
技术分享
实践分享|记录 NebulaGraph 从 v1.0.0 升级到 v3.6.0 版本的心路历程

环境描述
首先来说下本文的背景信息,主要是从原先用了多年的 v1.0.0 版本升级到 NebulaGraph 最新的 v3.6.0 版本。下面是本文可能会用到的前提信息:
- 当前 NebulaGraph 版本:v1.0.0
- 目标 NebulaGraph 版本:v3.6.0
- nebula-client版本:com.vesoft:client:1.0.0-rc4.20200323
相信 NebulaGraph 社区有很多和我类似用着非最新发行版的企业用户,因为为了保障业务的稳定运行,依旧用着 v2.x.0 版本,或者是和我们一样用着 v1.0.0 版本。所以,很多人会问:升级?为什么要升级呢?
这是我的答案:v3.6.0 版本,或者说最新发行版,会比 v1.0.0 版本具有更高的可维护性和稳定性、更完善的周边生态。此外 NebulaGraph v1.0.0 版本出问题基本上很难得到解决,另外扩缩容比较麻烦。
升级需要考虑的点
和许多依旧用着老版本的用户一样,我们其实也是做了一段时间的挣扎选择了升级。下面是我们想到的升级需要考虑到的点:
1.nGQL 的兼容性;
2.原地升级 or 导出导入的方式?这里我们测试过,原地升级经测试不可用,而且还会影响在线业务,风险大;
3.如何保证升级不影响线上的业务;
4.如何处理升级时产生的增量数据;
5.升级后如何数据一致性比对;
6.如何进行新老 nebula 替换;
如果要排个优先级的话,第 3,5,6 相比其他几点会更重要。
升级方案
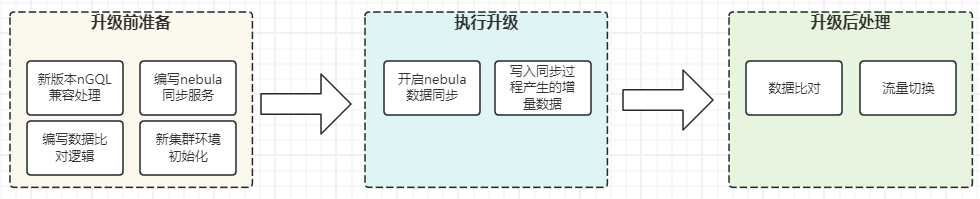
这是大致的升级方案,大体分为三个部分:
升级前准备
有些准备工作需要完成:
1.收集、整合业务线相关的所有 nGQL 并进行 v3.6.0 版本测试,修改 nGQL 以兼容 v3.6.0 版本 nebula。
2.编写 nebula 同步服务,这里无法使用 nebula-spark-connector 进行同步,因为 nebula 版本跨的太大了。
3.编写数据流量比对逻辑。
4.搭建 NebulaGraph v3.6.0 版本新集群环境,这里可以临时关闭自动 Compaction 功能,来加快写入速度。
注意:这里并非在原来的业务应用上进行更新,而是复制一个新的出来,因为同一个应用无法兼容两套不同版本的 nebula。
执行升级
我们这里是借助了 MQ(消息队列,Message Queue)来中间处理了下数据。涉及到 MQ 的步骤有:
1.开启同步过程增量数据写入 MQ 进行积压;
2.开启 nebula 数据同步,应用 A 从 nebula v1.0.0 中读取出来发送到 MQ,然后应用 B 消费 MQ 消息写入到 nebula v3.6.0;
3.同步完毕后将 MQ 中积压的增量数据写入 nebula v3.6.0;
升级后处理
这里再简述下升级之后需要做的操作:
1.数据一致性比对,通过流量复制的方式发送到新的应用上进行重放结果比对;
2.逐步切流量到新 nebula v3.6.0 集群;
内核升级的详细设计
名词说明:
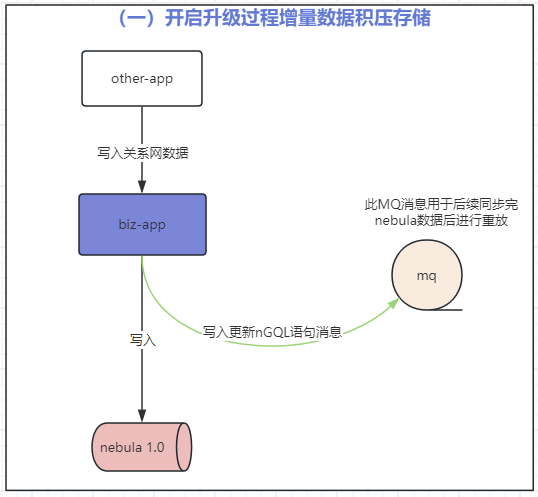
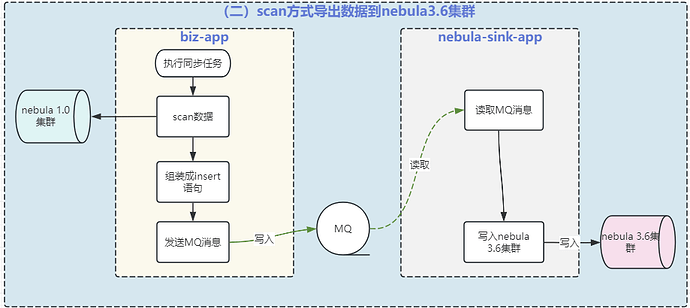
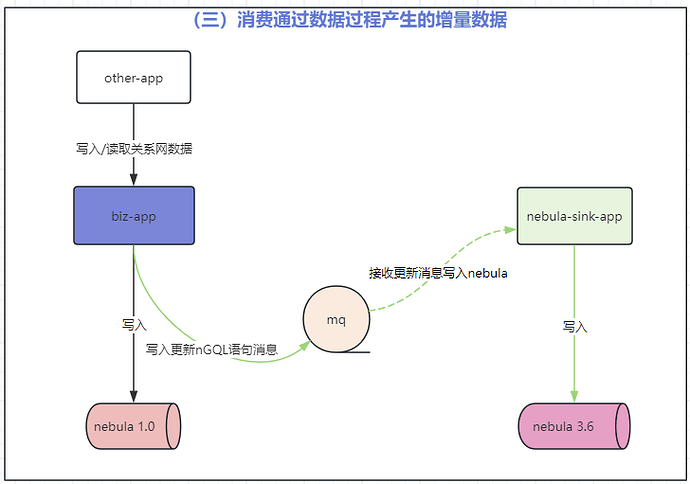
biz-app:业务应用 App,作用连接 nebula v1.0.0 进行图数据操作;
biz-app-new:biz-app 的复制版本,只不过改成了连接 v3.6.0 版本 nebula,并更新 nGQL 以兼容 nebula v3.6.0;
nebula-sink-app:用于接收 nebula v3.6.0 版本的更新语句消息,并写入到 nebula v3.6.0 集群;
第一步:开启增量数据写入 MQ 积压
