
技术分享
NebulaGraph 软件工程师|全球顶级数据库大会 SIGMOD 参会感想

今年 SIGMOD'22 在费城 Philadelphia 举办,我有幸代表公司作为资助商参加。此次参会,我和学生、教授、厂商多有交流,一方面宣传了我们的产品,另一方面也获取了许多宝贵的建议和意见。接下来,我将分享其中一些建议,以及我整体的思考。
图学习和存储技术广受关注
首先是行业新趋势,本次会议大家关注的热点主要有两个。第一,机器学习的比重进一步增加,尤其 图学习(graph learning) 可能成为新的热点。近年来,越来越多的系统领域的会议会专门开设机器学习的专区,主要是运用一些机器学习的方法来优化系统或者算法。其中,有一个方向最近异军突起,就是图学习。简单来说,图学习就是在图上的机器学习。和其他用机器学习解决实际问题类似,图学习通过 embedding 的方式,从 graph 中提取出特征向量(feature vector),然后用机器学习的方法解决图中那些困难的问题,包括分类、子图匹配、链接预测(classfication,subgraph matching,link prediction)等。
从会议的倾向和 NSF (National Science Foundation) 的指导来看,这个趋势还会持续火热。我们也收到很多学生和教授关于是否支持图学习的询问。从图数据库供应商角度出发,图学习是 NebulaGraph 的应用之一。我们不能仅仅满足于提供图数据库核心,还得为上层应用提供库、接口,甚至优化,来保证上层应用的顺利高效运行。从另一个角度出发,如果我们的 NebulaGraph 可以帮助学界在一些领域,比如在图学习方面有一些突破,对我们公司,对全行业发展也是大有裨益的。

除了机器学习,我认为另一个热点趋势就是内存,包括 in-memory database, Persistent memory 等。目前非易失性存储(non volatile memory),或者叫持久性存储(persistent memory),经过学术界和工业界十多年的共同努力已经越来越成熟。目前针对如何使用持久性存储的研究也是非常火热,几乎所有系统的顶会都有大量相关的文章。
具体到数据库领域,就包括如何设计内存数据库(in-memory database)、如何将持久性存储(persistent memory) 和 SSD、DRAM 等混合使用,如何解决内存隔离(memory segregation)的问题。NebulaGraph 作为图数据库供应商,也应该积极拥抱新硬件带来的改变,积极探索基于 persistent memory 的存储系统。
图的优势与发展方向
除了新趋势,我在会议中最大的收获和思考是关于图数据库(GDBMS)和关系型数据库(RDMBS)的比较。会上有不少人表达为什么不基于 关系型数据库来实现 graph datababse 的疑虑。因为关系型数据库经过多年优化,确实已经武装到了牙齿。比如 Peter Boncz 教授(LDBC创始人之一)在今年早些时候在 EDBT / ICDT 会议上做了个主题演讲——《The (Sorry) State of Graph Database Systems 》[1],提出当前 GDBMS 跟 RDMBS 相比,在计算和存储层都还有很多地方需要提高,尤其是针对子图匹配(subgraph matching) 这样的 AP 查询。他提出了针对子图匹配场景的性能基准测试(Benchmark)。在他的实验环境下,没有一款图数据库软件在「子图匹配」场景上的性能能够接近 Hyper 和 Umbra 这两款关系型数据库(见下面图1).
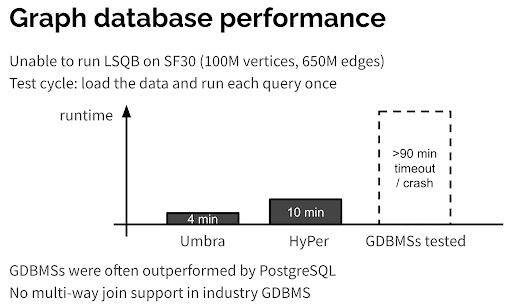
这个实验的设置固然有值得探讨的地方,但 Peter 作为 LDBC 的创始人,他的核心目的自然不是贬低图数据库,只是想借用子图匹配——这个图数据库优化得还不够好的一种查询场景,来鼓励各个图数据库厂商提升自己的产品。
从更广的图景来看,我们 NebulaGraph 作为图数据库厂商,必须把握图数据库和关系型数据库的区别和优势:一是图查询,尤其是 GQL 相对于 SQL 的易用性和高效性。二是易用性,Neo4J 的 CEO,Emil Eifrem 有个非常好的例子[3]:对于一个 AP 系统非常常见的查询,如果使用 SQL 需要 23 个 SELECT,21 个 WHERE,11 个 JOIN,9 个 UNION,最后形成一个巨长无比的查询语句(query)。但如果使用图相关语句,只需要一个 MATCH 和一个 WHERE。对于使用 SQL,很有可能是无法完成工作或者极易出错,而对于后者使用图相关语句,则可以省下无数人力物力。
关于性能,除了在关联关系查询中,图数据库相较于关系型数据库的天然优势,还需要在其他图相关的各种查询上(不止于上文提到的子图匹配 subraph matching)取得对于关系型数据库的优势。这其实也是 Peter 提出子图查询这个检测基准对于我们的核心启示。
对底层存储结构的思考

最后我们也获得了不少关于底层存储的建议。NebulaGraph 目前底层存储使用的是基于 LSM Tree 的 RocksDB。但 LSM Tree 是否适用于图数据库的 workload,尤其是上云后,是否是性能最好、成本最低的选择,一直是有争议的。可能的替代者有:
Bε-tree File System,betrFS: https://www.betrfs.org/
LiveGraph:https://marcoserafini.github.io/papers/LiveGraph.pdf
B+ Tree: 在这方面,后续我们也会持续跟进研究
总之,这次 SIGMOD’22 之旅收获了许多。期待明年的 SIGMOD。西雅图见!
[1]https://conferences.inf.ed.ac.uk/edbticdt2022/?contents=invited_talks.html
[2]https://docs.google.com/presentation/d/1xUbooiL8rIMzkp9G9EXmN4tIMMWt2mC53Q0u4mslq5g/edit#slide=id.ge0f13c0edc_0_47
[3] https://people.eecs.berkeley.edu/~istoica/classes/cs294/15/notes/21-neo4j.pdf
交流图数据库技术?加入 Nebula 交流群请先填写下你的 Nebula 名片,Nebula 小助手会拉你进群~~




