
技术分享
分布式系统中的麻烦事(下):真相由多数派定义?
以下文章来源于木鸟杂记 ,作者穆尼奥
 到此为止,通过上篇和中篇已经梳理了分布式系统和单机系统的诸多差异:
到此为止,通过上篇和中篇已经梳理了分布式系统和单机系统的诸多差异:
进程间不能共享内存,只能通过消息传递来交互
唯一的通信渠道(网络)还是不可靠的,且有极不确定(unbounded,无界)延迟
需要处理不可靠时钟造成的多机时钟漂移问题
任意的不确定的进程停顿
如果你没有习惯于应对分布式系统环境,可能会对由上述问题引起的异常感到十分困惑。分布式系统中编程复杂度高的本质在于:身处网络中的节点,不能直接确信任何事情,而只能根据从网络中得到的信息(没有得到回复也是一种信息)来推测(guess),只能通过与其他节点交换信息来确定其状态。如果一个对端节点没有响应,我们难以分辨是网络问题还是节点本身问题。
对这些系统边界的进一步讨论就有点偏哲学了:
在我们的系统中,哪些信息是真?哪些信息是假?
在感知和测量手段本身都不准的情况下,我们对由上述手段得来的信息的真假又可以有几分确信?
软件系统是否需要遵循物理世界的法则,如因果关系?
幸运的是,我们并不需要进一步追问到人生的意义是什么(笑)。在分布式系统中,我们可以做一些基本假设,并基于这些假设设计真实系统。基于特定假设,我们能够设计出能够被证明正确性的算法。那么,纵然底层系统不怎么可靠,我们仍能通过罩一层协议,使其对上提供相对可靠的保证(比如 TCP)。
虽然可以在不稳定的系统模型上构建运行良好的系统,但这种构建过程本身却并非直观易懂。在本文,我们将继续探讨分布式系统中的知识和事实,来辅助我们思考对下做什么样的假设、对上提供什么样的保证。而后续,我们会进一步考察一些分布式系统中的例子和算法,看看他们是如何来通过特定的假设来提供特定服务的。
真相由多数派定义
设想一个具有非对称故障(asymmetric fault)的网络:某个节点可以收到任何其他节点发送给他的信息,但其发出的消息却被丢弃或者延迟很高。此时,尽管该节点运行良好,并且能处理请求,但却无人能收到其响应。在经过某个超时阈值后,其他节点由于收不到其消息,会将其标记为死亡。
打个比方,这种情况就像一个噩梦:处于半连接的节点就像躺在棺材里被运向墓地,尽管他持续大喊:“我没有死”,但没有人能听到他的喊声,葬礼继续。
第二个场景,稍微不那么噩梦一些,这个处于半连接的节点意识到了他发出去的消息别人收不到,进而推测出应该是网络出了问题。但纵然如此,该节点仍然被标记为死亡,而它也没有办法做任何事情来改变,但起码他自己能意识到这点。
第三个场景,假设一个节点经历了长时间的 GC,该节点上的所有线程都被中断长达一分钟,此时任何发到该节点的请求都无法被处理,自然也就无法收到答复。其他节点经过等待、重试、失掉耐心进而最终标记该节点死亡,然后将其送进棺材板。经过漫长的一分钟后,终于,GC 完成,所有线程被唤醒从中断处继续执行。从该线程的角度来看,好像没有发生过任何事情。但是其他节点惊讶地发现棺材板压不住了,该节点做起来了,恢复了健康,并且又开始跟旁边的人很开心的聊天了。
