
用户案例
阿里妈妈百亿级营销实践|NebulaGraph 赋能淘宝天猫精准营销
交流图数据库技术?加入 Nebula 交流群请先填写下「你的 Nebula 名片」,Nebula 小助手会拉你进群~~
导读:阿里妈妈团队基于 NebulaGraph 构建了百亿级实时营销推荐系统,赋能淘宝天猫精准营销。本文整理自宋铭涛老师在北京 nMeetUp 上的分享。
作者宋铭涛(承开),阿里妈妈广告技术部超融合数据架构工程师。
一、业务背景
(一)阿里妈妈
阿里妈妈是阿里巴巴集团旗下商业数字营销平台,阿里妈妈依托淘宝、天猫等平台的用户数据和交易数据,为商家提供精准营销服务。例如,淘宝/天猫商家可通过阿里妈妈进行直通车推广、人群定向投放等操作。
阿里妈妈营销引擎团队专注于广告领域的研究与开发,利用淘宝内外的海量用户行为数据,致力于构建一个基于阿里大数据的支持广告主实时洞察投放策略、精准定位投放人群以及优化投放效果分析的交互式系统。
我们的合作伙伴众多,面临的业务场景复杂多变,技术挑战巨大。
(二) 引入 NebulaGraph 的背景
到 2024 年末,经过与相关团队就特定问题场景的深入交流,我们意识到许多场景非常适合采用图数据库技术。此外,随着大规模模型 RAG 等需求的增长,对图数据的需求也日益增加。
因此,我们对 Neo4j、BlazeGraph、DGraph 和 NebulaGraph 等图数据库进行了测试与调研,最终选择了 NebulaGraph 作为解决方案:
