
用户案例
微众银行:利用 NebulaGraph 进行全局数据血缘治理的实践
本文整理自微众银行大数据平台:周可在 nMeetup 深圳场的演讲,演讲视频参见:B站

公司简介
微众银行是国内首家互联网银行,专注为小微企业和普罗大众提供在线金融服务。为了对全局数据的来源及影响范围进行实时检测和深度分析,从2020年开始微众银行将 NebulaGraph 接入了他们的大数据平台,目前全行 AIOps 都已经接入 NebulaGraph 平台。
业务挑战
- 随着业务的扩展和数据来源的增长,互联网交易风险也呈指数增长。
- 用户的信息来源,分析数据的血缘来源及影响范围决定了业务的稳定性和风险预警。
- 如何在前线业务的压力下快速发现数据问题、快速分析&响应。
解决方案
NebulaGraph 数据血缘治理方案
银行业务开展过程中经常面临着大量数据分析、数据来源分析的问题,基于 NebulaGraph 搭建的数据系统,能够快速导入大规模数据,并进行低时延的实时计算,最终帮助银行生成一份数据地图;它采集了各个数据源的数据,并通过微众自有的大数据平台对数据进行加工存储,最后返回一份全行完整的数据资产 / 数据字典。
此外,NebulaGraph 确保在整个构建过程中,大数据平台的结构完全符合银行数据治理的规范和要求,免除了银行客户的后顾之忧。
血缘数据实时查询:以某个表为起始节点遍历得到上游表和下游表;服务端通过 Nebula Java Client 连接 NebulaGraph 查询得到血缘关系。
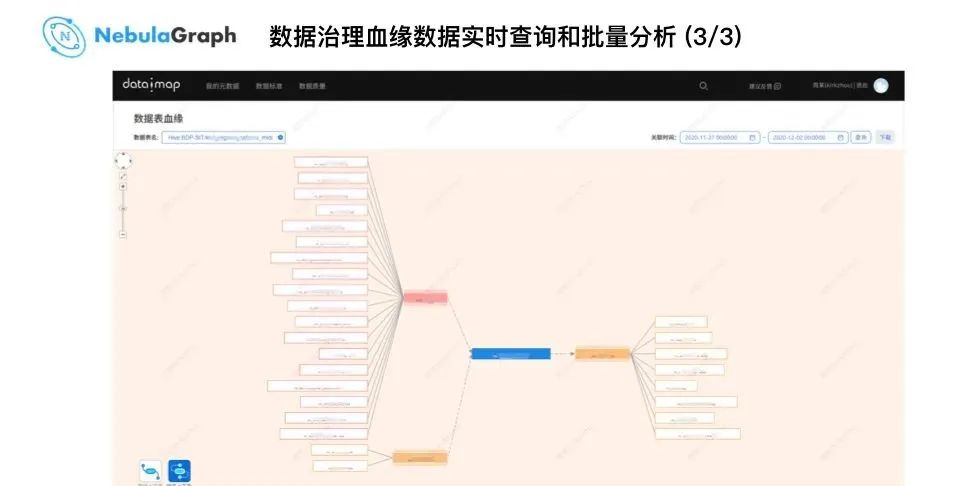
上图就是以蓝色表为中心数据查询下游的一度关系表和上游的一度关系表,NebulaGraph 的大数据平台支持在构建图数据库数据模型时加入时间属性,因此可基于时间维度进行数据过滤和检索,比如:某区域的个人贷款业务表从昨天到今天的数据产生、流转变化情况等,都可以通过快速索引实现实时查询。
血缘数据批量分析:以某个租户、某个部门的表、某个产品的表为起始节点批量分析得到这些表的上游表和下游表的完整链路;大数据任务通过 Nebula Spark Connector 连接 Neubla Graph 批量导入点数据和边数据,使用基于 GraphX 实现的算法批量分析得到完整的血缘链路。