第二步:同步 nebula v1.0.0 数据到 v3.6.0 集群
第三步:同步完毕后消费增量数据
第四步:数据一致性比对
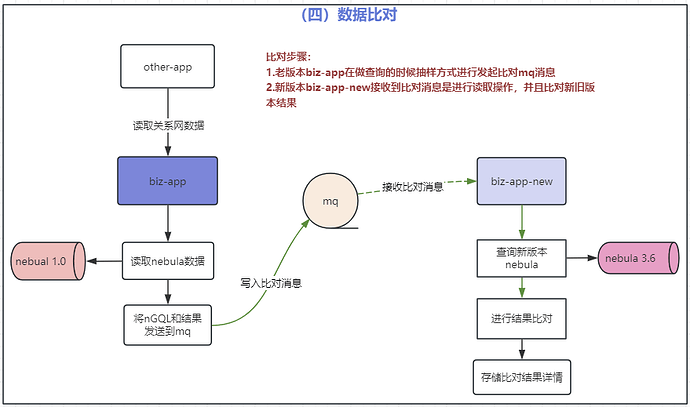
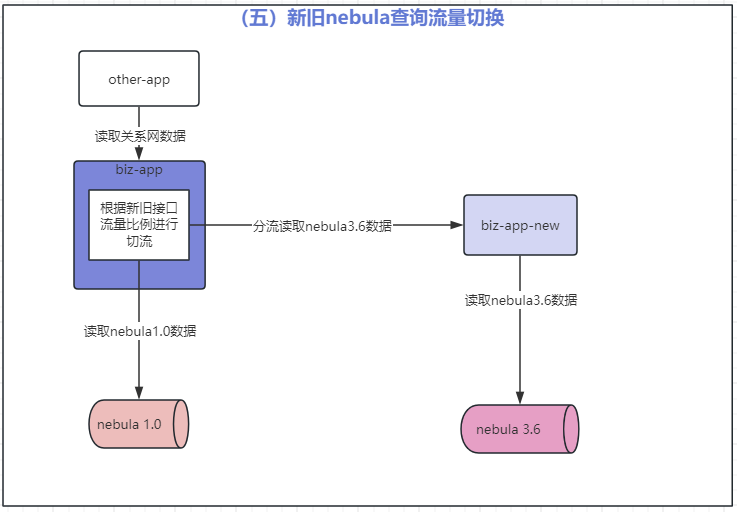
第五步:nebula v3.6.0 集群切流
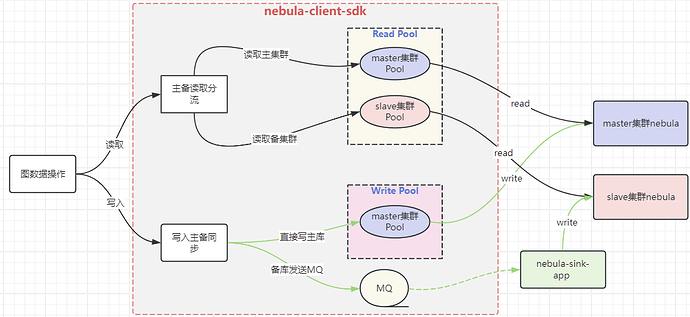
nebula-client v3.6.0 版本 SDK 改造
本次客户端的改造,主要是支持下面功能:主备写入同步、主备读取分流、读写 SessionPool 隔离、连接池监控、nGQL 执行监控。
遇到的问题以及解决方案
当然升级不是一步到位,我们也遇到了不少的问题。这里罗列了几个印象深刻的错误:
导出 Timestamp 属性字段报错
无法导出多版本数据(Schema 发生更改)
每次 Scan 中断只能从头开始,无法接着上次的 cursor 继续导出
指定扫描单个 Edge 或者 Tag 出现磁盘 IO 使用率100%(见:nebula v1.0.0 版本导出部分边或者点出现磁盘 IO 负载过高)
好在的是,这些问题我们都顺利解决了。下面来讲讲我们的解决方案:
导出 Timestamp 属性字段报错
这个问题产生的原因是因为 RowReader.java 中不支持 TIMESPTMP 字段。
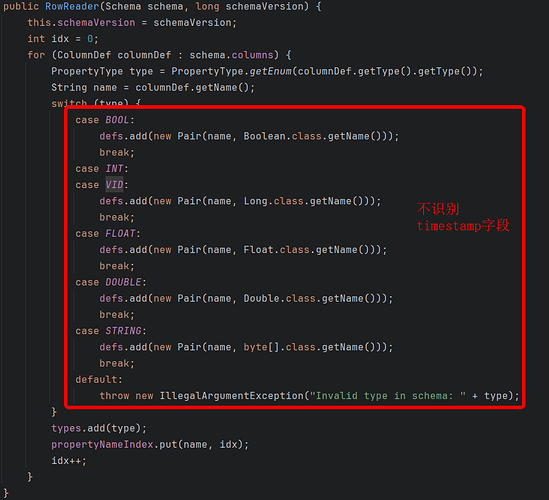
解决方案:
重写 RowReader 代码支持 Timestamp 字段:
`public RowReader(Schema schema, long schemaVersion) {
this.schemaVersion = schemaVersion;
int idx = 0;
for (ColumnDef columnDef : schema.columns) {
PropertyDef.PropertyType type = PropertyDef.PropertyType.getEnum(columnDef.getType().getType());
String name = columnDef.getName();
switch (type) {
case BOOL:
defs.add(new Pair(name, Boolean.class.getName()));
break;
case INT:
// 这里加入TIMESPTMAP属性识别
case TIMESTAMP:
case VID:
defs.add(new Pair(name, Long.class.getName()));
break;
case FLOAT:
defs.add(new Pair(name, Float.class.getName()));
break;
case DOUBLE:
defs.add(new Pair(name, Double.class.getName()));
break;
case STRING:
defs.add(new Pair(name, byte[].class.getName()));
break;
default:
throw new IllegalArgumentException("Invalid type in schema: " + type);
}
types.add(type);
propertyNameIndex.put(name, idx);
idx++;
}
}
public Property[] decodeValue(byte[] value, long schemaVersion) {
List<byte[]> decodedResult = NebulaCodec.decode(value, defs.toArray(new Pair[defs.size()]),
schemaVersion);