- 在性能对比中,NebulaGraph 表现优异,超过了包括 Neo4j、DGraph 和 TuGraph 在内的图数据库。
- NebulaGraph 的架构设计允许存储和计算能力的横向扩展,这对我们复杂的使用场景尤为重要。
- NebulaGraph 拥有丰富的基础设施,便于参考整合,并支持二次开发。

二、应用场景
(一)同款异常点检测
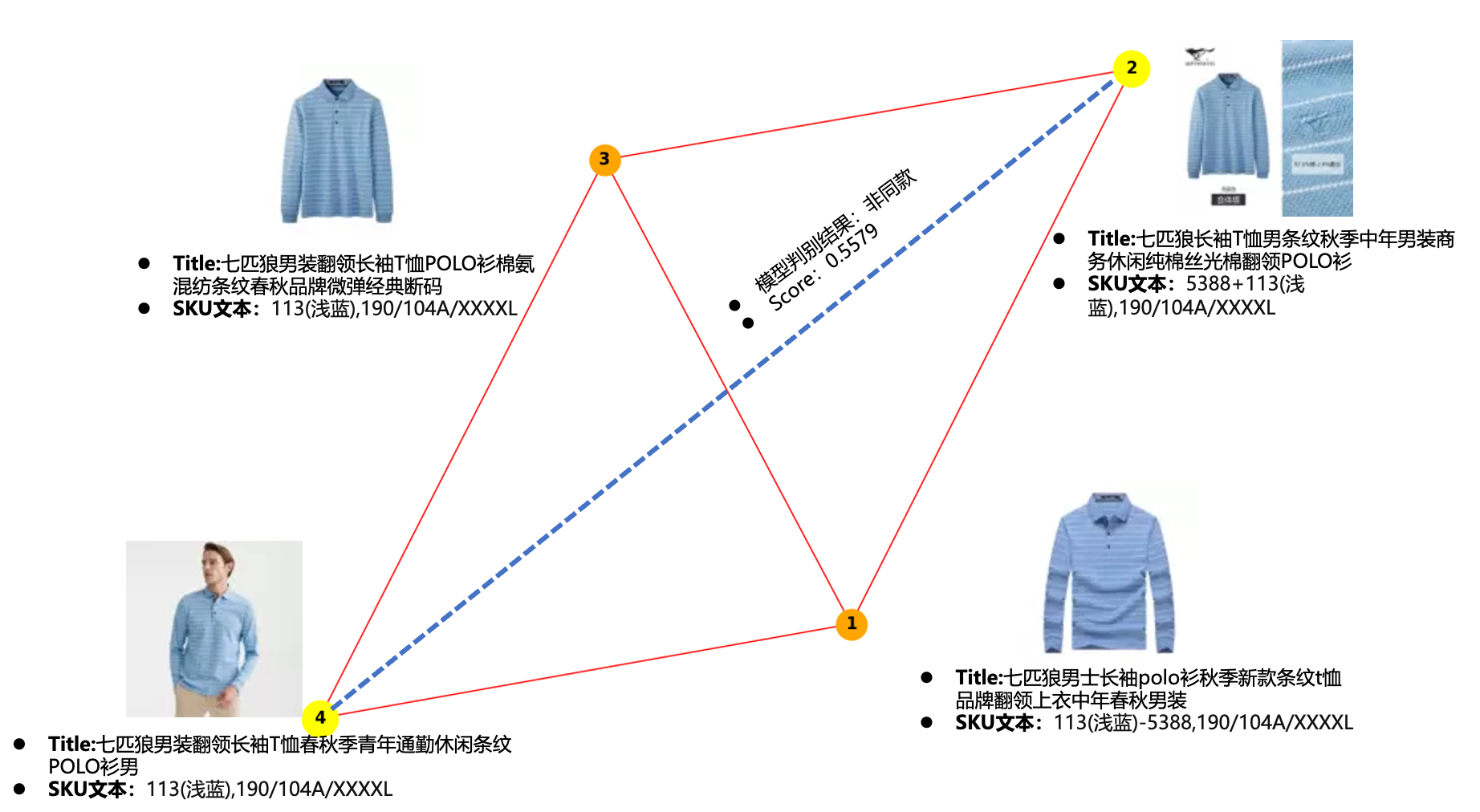
淘宝或者天猫的需求场景中,同款和相似款的应用场景很多,其中一个实现方式是,使用分类器对于同款商品集做分类提取,在算法理想 work 的情况下,同款商品簇内的两两商品直接互为同款。
但现实是:算法模型本身的运行设置、机器运算、数据问题等原因导致误差传递,进而使得本应该判断为同款的商品,得到置信度很低的值,成为异常点。
比如图中商品 2 和商品 4 在文本表述和图像上存在一定的区别,模型将两个商品判断为非同款,但是置信度不高,只有 0.5579. 而通过两个 SKU 本身信息和商品的邻接信息可知,这两个 SKU 应该是同款。
在该场景下,我们使用 NebulaGraph 对相关数据进行建模,信息如下:
Schema
- 点(Vertex):代表一个商品
- 点(Vertex)Tag:点的属性,可以包括商品多模态表征、图像表征等
- 边(Edge):商品之间是否为同款,已经对应的 score,后续可以添加图像相似度等信息
查询使用 k-hop 子图查询
- 输入:待预测的 pair
- 输出:k-hop 子图(主要关注 1-hop 和 2-hop)和子图节点的 feature
