生活美学"),
("后端开发");
USE `social_recommendation`
FOR re IN `tag_data`
INSERT (@`UserTag` {`tag_name`: re.`tag_name`});

关键查询示例
1. 查找某人的 1-3 度好友
目的:全面掌握目标用户的社交网络范围,发现潜在的兴趣传播路径和社群影响力范围。
USE `social_recommendation`
MATCH p=(src@`Person` {`person_id`: "p001"})-[:`Friend`]-{1,3}(friend)
RETURN p
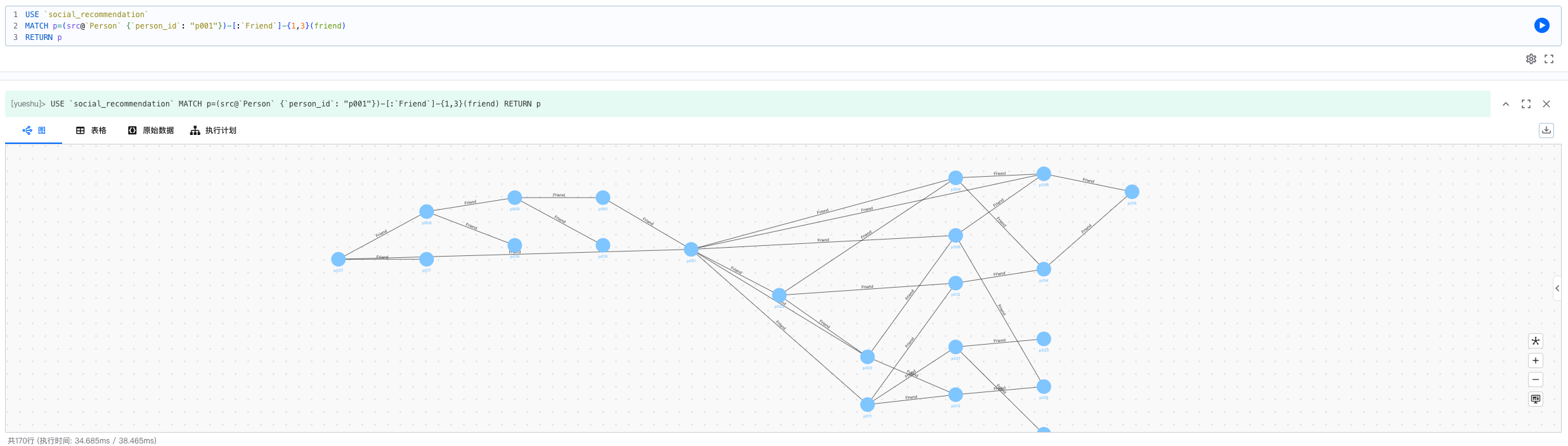
基于图的解释:该图展示了从用户 p001 出发,经过 1 到 3 跳好友关系能到达的所有用户节点及路径。
2. 熟人好友推荐
目的:基于“朋友的朋友是朋友”的社交理论,通过共同好友数量为用户推荐可能认识的人。
USE `social_recommendation`
MATCH (src@`Person` {`person_id`: "p001"})-[:`Friend`]-(mutual_friend)-[:`Friend`]-(candidate)
WHERE candidate.`person_id` <> "p001" // 排除自己
AND NOT EXISTS((src)-[:`Friend`]-(candidate)) // 排除已经是好友的人
RETURN candidate.`person_id` AS recommended_friend,
candidate.`name` AS name,
count(mutual_friend) AS mutual_friends_count
ORDER BY mutual_friends_count DESC
LIMIT 10