Property[] properties = new Property[defs.size()];
try {
for (int i = 0; i < defs.size(); i++) {
String field = defs.get(i).getField();
PropertyType type = types.get(i);
byte[] data = decodedResult.get(i);
switch (types.get(i)) {
case BOOL:
properties[i] = getBoolProperty(field, data);
break;
case INT:
// 加入TIMESTAMP识别
case TIMESTAMP:
case VID:
properties[i] = getIntProperty(field, data);
break;
case FLOAT:
properties[i] = getFloatProperty(field, data);
break;
case DOUBLE:
properties[i] = getDoubleProperty(field, data);
break;
case STRING:
properties[i] = getStringProperty(field, data);
break;
default:
throw new IllegalArgumentException("Invalid type in schema: " + type);
}
}
} catch (BufferUnderflowException e) {
LOGGER.error("Decode value failed: " + e.getMessage());
}
return properties;
}
`
无法导出多版本数据(Schema 发生更改)
这个原因是 ScanVertexProcessor 和 ScanEdgeProcessor 仅支持一个版本的数据解析:
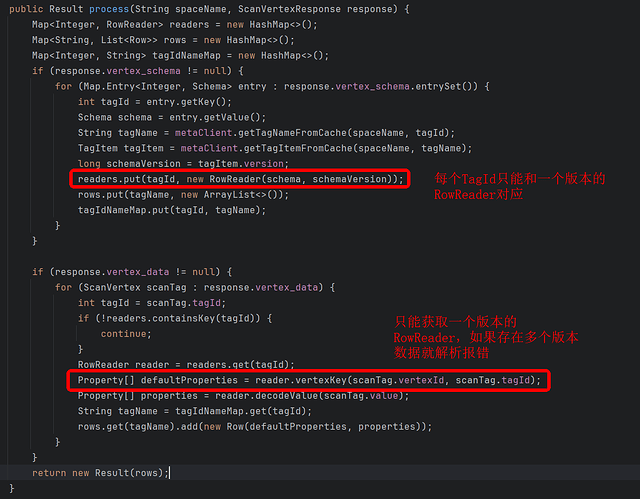
解决方案:重写 ScanVertexProcessor 和 ScanEdgeProcessor 自动识别多版本数据:
`public TagItem getSpecialVersionTagItem(String spaceName, int tagId, long version) {
if (!spaceTagItemVersions.containsKey(spaceName)) {
Map<Integer, Map<Long, TagItem>> tagVersionMap = Maps.newHashMap();
List<TagItem> allTagItemList = getTags(spaceName);
if (!allTagItemList.isEmpty()) {
allTagItemList.forEach(tagItem -> tagVersionMap.computeIfAbsent(tagItem.getTag_id(), k -> Maps.newHashMap()).put(tagItem.getVersion(), tagItem));
spaceTagItemVersions.put(spaceName, tagVersionMap);
}
}
Map<Integer, Map<Long, TagItem>> tagVersionMap = spaceTagItemVersions.get(spaceName);
if (Objects.isNull(tagVersionMap)) {
return null;
}
return tagVersionMap.getOrDefault(tagId, Collections.emptyMap()).get(version);
}
