
用户案例
众安保险:NebulaGraph 在金融风控业务的实践

互联网金融的借贷同传统信贷业务有所区别,相较于传统信贷业务,互联网金融具有响应快、数据规模大、风险高等特点。众安保险主要业务是做信用保证保险,为了服务业务,大数据团队搭建了风控系统用于处理互联网借贷的决策问题。本文主要讲述 NebulaGraph 是如何通过众安保险的选型,以及 NebulaGraph 又是如何落地到具体业务场景帮助众安保险解决风控问题。
业务背景
有别于传统银行的信贷业务十天、半个月的申请审核时长,互联网金融借贷第一个特点便是申请审核非常快,可能用户上一秒刚在手机端提交授信申请,下一秒系统便会返回授信申请的结果。此外,互联网金融借贷还有一个特点:数据信息的真实性难以保证,用户填写的信息:年收入、家庭关系、联系人都会存在信息不实的情况。而这两个互联网金融的特点催生了一个产业,就是网络黑产。通俗来说,网络黑产就是用户薅“借贷”羊毛的行为。因为网络借贷隐匿性强,一旦黑产账号实施了欺诈行为后,通过互联网很难追踪到特定的人。此外,由于借贷审批时效性的关系,黑产账号能很方便地做到走量、薅到更多的钱。基于此,催生互联网金融的风控需求,需要系统甄别欺诈场景。
那如何甄别网络黑产呢?通过用户与不同实体、设备、GPS 与手机号之间的关联关系,以及社群发现查看社群中的个体是否有欺诈风险、进行反欺诈的个案调查,能很好地进行借贷风控。目前,众安保险的风控是基于 NebulaGraph 实现的。
为什么选择 NebulaGraph

在众安保险技术选型之初,团队成员调研过图数据库市场的产品,首先筛选出了 JanusGraph、OrientDB。
先来说下 JanusGraph,在众安金融事业技术团队内部 JanusGraph 有一大优势:团队成员对它熟悉,不少工程师使用过 JanusGraph,这从某种程度上降低了图数据库开发、上手成本。使用过 JanusGraph 的研发都知道它是一个分布式图数据库,存储、索引依赖开源组件,例如:HBase(存储)、Elasticsearch(索引)。而之前公司的某个业务线曾使用过 JanusGraph,底层搭载线上 HBase 存储服务,而该业务相对独立和其他核心业务不存在强依赖关系。“不同的国家有不同的国情,一旦相同机制硬搬到不同的国家,可能会出现水土不服问题”,目前众安保险风控业务的基础数据存储在 HBase 中,假如风控系统使用 JanusGraph 的话,将上百亿图数据完全导入 HBase 会对 HBase 集群产生影响、增加查询毛刺,导致其他业务线受到影响。此外,在大规模写入速度性能方面,JanusGraph 导入较慢。综合上述原因,即便 JanusGraph 具有低上手成本,但其强依赖其他组件、导入性能差,所以 JanusGraph pass。