上述几个故事都表明,任何节点都没法独自断言其自身当前状态。一个分布式系统不能有单点依赖,因为单个节点可能在任意时刻故障,进而导致整个系统卡住,甚而不能恢复。因此,大部分分布式算法会基于一个法定人数(quorum),即让所有节点进行投票:任何决策都需要达到法定人数才能生效,以避免对单节点的依赖。
其中,前面故事中的宣布某个节点死亡就是这样一种决策。如果有达到法定个数的节点宣布某节点死亡,那他就会被标记为死亡。即使他还活着,也不得不服从系统决策而出局。
最普遍的情况是,法定人数是集群中超过半数的节点,即多数派(其他比例的法定人数也有可能)。多数派系统允许少数节点宕机后,集群仍能继续工作(如三节点集群,可以容忍一个节点的故障;五节点集群,可以容忍两个节点故障)。并且在少数节点故障后,集群仍能安全地做出决策。因为在一个集群中,根据鸽巢原理,系统中不可能有两个多数派做出不同的决策。后续 DDIA 第九章,讨论共识协议时,我们会展开更多细节。
领导者和锁
在很多场景下,系统会要求某些东西全局唯一,比如:
每个数据库分片都有唯一的领导者,避免脑裂
只有一个事务或者客户端允许持有某资源或者对象的锁,以避免并发写入或者删除
每个名字最多允许一个用户注册,因为需要用用户名来唯一标识一个用户
在分布式系统中实现这种唯一性需要格外小心:尽管某个节点自认为它是那个“唯一被选中的(The chosen one)”(分区的主副本、锁的持有者、成功处理用户名注册请求的节点),这并不意味着法定数目的(Quorum)节点也都如此认为!可能一个节点以前是领导者,但在其领导期间,如果其他节点都认为它死了(可能由于网络故障或者 GC 停顿),它就有可能被降级,且其他节点被选举上位。
当大多数节点认为前领导者死亡时,该节点仍然自顾自的行使领导权,在设计的不太好的系统中,就会带来一些问题。这样的前领导节点可能会给其他节点发送一些错误决策的消息,如果其他节点相信且接受了这些消息,系统在整体层面可能就会做出一些错误的事情。
下图展示了一个由错误实现的锁导致的数据损坏(data corruption)的 Bug(这个 Bug 并存在于纯理论上,HBase 曾经就有这个 Bug)。假设你想保证在任意时刻,存储服务上的文件最多只能被一个客户端访问,以避免多个客户端并发修改时损坏数据。具体到实现上,你想让客户端在访问文件时,先从锁服务获取一个租约:
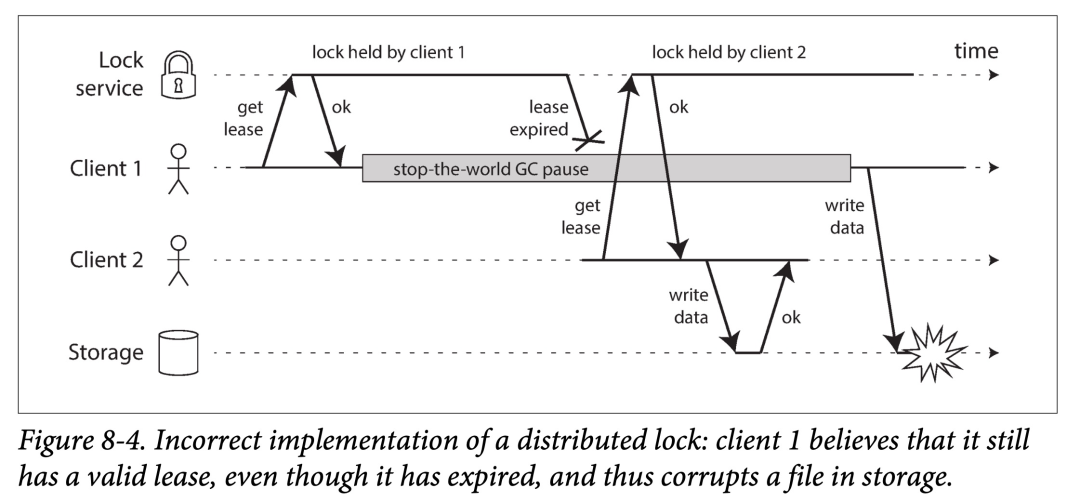
前面小节“进程停顿”中其实讲到了这么做会导致的问题:如果持有租约的客户端停顿了过长时间,以至于租约过期。此时,另外一个客户端向锁服务请求并获取到同一个文件的租约,然后开始写文件。当前一个停顿的客户端恢复时,它想当然的认为自己仍然持有租约,也开始写文件。此时,这两个客户端的写入可能会产生冲突并导致文件的数据损坏。
防护令牌
当我们使用锁或租期来保护对某些资源的(如上图中的文件)互斥访问时,我们需要确保那些错误的认为自己是“被选中的人”(比如主副本、持有锁等)不能影响系统其他部分。此问题一个简单的解决方法是,使用防护(fencing),如下图所示:
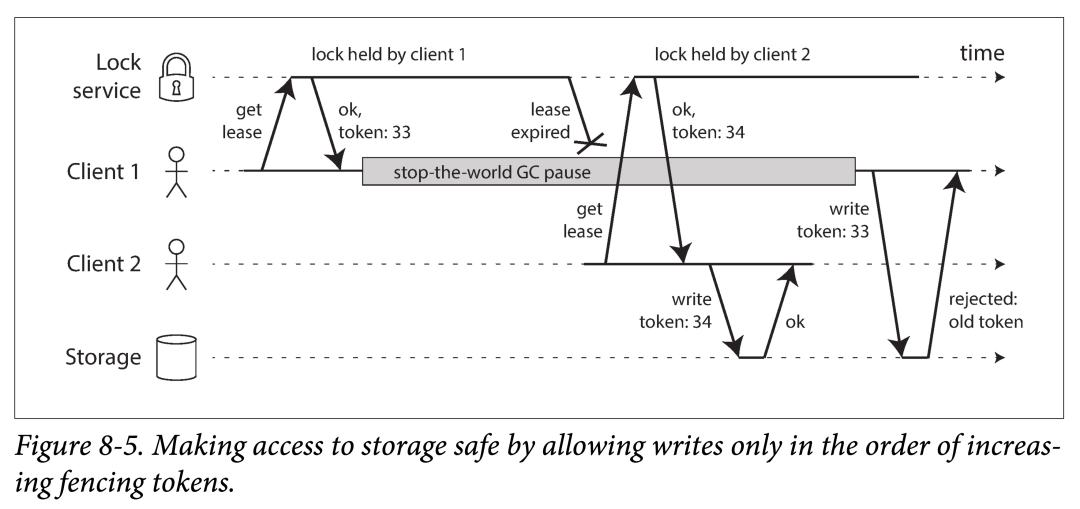
即,在锁服务每次授予锁或者租约时,会附带给一个防护令牌(fencing token)。该防护令牌其实就是一个单调递增数字,锁服务在每次锁被授予时,对其进行加一。当存储服务每次收到客户端的请求时,都会要求出示该令牌。