通过引入 NebulaGraph 图数据结构,在同款离群点检测的已有成熟链路中,AB 实验结果提升了 2 个pt.
(二)其它 case
我们也在用 NebulaGraph 做 GraphRAG 的相关工作,另外,风控算法团队也在用 NebulaGraph 进行黑产团伙识别、异常用户检测等。
三、服务架构
为了更好地借助 NebulaGraph 实现业务需求,基于我们的基建,我们搭建了以下服务架构。
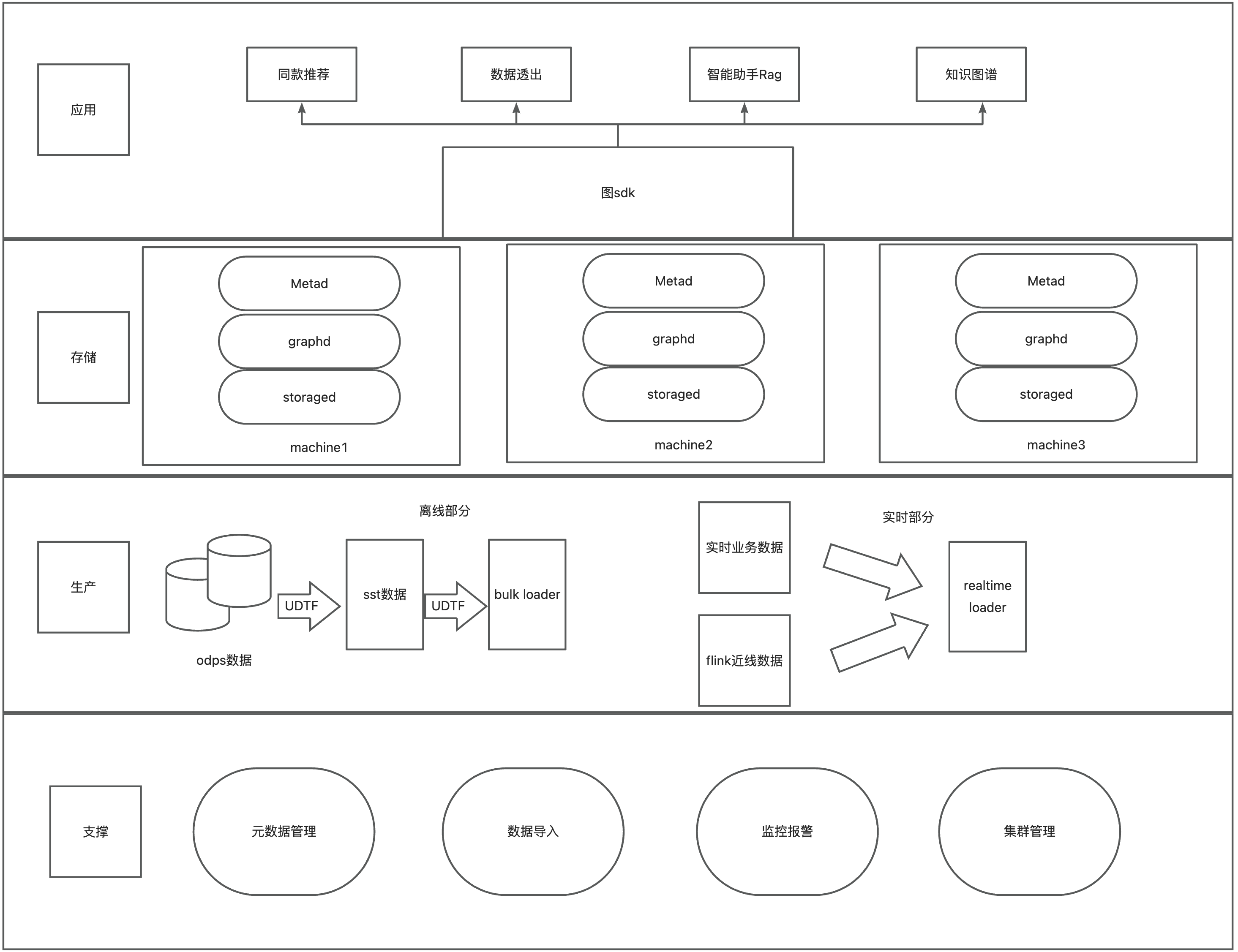
(一)整体架构
分层的职责如下:
- 应用:提供图的 SDK,业务方可以在业务服务中引入 SDK,实时地对图数据库进行业务操作。
- 存储:基于 hippo (对应 K8S ) 的高可用服务物理集群和服务系统。
- 生产:这里主要进行导入图相关数据的处理。图数据主要有两种来源,第一种是业务方把 odps 数据 etl 成转成点和边的表,然后离线导入到图数据库中;第二种是业务线上实时产生的数据、或者通过 Flink 等流式处理产生的近线数据,调用在线批量写接口实时灌到图数据库中。
- 支撑平台:提供了 元数据管理、数据导入管理、监控报警、集群管理等依赖功能。
(二)主要存储(NebulaGraph 集群如何灵活搭建)
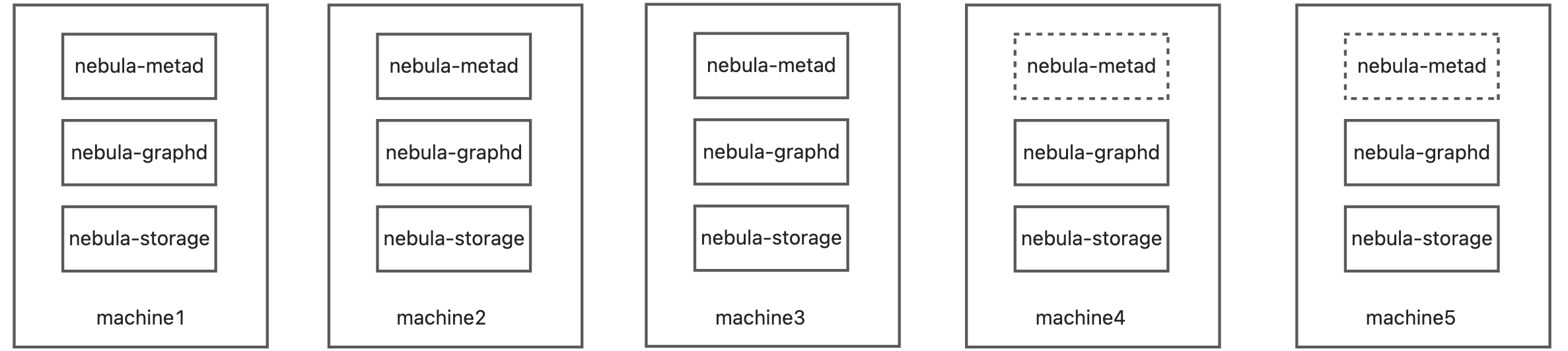
不同的业务场景下,NebulaGraph 集群需要不同的规格和部署方式,如何灵活支持?