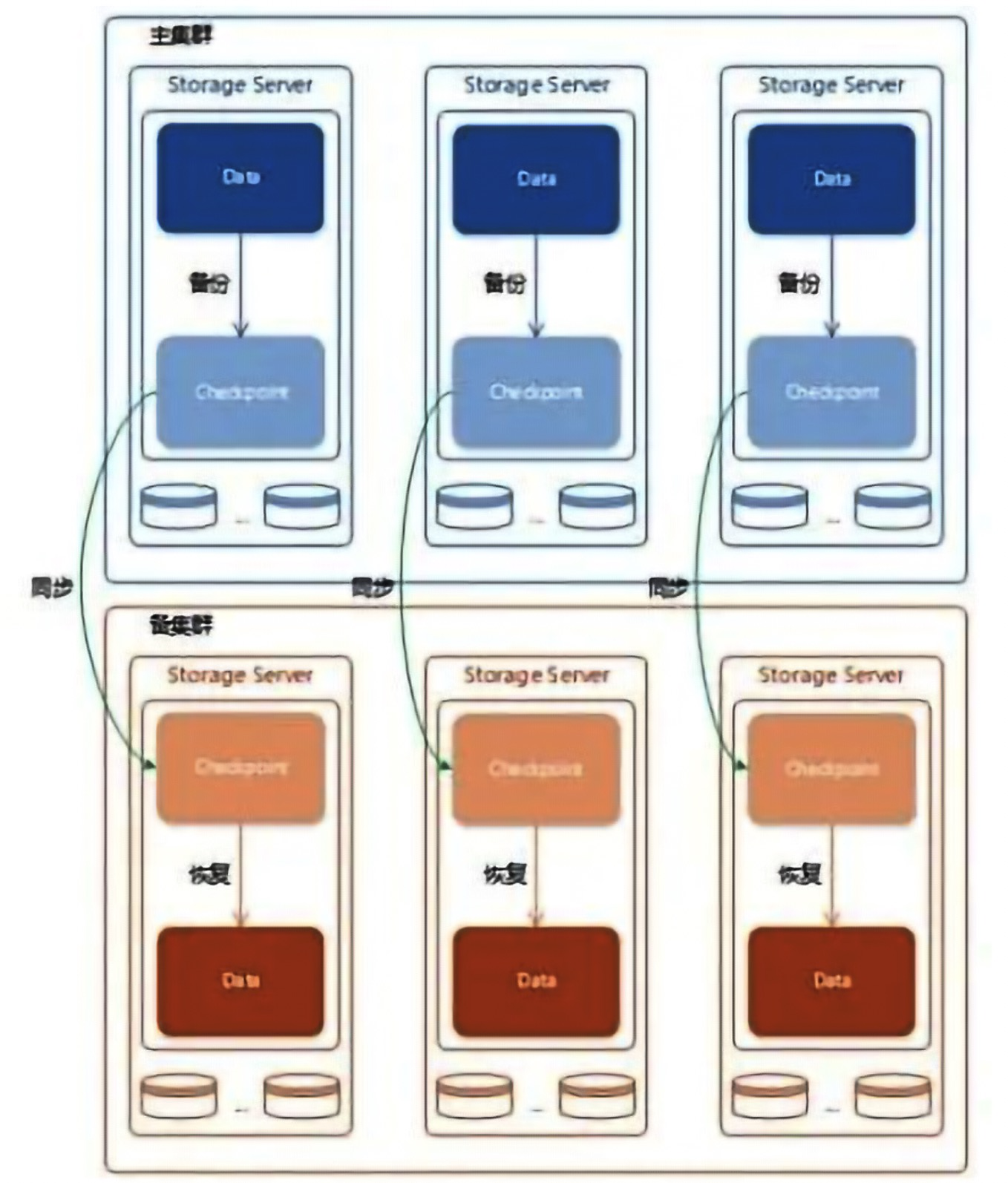
数据异地容灾备份:主要依赖于 NebulaGraph 本身提供的容灾特性,比如:Checkpoint。系统每天将 Checkpoint 做数据备份同步到异地的容灾集群,一旦主集群出问题,即刻切换系统到异地灾备集群,确保数据不丢失不遗漏,大大提高了数据安全性。
技术选型
JanusGraph :
- 性能较差:功能实现依赖其他数据组件,后续稳定性不能保证
- 非分布式:存储依赖Hbase,无法满足银行业“两地三中心”架构规范要求
- 维护成本高:不支持高可用,处理大规模数据需要花成本解决很多技术问题
NebulaGraph:
- 性能更强大:经过测试相较于同类竞品,NebulaGraph 查询和导入性能更优秀
- 原生分布式:支持集群模式,具备存储和计算的横向扩展能力,更加符合银行场景下的分布式和高可用要求
- 生态系统全:Nebula Spark/Flink Connector、NebulaGraph Exchange 提供了和大数据平台数据流结合的能力
- 运维服务好:社区、群组反馈及时
使用效果
大规模数据处理能力提升:NebulaGraph 强一致特性,具较强的读写平衡能力,同时能达到每秒百万行级的导入能力,实现了数据血缘场景下的实时和批量查询的要求。
系统部署成本得到降低:NebulaGraph 分布式及存算分离的架构,具备较好的计算和存储层横向扩展能力及电信级高可用能力,能够满足数据和业务动态扩缩容要求,确保集群运行稳定。
大数据生态兼容性更好:Nebula Spark/Flink Connector、Nebula Exchange提供了良好的大数据生态兼容能力,有效降低了用户使用门槛。
除了产品性能,微众银行更看重是否能满足银行业所要求的安全性架构支持,NebulaGraph 的原生分布式属性正能满足这一要求。除此之外,NebulaGraph 优秀的开源生态能帮助企业构建一个完整的数据流的平台,提高了金融场景下处理大规模数据的效果和速度。
交流图数据库技术?加入 Nebula 交流群请先填写下你的 Nebula 名片,Nebula 小助手会拉你进群~~