private RowReader getRowReader(String spaceName, ScanVertex scanTag, Map<Integer, RowReader> readers) {
int tagId = scanTag.getTagId();
// 解析当前tag数据的schema版本
long schemaVersion = NebulaUtils.parseSchemaVersion(scanTag.getValue());
Map<Integer, Map<Long, RowReader>> tagVersionReaderMap = spaceTagVersionReaders.computeIfAbsent(spaceName, k -> new ConcurrentHashMap<>());
Map<Long, RowReader> versionReaderMap = tagVersionReaderMap.computeIfAbsent(tagId, k -> new ConcurrentHashMap<>());
RowReader reader = versionReaderMap.get(schemaVersion);
if (reader != null) {
return reader;
}
//构建对应schema版本的RowReader
TagItem tagItem = metaClient.getSpecialVersionTagItem(spaceName, tagId, schemaVersion);
if (tagItem != null) {
log.debug("Add special version tagItem | spaceName:{} | tagId:{} | schemaVersion:{}", spaceName, tagId, schemaVersion);
versionReaderMap.computeIfAbsent(schemaVersion, k -> new RowReader(tagItem.schema, tagItem.version));
return versionReaderMap.get(schemaVersion);
}
RowReader rowReader = readers.get(tagId);
if (rowReader == null) {
log.error("Not match vertex reader | spaceName:{} | tagId:{} | schemaVersion:{} | data={}", spaceName, tagId, schemaVersion, Hex.encodeHexString(scanTag.value));
}
return rowReader;
}
//解析数据的schema版本,根据nebula源码翻译成的java代码
public static long parseSchemaVersion(byte[] row) {
if (row == null || row.length == 0) {
System.err.println("Row data is empty, so there is no schema version");
return 0;
}
// The first three bits indicate the number of bytes for the
// schema version. If the number is zero, no schema version
// presents
int verBytes = row[0] >> 5;
int ver = 0;
if (verBytes > 0) {
if (verBytes + 1 > row.length) {
// Data is too short
// System.err.println("Row data is too short");