从 NebulaGraph 官方的信息中看到,NebulaGraph 生成集群运行需要以上进程,集群的灵活性取决于集群如何灵活组织编排上面的进程?需要确定哪些机器是 nebula-metad ,哪些是 nebula-graphd? 哪些 nebula-storage? 我们的环境机器都是 hippo(docker)拉起的机器。
(三)集群管控系统
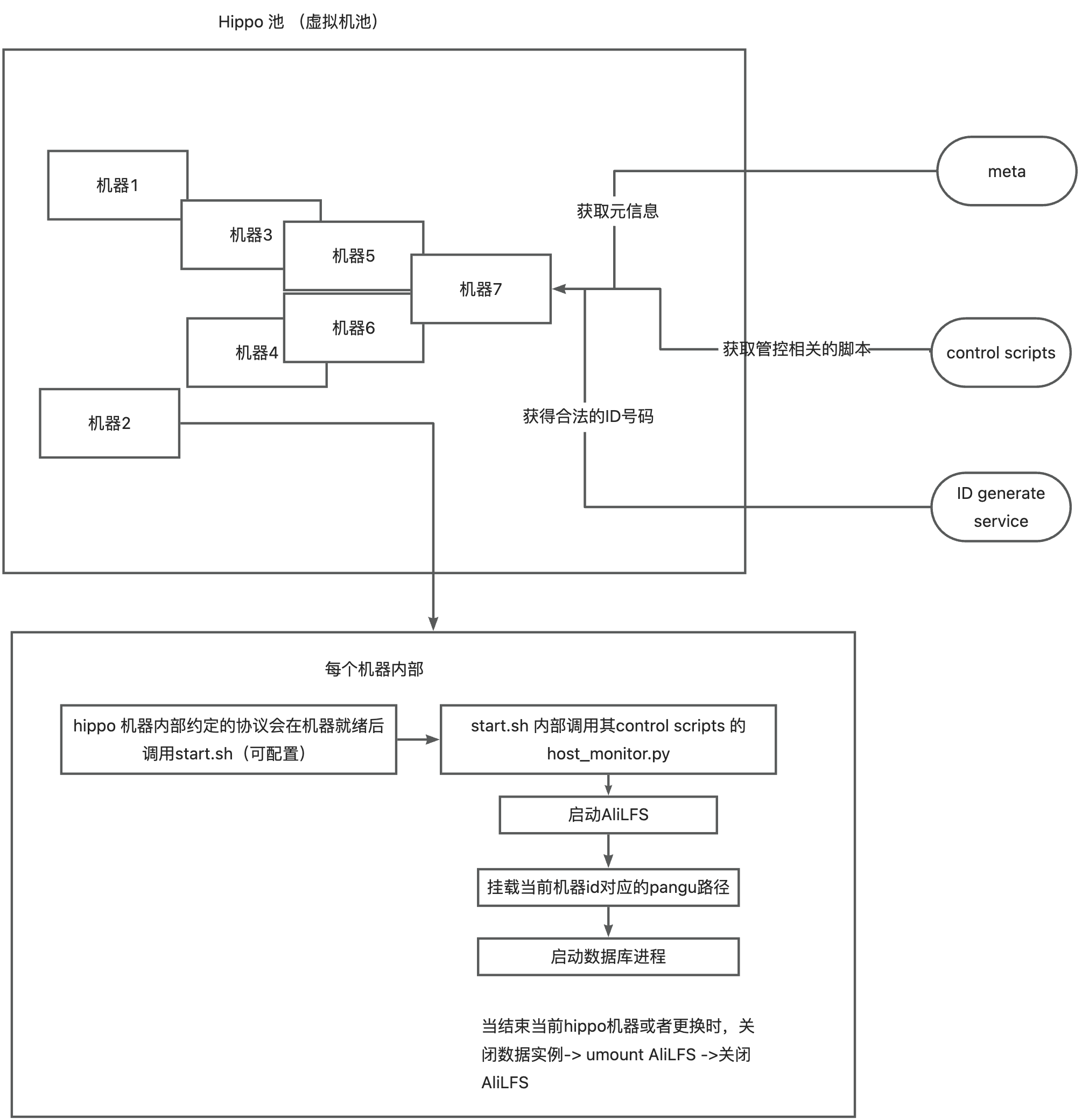
 为了解决以上问题,我们设计了一套集群管控系统。通过管控系统我们会为每个拉起的机器分配一个标识,这里使用数字 ID 标识,通过组织编排 ID 就可以灵活组建出来不同规格的机器,进而满足不同的诉求。