在图数据库产品调研过程中,我们发现 OrientDB 在 DB-Engine 排名较前、功能完善。经过性能测试,发现在小规模数据集下使用 OrientDB 体感良好,但一旦 Mock 数据过亿,大规模数据集下使用 OrientDB 会遇到 Server 端频繁报错问题。查阅 OrientDB 官方文档无果之后,众安保险向 OrientDB 官方 GitHub 仓提交了 issue。但是 OrientDB 反馈响应慢,在提交 issue 的过程中,我们还发现大规模数据集 Server 端频繁报错问题社区用户两年前提交过,issue 仍未解决处于 open 状态。此外,在大规模数据写入性能方面,写入点的速度尚可接受,但写入边的 QPS 只有 1-2k,用这个速度开始图数据建模的话耗时将在天级别,这是不可接受的。综上,虽然 OrientDB 排名靠前、功能完善,但大规模数据频繁 Server 报错、社区 issue 响应慢、大规模写入速度不佳导致最后我们没有选择 OrientDB。
而 NebulaGraph 参与技术选型的契机是,在众安保险开始图数据库选型时,咨询其他公司(京东、携程…)从业人员公司所用图数据库时,他们一致推荐 NebulaGraph。因此,NebulaGraph 成为众安保险图数据库选型的选项之一。而在实际测试中,我们发现 NebulaGraph 大规模写入速度非常快,生产环境测试数据能达到 10w+ QPS。此外,NebulaGraph 存储和索引依赖于本地 RocksDB 库,不依赖于其他大数据组件,符合业务需求。在大数据生态支持方面,NebulaGraph 支持主流的 Spark(nebula-spark-connector)和 Flink(nebula-flink-connector)。在社区响应和反馈时效上,NebulaGraph 也给了我们比较好的体验。
这里额外讲下社区支持,在整个图数据库调研过程中,我们发现相较于成熟的诸如 MySQL、Oracle 此类的 SQL 数据库,图数据库发展时间较短,由此产生的问题是遇到部分图数据库产品问题,搜索引擎能提供的信息较少。像之前 OrientDB 的频繁报错问题,如果社区未能提供及时的技术反馈,对于使用者来说他可能要花费大量时间来阅读源码去 Debug,人力成本便会急剧上升、性价比极低。
而 NebulaGraph 在社区支持跟反馈方面给了众安保险非常良好的体验。作为他们的客户,包括在最早期的 1.0,众安保险给 NebulaGraph 提交了不少使用问题和 bug,Nebula 研发同学都能及时回复和 fix bug。到 2.0 部署时,我们遇到生产部署问题他们也能及时提供技术支持。这一点相比于其他的图数据库厂商,是非常值得推荐的。这也是我们选择 NebulaGraph 作为图数据库来支撑众安保险业务的根本性原因。