return 0;
}
// Schema Version is stored in Little Endian
for (int i = 0; i < verBytes; i++) {
ver |= ((int) row[i + 1] << (8 * i));
}
}
return ver;
}
`
每次 Scan 中断只能从头开始,无法接着上次的 cursor 继续导出
这个问题发生的原因是因为 StorageClient 中的 scan 方法并未支持 cursor 参数传入:
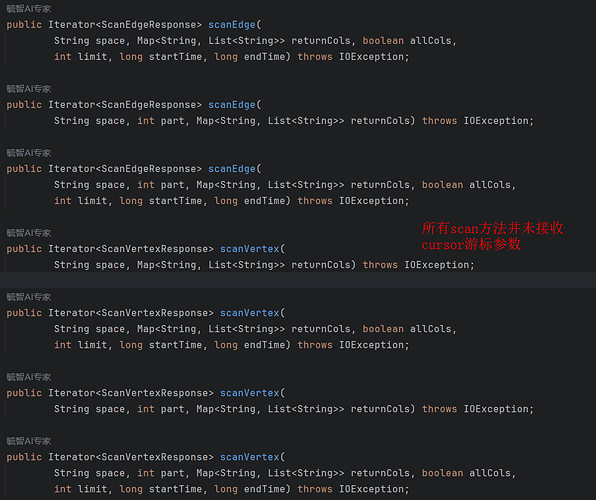
解决方案:重写 StorageClient 提供可传入 cursor 参数,每次 next 之后将 cursor 保存到数据库中,中断重新跑的时候使用之前的 cursor:
`//增加cursor参数
public Iterator<ScanVertexResponse> scanVertex(
String space, int part, Map<String, List<String>> returnCols, boolean allCols,
int limit, long startTime, long endTime, byte[] cursor) throws IOException {
HostAndPort leader = getLeader(space, part);
if (Objects.isNull(leader)) {
throw new IllegalArgumentException("Part " + part + " not found in space " + space);
}
int spaceId = metaClient.getSpaceIdFromCache(space);
ScanVertexRequest request = new ScanVertexRequest();
Map<Integer, List<PropDef>> columns = getVertexReturnCols(space, returnCols);
request.setSpace_id(spaceId)
.setPart_id(part)
.setReturn_columns(columns)
.setAll_columns(allCols)
.setLimit(limit)
.setStart_time(startTime)
.setEnd_time(endTime)
//设置cursor参数到request中
.setCursor(cursor);
return doScanVertex(space, leader, request);
}
`
指定扫描单个 Edge 或者 Tag 出现磁盘 IO 使用率 100%
问题的原因:当 Space 中部分点或者边数量极大(比如几百亿),部分点或者边数据极小(比如几百万),当扫描极小的点或者边的时候就会出现磁盘 IO 使用率 100%;
解决方案:以扫描所有的点或者边,不指定单个 Edge 或者 Tag。
nebula 同步服务设计
设计原则:
导出时不能影响线上 nebula 服务
尽量充分使用 nebula 服务资源进行同步
能够实时监控同步进度
可以随时停止/启动同步任务
设计要点:
自动适配不同时间段,不同导出频率和单次扫描数据量
根据 nebula 服务器的压力自动调整扫描任务数和频率
自动将扫描任务均衡到每台 nebula 服务器,避免出现 nebula 集群服务器负载不一致的情况
重点问题解决
这里着重讲讲如何解决一些具体的问题:
问题:每台 nebula-storaged 节点有着不同的 partition 分布,处理扫描任务越多 nebula-storaged 服务器负载就越高,如何实现每台 nebula-storaged 处理 Scan 扫描任务的数量一样?