为了解决以上问题,我们设计了一套集群管控系统。通过管控系统我们会为每个拉起的机器分配一个标识,这里使用数字 ID 标识,通过组织编排 ID 就可以灵活组建出来不同规格的机器,进而满足不同的诉求。
(四)存储和计算节点分离
这些运行的集群都是 hippo 拉起的机器,中间调度系统都好几层。如何保存数据和恢复服务呢?
我们的架构利用中间件 ALILFS (类似开源的 JuiceFS) ,它将远端的 Pangu(阿里云存储高效的存储系统) ,以提供 Posix 接口挂载到拉起的机器上,这样已经挂载的机器可以像访问本地磁盘的方式一样访问远端的 Pangu 存储。
结合前面的集群管控系统,将每个 ID 的机器分配并绑定不同存储路径。hippo 拉起的机器即可自动加载属于自己的数据。
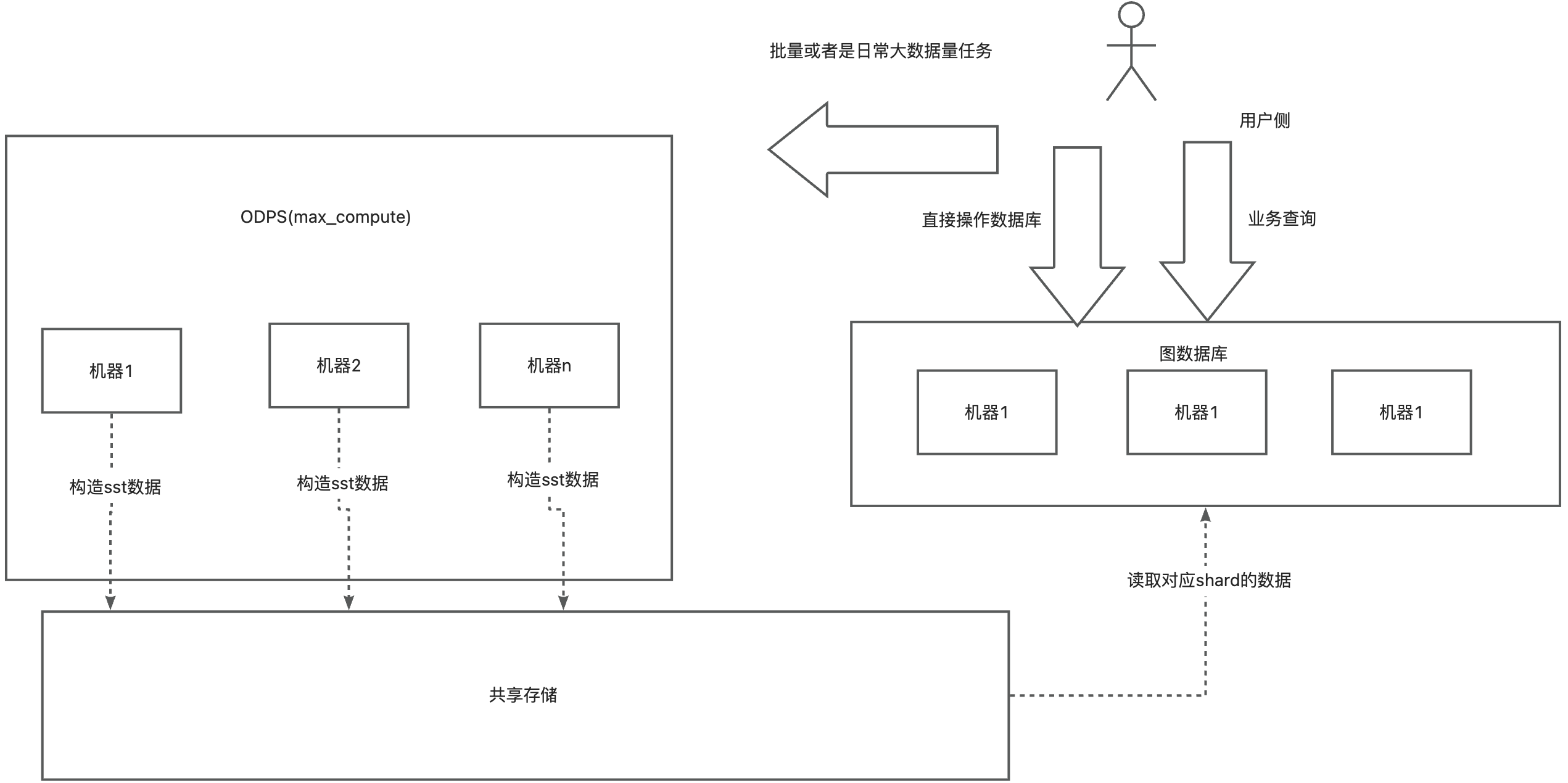
(五)生产-数据 Bulk-load 方案
我们的场景下,数据量百亿级别,需要有一套高效的数据导入方案,通过对 NebulaGraph 和 NebulaGraph Exchange 模块的研究,结合我们公司的基建设计实现了一套基于 NebulaGraph 底层存储 SST 文件的导入系统。
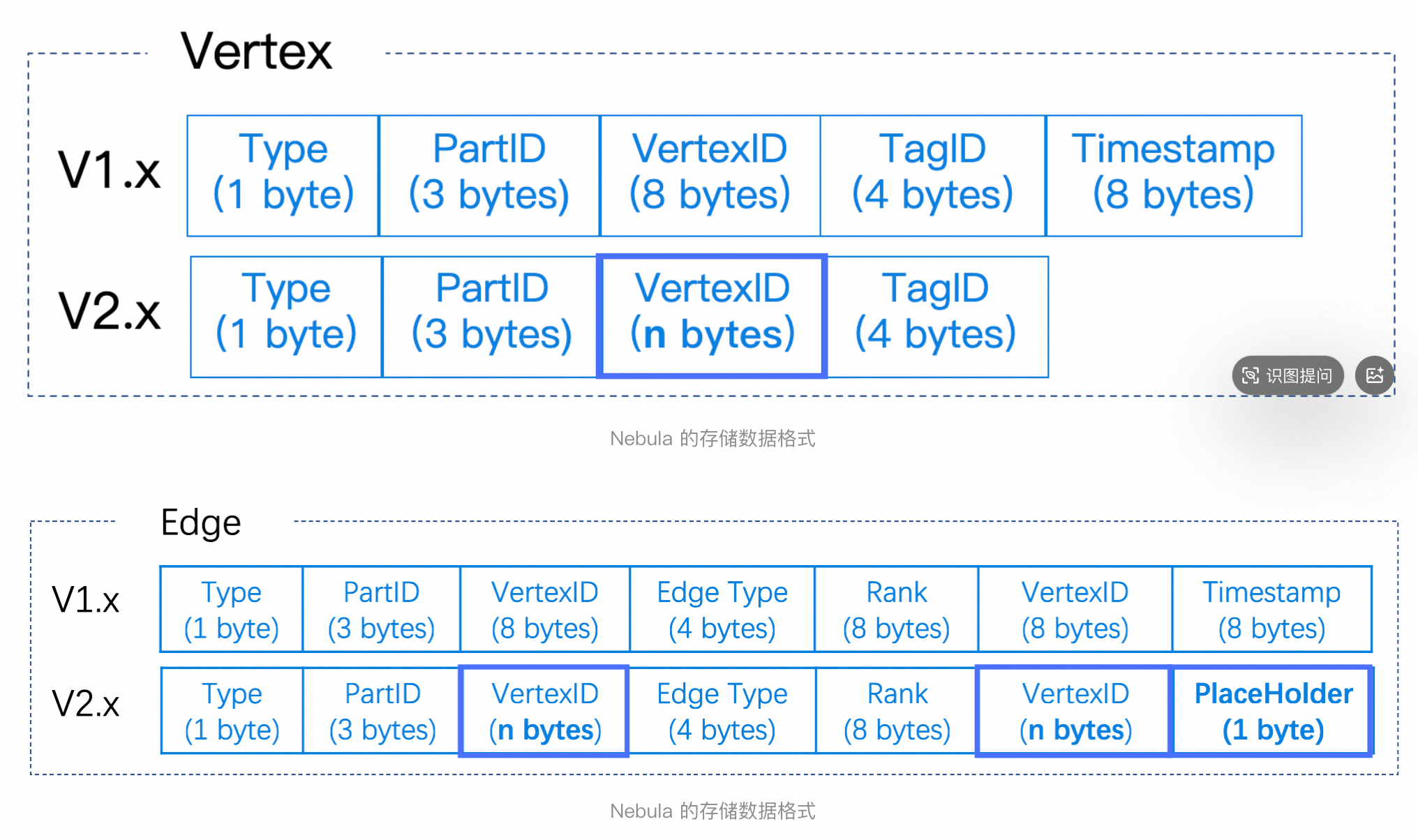