金融风控业务实践
下图为众安保险基于 NebulaGraph 的风控系统架构图,它集数据处理、加工清洗、计算、图服务应用为一体。
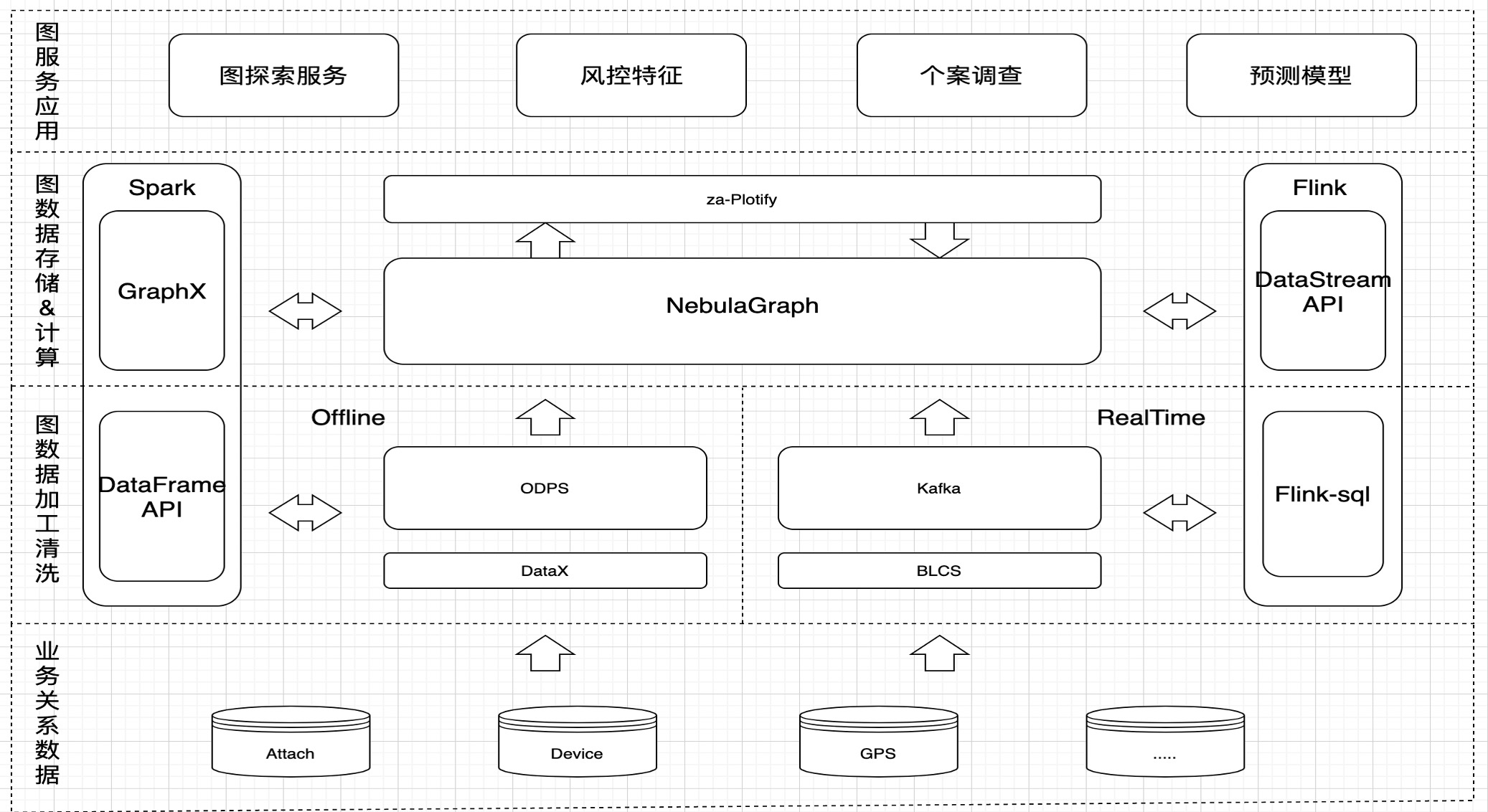
如上图所示,最底层为业务库,不同的业务关系数据存在不同的业务库中,包括用户附件、设备、 GPS、IP 等等信息。
再上层,是由离线数仓和实时数仓构成的图数据库加工清洗层,离线数仓通过 DataX 进行每天 T+1 的数据回流,回流业务库的数据存到 ODPS 中,NebulaGraph 通过 Spark 来读取当中数据并写入到数据库中。在实时数仓方面,通过众安保险内部的监听组件 BLCS 将数据写到 Kafka,再经过 FlinkSQL 搭建的实时数仓进行数据清洗加工,最后通过 Flink 实时地写入到 NebulaGraph 中。为了保证数据的一致性,实时数仓每天进行数据校验,如果数据存在不一致,则会使用离线数据补齐缺失的数据。
数据清洗加工层上面则是存储 & 计算层,存储层不用说自然是 NebulaGraph。而计算方面,通过 NebulaGraph 提供的 Spark Connector 组件,将图数据库中的数据读取到 Spark 平台通过 GraphX 执行预测模型,最后将结果写回 NebulaGraph 中。
最后,通过众安保险的微服务系统将图数据库存储 & 计算对接给上层图应用,提供图探索服务、风控特征、个案调查、预测模型等图服务。
关系图谱
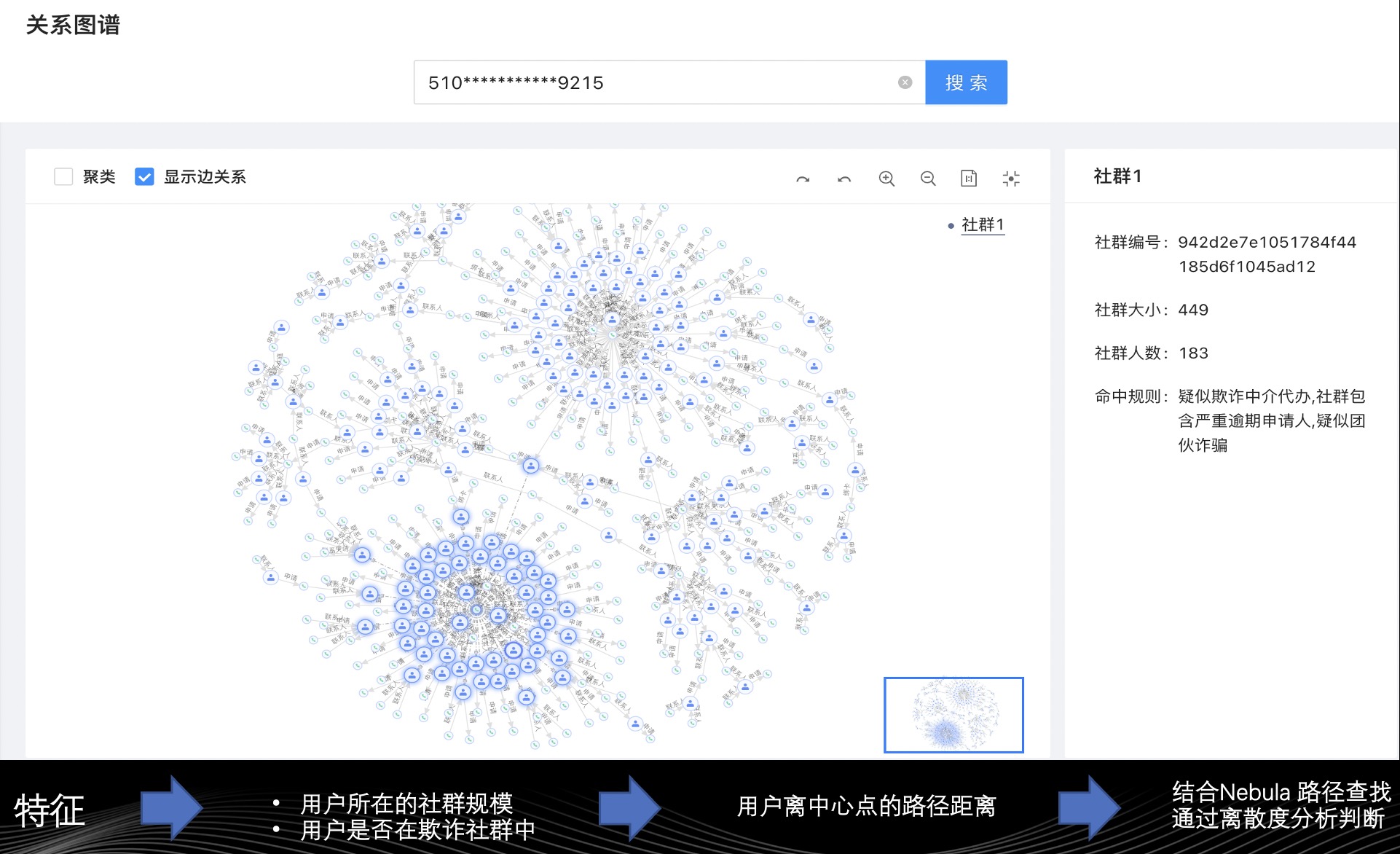
这里简单讲解众安保险内部的图社群探索的关系图谱,通过上图的关系图谱讲解具象化地介绍众安是如何利用图数据库甄别欺诈场景,如何使用图数据库实践风控特性。
上图有 2 类节点:
- 人(蓝色节点)
- 手机(绿色节点)
存在 3 类关系:
- 人-[申请]->手机
- 手机-[联系人]->人
- 人-[绑卡]->手机
第一眼看到上面的图,很明显看到 2 个稠密热点,热点手机号被五、六十填为他的家庭联系人的手机号。按常识来说,当代中国大多独生子女家庭,加上旁系关系,也很难出现五、六十个人同时将同一个手机号填为他的家庭联系人的手机号。所以,这个手机号关联人可能是欺诈团伙分子,黑产团伙可能知晓借贷评分系统中有一环节是对家庭联系人的手机号进行信用评分,团伙希望通过关联高信用分的手机号从而提高信用分。
基于上述特征,我们可以查询用户所在社群的规模、用户是否在疑似欺诈社群中对他进行一个初步风控判断。这里讲述下,即便某个用户处于异常关系网络中也不代表他是个欺诈用户,处于异常社群是个判断用户是否为欺诈分子的充分不必要条件。因为存在一种可能,用户本身并非是欺诈分子,但直系亲戚参与了中介代办、团伙欺诈,此时便会出现正常用户和异常用户都存在同一关系网络的情况。