解决方案:
1.改造 StorageClient 支持指定 storage address 进行 scan 操作;
2.通过 nebula-client 执行 show parts 拿到每个 part 对应的 leader 分布;
3.根据 part 对应 leader 分布,即可进行指定 part 同步均衡到每台 nebula-storaged 服务器上。
问题:如何做自动同步流控,主要针对源头 nebula,也就是从哪里导出。
主要从 3 个方面解决问题:
1.扫描频率
2.扫描行数
3.scan 任务数
扫描流控:
`//开启SCAN操作并指定游标,此游标是上次scan保存下来的
Iterator<RESP> iterator = scan(client, space, tagOrEdgeNameList, part, statusDomain.getNextCursor());
boolean isScanLimitConfigIterator = (iterator instanceof ScanLimitConfigIterator);
while (iterator.hasNext()) {
if (isScanLimitConfigIterator) {
//设置scan行数,这里根据不同的时间段、机器的负载返回不同的值
int scanLimit = nebulaScanLimitController != null ? nebulaScanLimitController.getLimit() : this.scanLimit;
((ScanLimitConfigIterator<?>) iterator).setScanLimit(scanLimit);
}
Result<RESP> result = scanNext(dataProcessor, iterator);
//将查询结果组装成insert语句并发送到MQ
writeResult(result);
//保存游标到数据库中
saveNextCursor(result.getResp());
//控制扫描频率
Optional.ofNullable(nebulaScanFlowController).ifPresent(flowController -> flowController.controlConsumeFlow(storageIp));
}
`
scan 任务自动缩减:
`private void autoReduceTask() {
log.debug("Start autoReduceTask....");
//从数据库中查询当前处理的任务列表
List<NebulaDataScanTaskEntity> taskList = queryProcessingTaskList();
//遍历处理中的任务列表,统计每台机器当前处理的任务数量,如果超过限制,则停止超出任务
List<NebulaDataScanTaskEntity> needCancelTaskList = calCancelTaskList(taskList);
if (needCancelTaskList.isEmpty()) {
log.debug("AutoReduceTask is fail, needCancelTaskList is empty");
return;
}
Set<Long> cancelTaskIdList = needCancelTaskList.stream().map(NebulaDataScanTaskEntity::getId).collect(Collectors.toSet());
log.info("Need cancel task list: {}", cancelTaskIdList);
//取消需要停止的任务
cancelSpecialTask(cancelTaskIdList);
}
//计算需要取消的任务列表
private List<NebulaDataScanTaskEntity> calCancelTaskList(List<NebulaDataScanTaskEntity> taskList) {
Map<String, List<NebulaDataScanTaskEntity>> nodeProcessingTaskCountMap = taskList.stream().collect(Collectors.groupingBy(NebulaDataScanTaskEntity::getScanStorageHost));
List<NebulaDataScanTaskEntity> needCancelTaskList = new ArrayList<>();
for (Map.Entry<String, List<NebulaDataScanTaskEntity>> et : nodeProcessingTaskCountMap.entrySet()) {
List<NebulaDataScanTaskEntity> nodeProcessingTaskList = et.getValue();
//根据节点并发限制(也就是一个nebula-storaged节点能处理几个scan任务),计算需要停止的任务
int nodeConcurrencyLimit = nebulaNodeConcurrencyLimitController.getNodeConcurrencyLimit(HostAndPort.fromString(et.getKey()).getHostText());
if (nodeProcessingTaskList.size() > nodeConcurrencyLimit) {
//这里根据id进行排序,为了解决多机器并发取消问题
Collections.sort(nodeProcessingTaskList, Comparator.comparing(NebulaDataScanTaskEntity::getScanTotalRowCount));
needCancelTaskList.addAll(nodeProcessingTaskList.subList(0, nodeProcessingTaskList.size() - nodeConcurrencyLimit));
}
}
return needCancelTaskList;
}
`
流控配置信息:

以上,便是我完成的内核升级工作的分享。如果有你想了解更具体的细节,请留言评论。
作者:江一旺
校对 & 编辑:kristain
对图数据库 NebulaGraph 感兴趣?欢迎前往 GitHub ✨ 查看源码:https://github.com/vesoft-inc/nebula;



