
产品实践行业科普
GraphX 图计算实践之模式匹配抽取特定子图

前言
NebulaGraph 本身提供了高性能的 OLTP 查询可以较好地实现各种实时的查询场景,同时它也提供了基于 Spark GraphX 的 nebula-algorithm 库以便支持实时的图算法,这里给 Nebula 点个赞,很不错!
但实践过程中,我发现部分 OLAP 场景中,想实现模式匹配分析,Nebula 的支撑就显得不那么完善了。
这里我对模式匹配的解释是:在一张大图中,根据特定的规则抽取出对应的子图。
举一个简单的例子,比如想要对每个点都进行二度扩散,并按照一定逻辑过滤,最终保留符合要求的二度扩散的子图,这样的任务用 nebula-algorithm 就不太好实现了。
当然,上面这个例子我们可以通过编写 nGQL 语句——查询出对应的数据,但 Nebula 的优势在 OLTP 场景,针对特定点进行查询。对于全图数据的计算,无论是计算架构还是内存大小都不是特别适合的。所以,为了补充该部分(模式匹配)的功能,这里使用 Spark GraphX 来满足 OLAP 的计算需求。
GraphX 介绍
GraphX 是 Spark 生态的一个分布式图计算引擎,提供了许多的图计算接口,方便进行图的各项操作。关于 GraphX 的基础知识我这里不进行过多的介绍了,主要是介绍一下实现模式匹配的思路。
实现模式匹配主要是依赖于一个重要的 API:PregelAPI,它是一种 BSP(BSP:Bulk Synchronous Parallel,即整体同步并行)计算模型,一次计算是由一系列超步实现的。
只看定义不是特别好理解,所以直接介绍它在 GraphX 中的实现,了解它是如何使用的。
Pregel 运行原理
源码定义如下:
def pregel[A: ClassTag](
initialMsg: A,
maxIterations: Int = Int.MaxValue,
activeDirection: EdgeDirection = EdgeDirection.Either)(
vprog: (VertexId, VD, A) => VD,
sendMsg: EdgeTriplet[VD, ED] => Iterator[(VertexId, A)],
mergeMsg: (A, A) => A)
: Graph[VD, ED] = {
Pregel(graph, initialMsg, maxIterations, activeDirection)(vprog, sendMsg, mergeMsg)
}
相关参数含义如下:
- initialMsg: 节点的初始化信息,调用 vprog 函数处理 initialMsg;
- maxIrerations:最大迭代次数;
- activeDiraction:控制 sendMsg 发送的方向,只有满足方向要求的三元组才会进入下一次迭代;
- vprog:更新节点信息的函数。节点收到消息后,执行相关逻辑更新节点信息;
- sendMsg:节点和节点之间发送消息,参数为一个三元组,并且满足 activeDiraction 的方向条件,把消息 Msg 发送给 VertexID,VertexID 可以是 src 点也可以是 dst 点;
- mergeMsg:当同一个 VertexID 接收到多条消息时,合并多条消息为一条,便于 vprog 处理。
只看定义和逻辑同样不太清楚,所以下边再介绍一下 Pregel 的迭代流程:
- 对于一个 graph 对象,只有激活态的点才会参与下一次迭代,激活态的条件是完成了一次发送/收到消息 A 的动作;
- 首先初始化所有节点,也就是每个点都调用一次 vprog 方法,参数为 initialMsg,这样使所有节点都在激活态;
- 然后是将图划分为若干三元组 Triplet,三元组的组成是:src点,edge,dst 点,只保留激活点 activeDirection 方向的三元组;
- 执行 sendMsg 方法,将消息 A 发送给一个 VertexID 的点,由于返回值是一个 Iterator,也就是可以同时给 src、dst 发送消息,若发送 Iterator.empty 则认为没有发送消息;
- 由于一个 VertexID 的点会收到多条消息,所以调用 mergeMsg 方法合并消息,合并为一个 A;
- 合并之后调用 vprog 更新节点的消息,这样就完成了一次迭代;
- 重复 3-6 的步骤,执行 maxIterations 次迭代或者所有的点都不是激活态则退出,完成 Pregel 的所有计算。
模式匹配的思路
知道 Pregel 的计算原理之后,那么怎么实现模式匹配呢,主要就是根据迭代的思想,不停地将边信息聚合到点上,在迭代的过程中控制发送消息的逻辑来实现特定模式的路径。
我们可以定义消息为多条路径的集合,发送消息时就是对发送点的路径集合中,每条路径都增加一个边 e,这样就实现了路径的遍历,其实对于一个点来说,本质就是一个广度优先遍历的过程。
还是以二度查询为例,看如下例子:
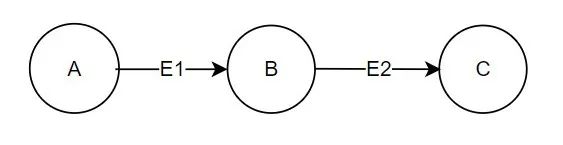
首先,对每个点都执行一次初始化,每个点的属性为一个空的路径集合,路径集合使用二维数组表示,使所有点成为激活态。
然后,进行第一次迭代,可以看到会有两个三元组 A-E1->B,B-E2->C,那么很容易可以得到这次迭代的结果:A:[],B:[[E1]],C:[[E2]]
再进行第二次迭代,这里要做限制,已经发送过的路径不再发送,也就是判断 E 是否已被接收了,防止重复发送的情况。所以第二次迭代的结果就只有 B-E2->C 这个三元组有效,也就是把 B 的集合中的每条路径分别增加一个 E2,并发给 C,C 将路径合并即可,那么结果就是:A:[],B:[[E1]],C:[[E2],[E1,E2]]。
此时 C 节点上的集合中就有了 E1,E2 两条边,刚好是 A 节点 2 度遍历的结果。
这里举的是简单例子,只是说明这样的一个思路,核心逻辑就是传递边来实现路径遍历,实际上每个节点会收到许多点的信息,那么可以将点的结果进行过滤,按照头结点分组即可。实现看如下例子:
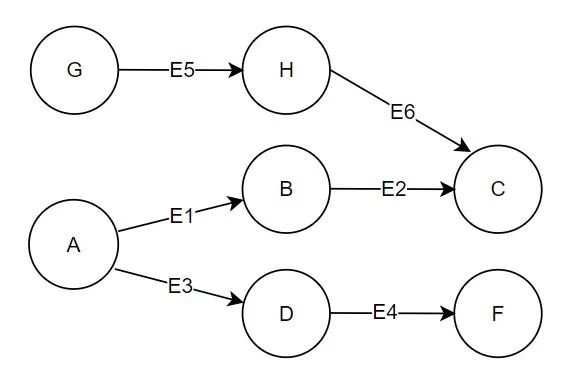
在这个例子中根据要求,能得到的结果就是 A 和 G 的2度路径子图,迭代的结果我不再赘述,直接列出C,F节点的属性:C:[[E2],[E6],[E1,E2],[E5,E6]],F:[[E4],[E3,E4]],当然点 H,B,D 也有路径,但其实可以清楚的看到想要的结果是在 C,F 节点上的。
那么,结果有了但它是分散的,怎么合并起来呢?我们可以将每个点路径的第一个边的起始点拿出来作为 key,因为迭代时每条路径是有序的,其实这个 key 就是目标点,比如 E1,E3 的起始点都是 A,E5 的起始点是 G,我们将每条路径都增加一个key,变更为key:path,过滤掉小于 2 条边的路径,再按照key分组,就得到了目标点对应的子图路径了,这样是不是就拿到了 A 和 G 各自的2度点边了呢!
思路延伸
2 度扩散这个例子还是比较简单的,实际业务中,会有很多的情况,当然图的结构也会比较复杂,比如:
- 不同标签的点如何遍历
- 不同类型的边如何遍历
- 出现环路如何解决
- 边的方向是有向还是无向
- 多条边如何处理
- …
等等的这些问题,但是核心点不变,就是基于 Pregel 实现广度优先遍历,累积边形成路径信息,主要的逻辑基本都在于 sendMsg 这个方法,来控制发或者不发,来决定路径的走向,以满足模式匹配的业务要求。一次迭代就是积累一层的路径信息,所以迭代次数与图的深度一致。在迭代完成后,每个点上都有一些结果,他们可能是中间结果,也可能是最终结果,一般按照指定 key(一般是头结点)分组再进行一些业务逻辑的过滤(比如路径长度),即可得到指定结构的子图,接下来就可以用于业务的分析操作了。
此外,还可以借助 GraphFrames 来实现诸如:二度扩散,这种简单的模式匹配。通过使用类似 Spark SQL 的算子,十分容易的得到计算结果,大大减少代码的难度。但是由于文档较少,又不如 GraphX 多种算子的灵活,对于复杂的模式还是不太推荐的,感兴趣的可以去了解一下。
总结
利用 GraphX 的 Pregel API 进行广度优先遍历来实现模式匹配的好处:
- GraphX 有多种图算子可以灵活处理图数据;
- 基于 Pregel,使用路径当做消息可以灵活控制模式子图的结构,理论上可以实现任何结构的模式提取;
- 能够支持较大数据量的全图模式匹配,弥补 Nebula 图库 OLAP 的不足;
- 无缝集成到大数据生态圈,方便结果的分析使用。
使用这种方式虽然能够实现模式匹配,但是也有很多缺点,比如说:
- 每次迭代的消息都是路径集合,越往后消息会越大,导致 JOIN 的数据量很大,内存占用较高。可以通过优化过滤掉不必要发送的信息来解决;
- 迭代的次数有限,太多了则会出现内存爆炸,不过一般业务中超过 10 层以上的情况也很少;
- 由于节点 ID 通常是 String,需要提前做映射表,计算完又要转换回来,导致计算过程中 shuffle 的次数很多。
针对上面问题,如果你有更好的实现方案,或者通过其他计算引擎能够更好的实现,请务必与我交流指导!
最后,虽然 GraphX 使用起来上手有一定难度,计算也高度依赖内存,但瑕不掩瑜它仍然是一款优秀的图计算框架,尤其是分布式的特性能够进行大量数据的计算,同时 Spark 又能较好地与大数据生态集成,又有官方提供的 nebula-spark-connector 方便读写 Nebula 数据,使用起来还是非常不错的。
我的分享就到这里了,欢迎大家交流更好想法!
我是繁凡,一名大数据开发工程师,目前从事图谱产品开发,致力于大规模图数据在业务中的使用。最近使用 GraphX 实践了一些业务要求的模式匹配开发,在这里分享一些使用的思路。
交流图数据库技术?加入 Nebula 交流群请先填写下你的 Nebula 名片,Nebula 小助手会拉你进群~~