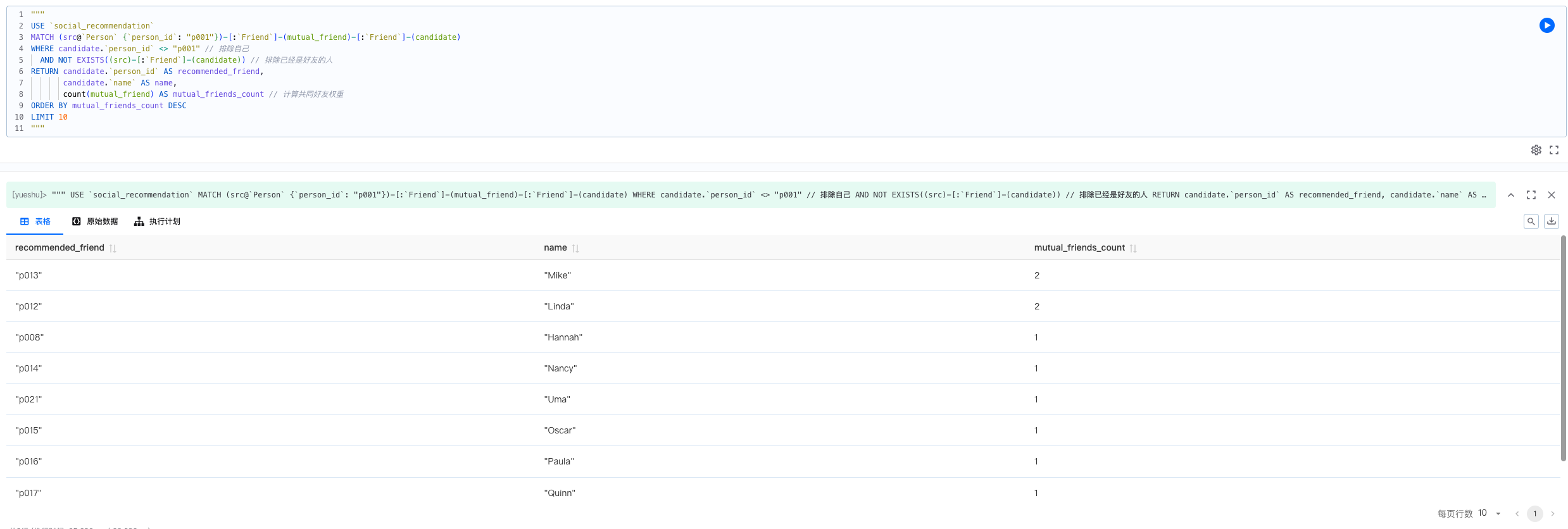
基于表格的解释:为用户 p001 推荐共同好友最多的前 10 位潜在朋友。mutual_friends_count 越高,推荐的理由越充分,用户接受推荐的概率越大。
3. 兴趣社群推荐 (基于朋友圈子)
目的:通过分析用户好友的社群加入行为,推测用户可能也感兴趣的社群,实现社群推荐。
USE `social_recommendation`
MATCH (src@`Person` {`person_id`: "p001"})-[:`Friend`]-(friend)-[:`MemberOf`]-(community)
WHERE NOT EXISTS((src)-[:`MemberOf`]-(community))
RETURN community.`name` AS community_name,
community.`topic` AS topic,
count(friend) AS friends_joined_count
ORDER BY friends_joined_count DESC
LIMIT 5
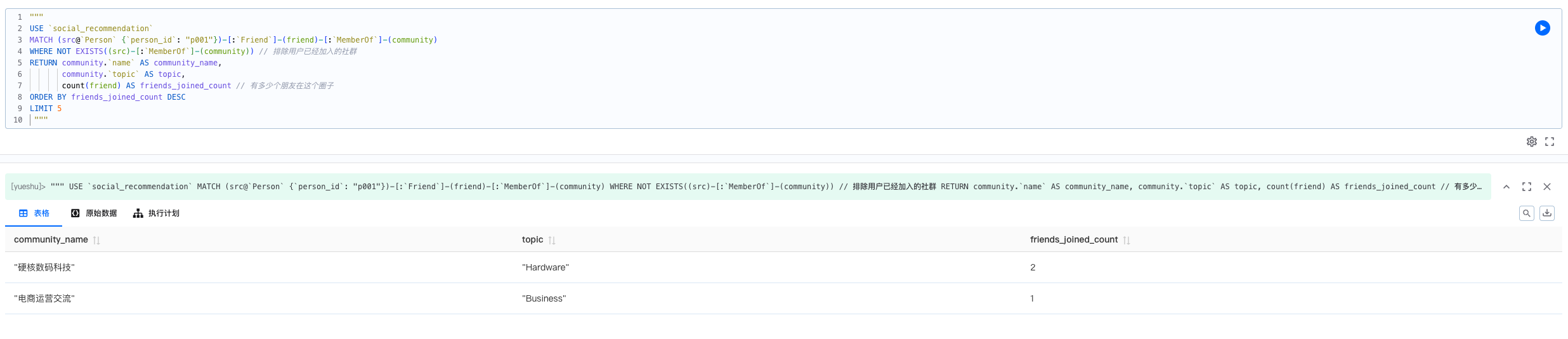
基于表格的解释:为用户 p001 推荐其好友们最常加入的 5 个社群。friends_joined_count越高,说明该社群在当前用户的社交圈子中越流行,推荐价值越高。
4. 基于相似行为的内容推荐
目的:找到与目标用户有相同转发行为的相似用户,然后将这些相似用户点赞过的其他内容推荐给目标用户,实现协同过滤推荐。
USE `social_recommendation`
MATCH (src@`Person` {`person_id`: "p002"})-[:`Forward`]->(common_content)<-[:`Forward`]-(similar_user)-[:`Like`]->(recommended_content)