如上图,客户端 1 获得了一个关联了令牌号 33 的租期,但随即经历了长时间的停顿,然后租约过期。客户端 2 获得了一个关联令牌号 34 的租期,并且向存储服务发送了一个附带了该令牌号的写请求。稍后,当客户端 1 结束停顿时,附带令牌号 33,给存储服务发送写请求。然而,由于存储服务记下了它处理过更高令牌号(34)的请求,于是它就会拒绝该使用令牌号 33 的请求。
如果我们使用 ZooKeeper 作为锁服务,那么事务 ID zxid 或者节点版本 cversion 可以用于防护令牌。因为他们单调递增,符合需求。
注意到,该机制要求资源服务自己可以主动拒绝使用过期版本令牌的写请求,也就是说,仅依赖客户端对锁状态进行自检是不够的。对于那些不能显式支持防护令牌检查的资源服务来说,我们仍然可以有一些变通手段(work around,如在写入时将令牌号写到文件路径中),总之,引入一些检查手段是必要的,以避免在锁的保护外执行请求。
这也是某种程度上的真相由多数决定:客户端不能独自确定其对资源的独占性。需要在服务端对所有客户端的情况做一个二次核验。
在服务端检查令牌粗看下是个缺点,但其无疑是个可以言明的优点:默认所有客户端都是遵纪守法的并不明智,因为运行客户端的人和运行服务的人具有完全不同的优先考虑点。因此,我们最好在服务端做好防护,使其免受不良客户端的滥用甚至攻击。
拜占庭错误
防护令牌只能检测并阻止无意(inadvertently,如不知道自己租约过期了)中犯错的客户端。但如果某个客户端节点存心想打破系统约定,可以通过伪造防护令牌来轻易做到。
在本书中我们假设所有参与系统的节点有可能不可靠(unreliable)、但一定是诚实的(honest):这些节点有可能反应较慢甚至没有响应(由于故障),他们的状态可能会过期(由于 GC 停顿或者网络延迟),但一旦节点响应,“说的都是真话”:在其认知范围内,尽可能的遵守协议进行响应。
如果系统中的节点有“说谎”(发送任意错误的的或者损坏的信息)的可能性,分布式系统将会变得十分复杂。如,一个节点没有收到某条消息却声称收到了。这种行为称为拜占庭故障(Byzantine fault),在具有拜占庭故障的环境中达成共识也被称为拜占庭将军问题(Byzatine Generals Problem)。
拜占庭将军问题
拜占庭将军问题是两将军问题(Two Generals Problem)的泛化。两将军问题设想了一个需要达成作战计划的战争场景。有两支军队,驻扎在两个不同的地方,只能通过信使来交换信息,但信使有时候会迟到甚至迷路(如网络中的数据包)。第九章会详细讨论这个问题。
在该问题的拜占庭版本,有 n 个将军,但由于中间出了一些叛徒,他们想达成共识更具难度。但大部分将军仍然是忠诚的,并且会送出真实的消息;与此同时,叛徒会试图通过送出假的或者失实的消息来欺骗和混淆其他人(同时保持隐蔽)。大家事先都不知道谁是叛徒。
拜占庭是一个古希腊城市,后来罗马皇帝君士坦丁在此建立新都,称为“新罗马”,但后人普遍被以建立者之名称作君士坦丁堡,现在是土耳其的伊斯坦布尔。当然,没有任何历史证据表明拜占庭的将军比其他地方更多地使用阴谋诡计。相反,这个名字是来自于拜占庭本身,在计算机出现很久之前,拜占庭就有极度复杂、官僚主义、狡猾多变等含义。Lamport 想选一个不会冒犯任何读者的城市,比如,有人提醒他阿尔巴尼亚将军问题就不是一个好名字。