NebulaGraph 的底层数据结构使用 RocksDB 存储,数据编码格式如上,利用以上信息和对 NebulaGraph Exchange 的研究, 我们设计实现大批量数据导入方案是:利用离线 ODPS 资源构造图数据内部的二进制文件,之后利用图数据库的封装的 RocksDB 的 ingest 函数操作 load 构造的二进制文件,以实现批量大数据导入图数据库。
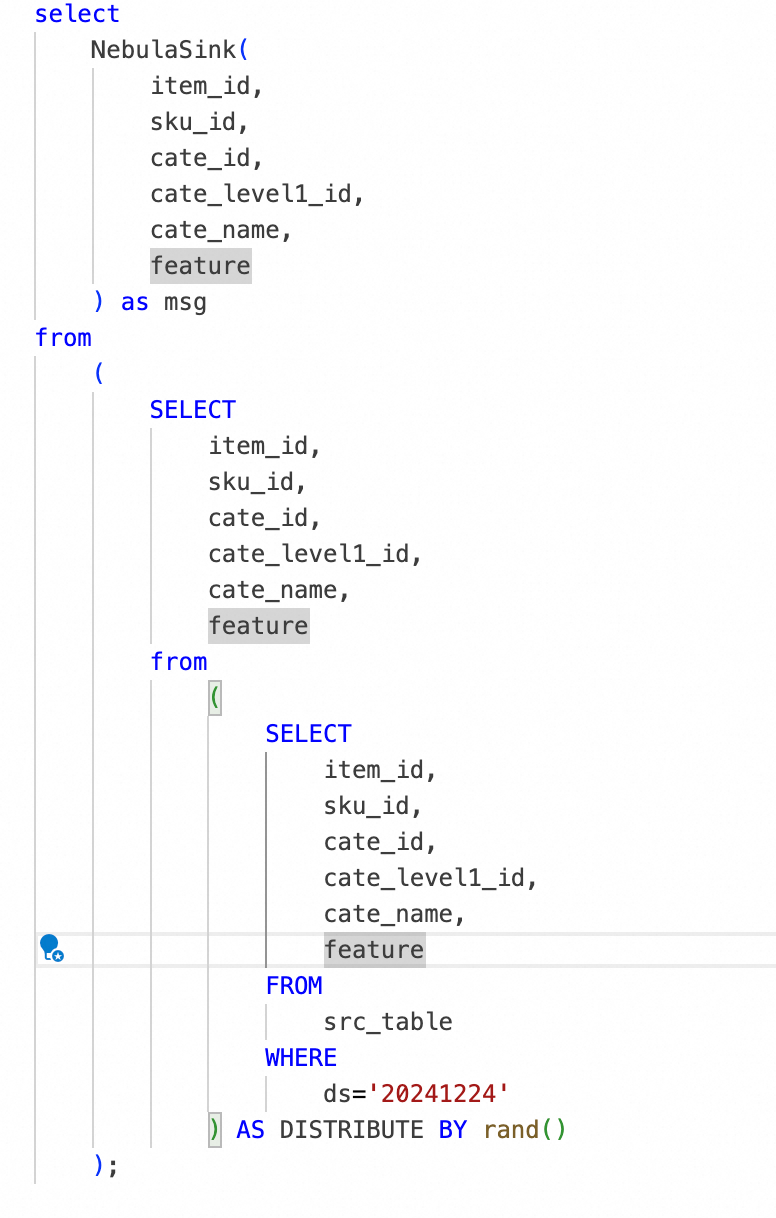
为了简化操作,我们把 SST 文件生成封装成 UDTF,执行 SQL 就会触发文件生成, 并进行元数据和导入信息的设置,并发起导数任务进入 pipeline.