WHERE NOT EXISTS((src)-[:`Like`]->(recommended_content))
AND NOT EXISTS((src)-[:`Forward`]->(recommended_content))
RETURN recommended_content.`title` AS content_title,
similar_user.`name` AS liked_by_user,
count(common_content) AS similarity_score
ORDER BY similarity_score DESC
LIMIT 10
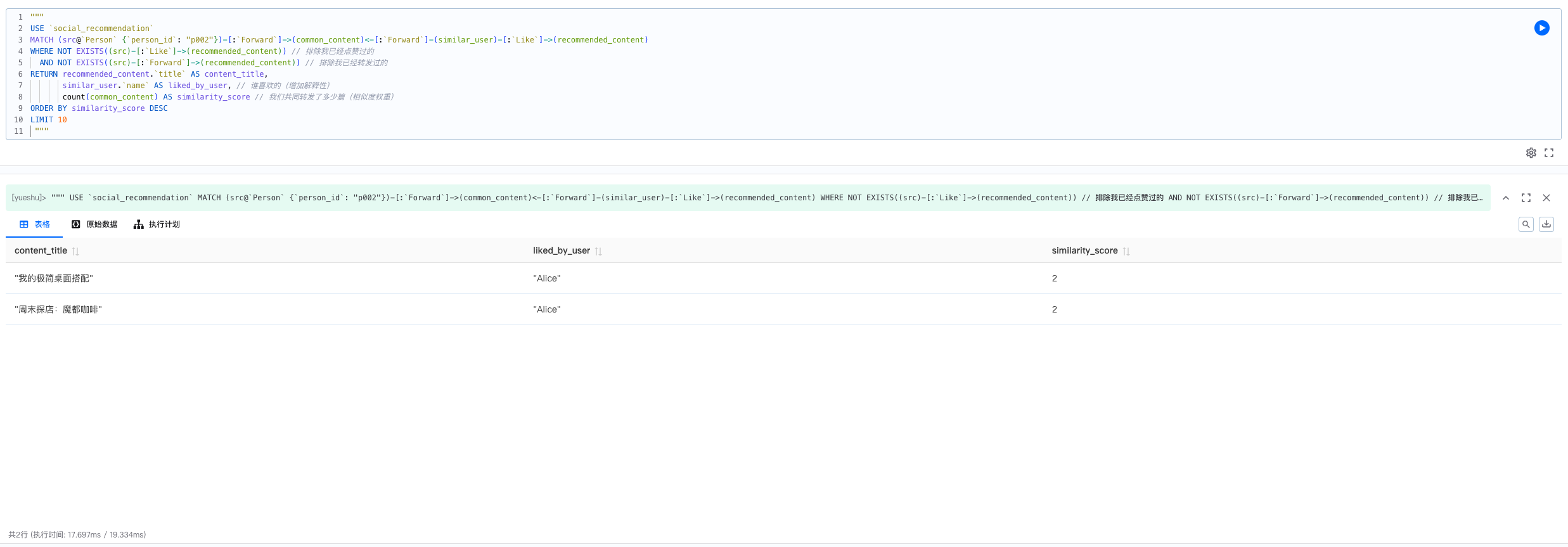
基于表格的解释:为用户 p002 推荐由与其转发行为最相似的 10 位用户所喜欢的内容。similarity_score 代表推荐内容与用户兴趣的相似度权重,liked_by_user 字段提供了推荐理由(“您关注/相似的 XX 用户也喜欢”)。
总结
通过 NebulaGraph 构建的社交兴趣关联网络,推荐系统可以:
- 发现多层社交路径:利用好友、关注等关系,挖掘用户间的潜在联系和影响力传导路径。
- 量化推荐权重:基于共同好友数、相似行为等指标,为推荐提供可量化的信任度和相似度依据。
- 实现多样化推荐逻辑:轻松实现熟人推荐、社群推荐、协同过滤、KOL内容扩散”等多种核心推荐策略。
- 增强推荐可解释性:通过图路径回溯,清晰展示推荐结果的产生依据(如“因为你的朋友XX加入了”),提升用户信任感。
本 Demo 展示了基础查询,仅作为简单场景下的 NebulaGraph 使用参考。在实际生产环境中,还可结合 PageRank、标签传播、连通分量等图算法,实现更智能的社区发现与兴趣扩散。
交流图数据库技术?加入 Nebula 交流群请先填写下「你的 Nebula 名片」,Nebula 小助手会拉你进群~~