如果有一些节点发生故障且不遵守协议,或者恶意攻击者正在扰乱网络,一个系统仍能正确运行,则该系统是拜占庭容错的(Byzantine fault-tolerant)。举几个相关的场景例子:
在航天环境中,由于高辐射环境的存在,计算机内存或者寄存器中的数据可能会损坏,进而以任意不可预料的方式响应其他节点的请求。在这种场景下,系统故障代价会非常高昂(如:太空飞船坠毁并致使所有承载人员死亡,或者火箭装上国际空间站),因此飞控系统必须容忍拜占庭故障。
在一个有多方组织参与的系统中,有些参与方可能会尝试作弊或者欺骗别人。在这种环境中,由于恶意消息发送方的存在,无脑的相信其他节点的消息是不安全的。如,类似比特币或者其他区块链的 p2p 网络,就是一种让没有互信基础的多方,在不依赖中央权威的情况下,就某个交易达成共识的一种方法。
当然,对于本书中讨论的大部分系统,我们都可以假设不存在拜占庭故障。因为,在你的数据中心里,所有的节点都是受你所在的组织控制的(因此大概率是可信的,除非受攻击变成了肉机),并且辐射水平足够低,因此内存受辐射损坏的概率也微乎其微。此外,让系统能够进行拜占庭容错的协议复杂度都非常高,且嵌入式系统的容错依赖于硬件层面的支持。因此,在绝大多数服务端的数据系统中,使用拜占庭容错的解决方案都是不现实的。
Web 应用确实可能遇到由任意终端用户控制的客户端(如浏览器)发送来的任意的,甚至是恶意的请求。这也是为啥输入校验、过滤和输出转义如此重要——如可以防止 SQL 注入和跨域攻击(SQL injection and crosssite scripting)。然而,我们在此时通常不会使用拜占庭容错的协议,而是简单地让服务端来决定用户输入是否合法。在没有中心权威的 p2p 网络中,才更加需要拜占庭容错。
当然,从某种角度来说,服务实例中的 bug 也可以被认为是拜占庭故障。但如果你将具有该 bug 的软件部署到了所有节点中,拜占庭容错的算法也无能为力。因为大多数拜占庭容错的算法要求超过三分之二的绝大多数的节点都是正常运行的(如系统中有四个节点,则最多允许有一个恶意节点)。如果想使用拜占庭容错算法来避免故障,你需要四个节点部署有四种独立实现,但提供同样功能的软件,并且 bug 最多只存在于其中的一种实现中。
类似的,如果某种拜占庭容错的协议能够让我们免于漏洞、安全渗透和恶意攻击,那他会相当具有吸引力。但不幸,这也是不现实的,在大多数系统中,由于系统不同节点所运行软件的同构性,如果攻击者能够拿下一个节点,那他大概率能拿下所有节点。因此,一些传统的中心防护机制(认证鉴权、访问控制、加密、防火墙等等)仍是让我们免于攻击的主要手段。
弱谎言
即使我们通常假设节点是诚实的,但为软件加上一些对弱谎言(week forms of lying)的简单防护机制仍然很有用,例如由于硬件故障、软件 bug、错误配置等问题,一些节点可能会发送非法消息。由于不能挡住有预谋对手的蓄意攻击,这种防护机制不是完全的的拜占庭容错的,但却是一种简单有效的获取更好可用性的方法。例如:
由于操作系统、硬件驱动、路由器中的 bug,网络中的数据包有时会损坏。通常来说,TCP 或者 UDP 协议中内置的校验和机制会检测到这些损坏的数据包,但有时他们也会逃脱检测。使用一些很简单的手段就能挡住这些损坏的数据包,如应用层的校验字段。
可公开访问的应用需要仔细地过滤任何来自用户的输入,如检查输入值是否在合理的范围内、限制字符串长度,以避免过量内存分配造成的拒绝服务攻击。防火墙内部的服务可以适当放宽检查,但(如在协议解析时)一些基本的合法性检查仍是十分推荐的。
可以为 NTP 客户端配置多个 NTP 服务源。当进行时钟同步时,客户端会向所有源发送请求,估算误差,以判断是否绝大多数源提供的时间会落在同一个时间窗口内。只要大部分 NTP 服务器正常运行,一两个提供错误时间的 NTP 服务器就会被检测出来,并被排除在外。从而,使用多个服务器让 NTP 同步比使用单个服务器更加鲁棒。
系统模型和现实
前人已经设计了很多算法以解决分布式系统的的问题,如我们将要在第九章讨论的共识问题的一些解决方案。这些算法需要能够处理本章提到的各种问题,才能够在实际环境用有用。
在设计算法的时候,不能过重的依赖硬件的细节和软件的配置,这迫使我们对系统中可能遇到的问题进行抽象化处理。我们的解决办法是定义一个系统模型(system model),以对算法的期望会遇到的问题进行抽象。
对于时间的假设,有三种系统模型很常用:
同步模型(synchronous model)。这种模型假设网络延迟、进程停顿和时钟错误都是有界的。但这不是说,时钟是完全同步的、网络完全没有延迟,只是说我们知道上述问题永远不会超过一个上界。但当然,这不是一个现实中的模型,因为在实践中,无界延迟和停顿都会实实在在的发生。
半同步模型(partial synchronous)。意思是在大多数情况下,网络延迟、进程停顿和时钟漂移都是有界的,只有偶尔,他们会超过界限。这是一种比较真实的模型,即在大部分时间里,系统中的网络和进程都表现良好,否则我们不可能完成任何事情。但与此同时,我们必须要记着,任何关于时限的假设都有可能被打破。且一旦出现出现异常现象,我们需要做好最坏的打算:网络延迟、进程停顿和时钟错误都有可能错得非常离谱。
异步模型(Asynchronous model)。在这种模型里,算法不能对时间有任何假设,甚至时钟本身都有可能不存在(在这种情况下,超时间隔根本没有意义)。有些算法可能会针对这种场景进行设计,但很少很少。
除时间问题,我们还需要对节点故障进行抽象。针对节点,有三种最常用的系统模型:
宕机停止故障(Crash-stop faults)。节点只会通过崩溃的方式宕机,即某个时刻可能会突然宕机无响应,并且之后永远不会再上线。
宕机恢复故障(Crash-recovery faults)。节点可能会在任意时刻宕机,但在宕机之后某个时刻会重新上线,但恢复所需时间我们是不知道的。在此模型中,我们假设节点的稳定存储中的数据在宕机前后不会丢失,但内存中的数据会丢失。
拜占庭(任意)故障(Byzantine (arbitrary) faults)。我们不能对节点有任何假设,包括宕机和恢复时间,包括善意和恶意,前面小节已经详细讨论过了这种情形。
对于真实世界,半同步模型和宕机恢复故障是较为普遍的建模,那我们又要如何设计算法来应对这两种模型呢?