下一步,我们需要深入挖掘用户和异常中心的“亲密”离散度,探寻它们的路径距离。通过结合 NebulaGraph 本身的路径查找功能,分析离散度(靠近异常点,还是处于社群边缘)从而判断某位用户是否是有欺诈嫌疑。
这里以手机号为例,来帮助大家理解众安是如何通过 Nebula 来识别用户的欺诈场景的。其实众安保险内部还有设备、IP 等等关系图谱,这里不展开赘述。
图模型预测

这部分来介绍下图预测模型,
- Connected Component(贷前)
- Label Propagation(贷中)
- Degree Statistical
刚上面部分介绍的关系图谱是通过联通分量(Connected Component)算法计算得出的,主要应用在贷前的用户授信申请环节。
再来是标签传播(Label Propagation),不同于联通分量,标签传播更多地应用于贷中环节。标签传播主要是通过一个确定的点 Y 去传播、衍生出它相关点。举个例子,贷中用户名单中某个用户是严重逾期人员,这个人员便是打上逾期标签的确定点 Y,结合既定的风控规则查看点 Y 关联延伸的点中哪些点出现相似逾期行为,从而判断这些点是否属于严重逾期的社群。这便是贷中的标签传播算法。
最后一个算法是 Degree Statistical,全图关系度数,主要供风控人员使用。风控人员在做风控特征时,可能会提出几十、上百个图特征,基于这些特征数据需要用历史的数据去验证,查看哪些特征可以真正地识别出欺诈用户或是严重逾期用户。而这个验证过程,如果使用传统数仓通过 ODPS 做深度查询的话,无论在执行效率、耗时,还是在 SQL 代码编写方面,都是一个非常低效的过程。但,通过 NebulaGraph 将点数据读取到 GraphX 中进行全图关系度计算,将 7 度或者是 10 度关系以行的形式写回到 ODPS 中,提供给风控人员使用,可以帮助他们更快地完成风控规则制定、完成风控任务。
未来展望
版本规划
在主题分享时,众安保险所用的 Nebula 版本为 2.0.1,后续 Nebula v2.5.0 中新增水位线 watermark 功能去防止查询遇到稠密热点占用内存过高拖垮 storage 进程的情况。众安保险这边会在测试环境部署 v2.5.0 版本进行验证,验证通过之后,业务线逐步切到 v2.5.0 版本中。
更多应用场景
后续 Nebula 可能应用在数仓的表与字段的血缘依赖、调度平台任务关系的管理中,众安保险基础平台部的同学正在动手用 NebulaGraph 去替换已有的传统实现方案。
本文整理自众安保险的图实践主题分享,可观看下面视频来了解更多详情。
交流图数据库技术?加入 Nebula 交流群请先填写下你的 Nebula 名片,Nebula 小助手会拉你进群~~