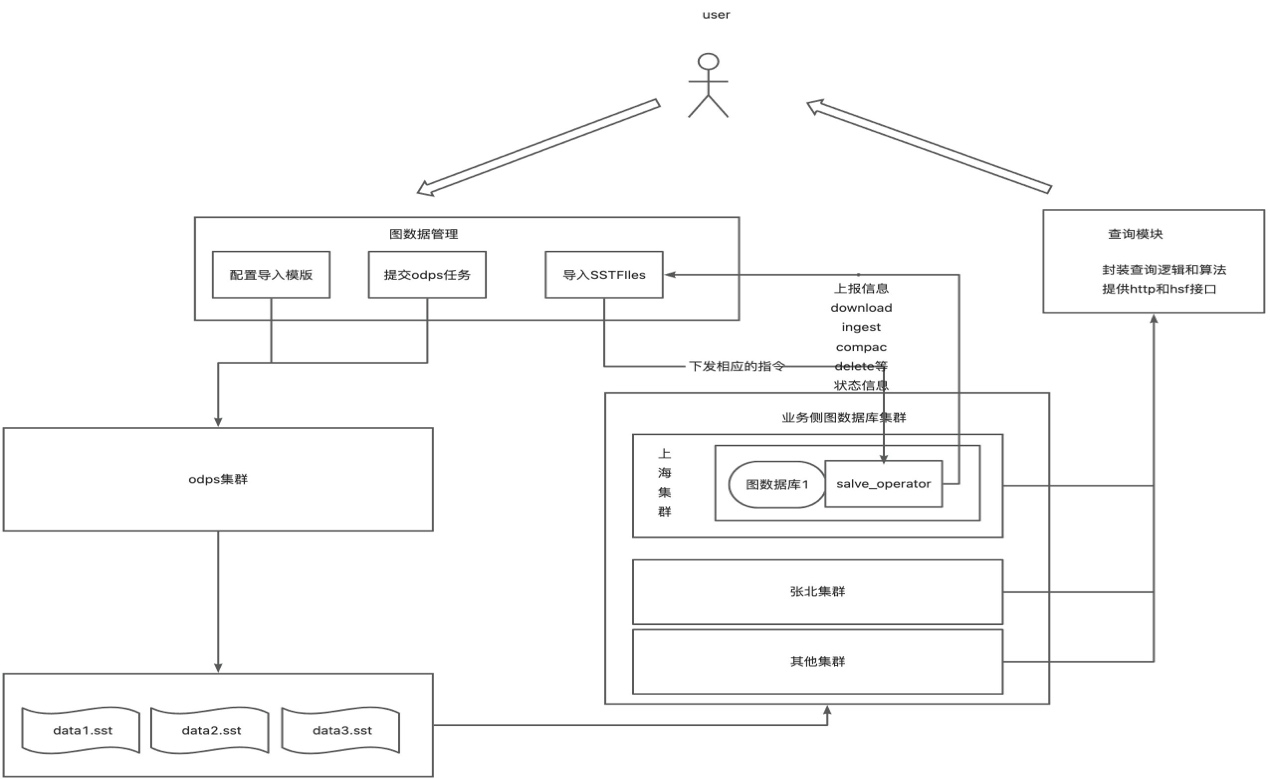
四、当前问题与解决办法
数据量巨大,导入时候,底层的 RocksDB 进行 compact,导致导入时间长尾严重,目前我们通过切分数据来减少 compact 的影响。
Bulk-load SST ingest 之后,大批量量数据导入,数据重建索引耗时和 mem 很大,通过分割数据、集群规格、配置动态调整解决。
五、未来规划
团队有对 RocksDB 和其他 KV 数据库的研究和魔改(二次开发),在未来的一些成果可以和 NebulaGraph 结合,提升服务能力,希望能以 PR 的方式贡献社区。
最后,如果您希望加入我们的团队,或者想与阿里妈妈建立合作关系,欢迎与我联系。
📮songmingtao.smt@taobao.com
交流图数据库技术?加入 Nebula 交流群请先填写下「你的 Nebula 名片」,Nebula 小助手会拉你进群~~