算法的正确性
我们可以通过描述算法需要满足的性质,来定义其正确性。举个例子,排序算法的输出满足特性:任取结果列表中的两个元素,左边的都比右边的小。这是一种简单的对列表有序的形式化定义。
类似的,我们可以给出描述分布式算法的正确性的一些性质。如,我们想通过产生防护令牌的方式来上锁,则我们期望该算法具有以下性质:
唯一性(uniqueness)。两个不同请求不可能获得具有相同值的防护令牌。
单调有序性(monotonic sequence)。设请求 x 获取到令牌 tx,请求 y 获取到令牌 ty,且 x 在 y 之前完成,则由 tx < ty。
可用性(availability)。如果某永不宕机节点请求一个防护令牌,则其最终会收到响应。
在某种系统模型下,如果一个算法能够应对该模型下的所有可能出现的情况,并且时刻满足其约束性质,则我们称该算法是正确的。但当然,如果所有节点都宕机了、或网络延迟变得无限长,那么没有任何算法可以正常运作。
安全性和存活性
为了进一步弄清状况,我们需要进一步区分两类不同的属性:安全性(safety)和存活性(liveness)。在上面的例子中,唯一性和单调有序性属于安全性,但可用性属于存活性。
那如何区分这两者呢?一个简单的方法是,在描述存活性的属性的定义里总会包含单词:“最终(eventually)”,对,我知道你想说什么,最终一致性(eventually)也是一个存活性属性。
安全性,通俗的可以理解为没有坏事发生(nothing bad happens);而存活性可以理解为好的事情最终发生了(something good eventually happens),但也不要对这些非正式定义太过咬文嚼字,因为所谓的“好”和“坏”都是相对的。安全性和存活性的严格定义都是精确且数学化的:
如果违反了安全性,我们一定可以找到一个其被破坏的具体时间点。(如,对于防护令牌算法,如果违反了唯一性,则一定有个某个请求,返回了重复的令牌)一旦违反了安全性,造成的破坏不能被恢复,即破坏是永久的。
存活性正好相反,可能在某个时刻不满足(如某节点发出请求,但还没有被收到),但是在将来时刻总会被满足(即最终会收到消息)。
区分安全性和存活性的意义在于,我们可以处理一些复杂的系统模型。对于分布式系统算法,我们通常会比较关注安全性,在系统模型可能触到的各种情况下,安全性都必须满足。即,即使最不利的情况,所有节点都宕机、整个网络都瘫痪,算法也必须要保证安全,不能返回错误结果。
相反,对于存活性来说,我们放宽一些:如我们会说一个请求只有在大多数节点存活、网络最终通畅的情况下才会最终收到请求。半同步模型的定义其实蕴含着,它最终会回到同步状态,即,网络中断只会持续有限时间,终将被修复。
将系统模型映射到真实世界
在衡量分布式系统算法时,安全性、存活性和系统模型都是很有用的工具。但我们在真实世界里去实现一个实际的系统时,无数烦人的细节又都会浮现出来,时刻提醒你,系统模型终究只是对现实一种理想的简化。
如,宕机恢复模型一般会假设数据存在稳定存储上,在多次宕机重启后不会丢失。但在实践中,如果磁盘数据损坏怎么办?如果固件有 bug 导致重启时无法识别磁盘驱动怎么办?
Quorum 算法多要求每个节点记住其所声明的内容。如果由于某个节点有“健忘症”,忘记了之前存的数据,就会打破 Quorum 算法的假设,从而破坏该算法的正确性。在这种情况下,我们可能需要一种新的系统模型,能允许节点在宕机重启时偶尔忘点东西,但我们难以推演基于这种模型算法的正确性。
我们在对算法进行理论描述的时候,可以假设一些事情不会发生。比如,在非拜占庭系统中,我们假设对哪些故障会发生、哪些不会做了假设。但在系统实现的代码中,我们通常也会保留处理这些极端情况的代码,哪怕处理的很简单,比如打印一些文字:printf("Sucks to be you") 或者使用某个错误号来退出 exit(666),然后让运维人员来做进一步排查(这种区别也是计算机科学和软件工程的不同之处)。
但这并不是说,理论的、抽象的系统模型毫无价值。事实上,恰恰相反,它能帮助我们将复杂真实的系统,提炼为可处理、可推演的有限故障集。据此,我们可以剖析问题,并进行系统性地解决问题。在特定的系统模型下,只要算法满足特定性质,我们就可以证明算法的正确性。 即使算法被证明是正确的,但在实际环境中,其实现并不一定总能够正确运行。不过,这已经是一个很好的开端了,系统的分析能够很快地暴露算法的问题。而在真实系统中,这些问题只有经过很长时间、当你的假设被某些极端情况打破后才可能发现。理论分析(Theoretical analysis)和实践测试(empirical testing)需要并重。
谢谢你读完本文(///▽///)
如果你想尝鲜图数据库 NebulaGraph,记得去 GitHub 下载、使用、(^з^)-☆ star 它 -> GitHub;如果你有更高的性能、易用性、运维实施等方面的需求,你也可以随时 联系我们,获取进一步的帮助哦~



