
行业科普NUC2022
图行业的一些观察:以图数据库为例|NUC 2022
本文内容整理自 吴敏博士 在 NUC 2022 上的演讲,现场视频如下。 欢迎关注 NebulaGraph 官网博客专栏查看更多 资讯 / 干货 / 案例 分享。
本次分享的内容本来是图行业发展及标准的深度解读,这其实是个很大的话题,所以我把标题换成了一个小一点的标题。因为我觉得整个图行业它其实是一个非常大的行业。每个人在里面其实只是在盲人摸象,我可能只是摸过大腿而已,其他部分我也没有摸过。说不上做一个深度的解读,只是说我在这个行业的一些观察,因为我觉得我只摸过四条大腿的其中一条,所以又加一个副标题,以图数据库为例。
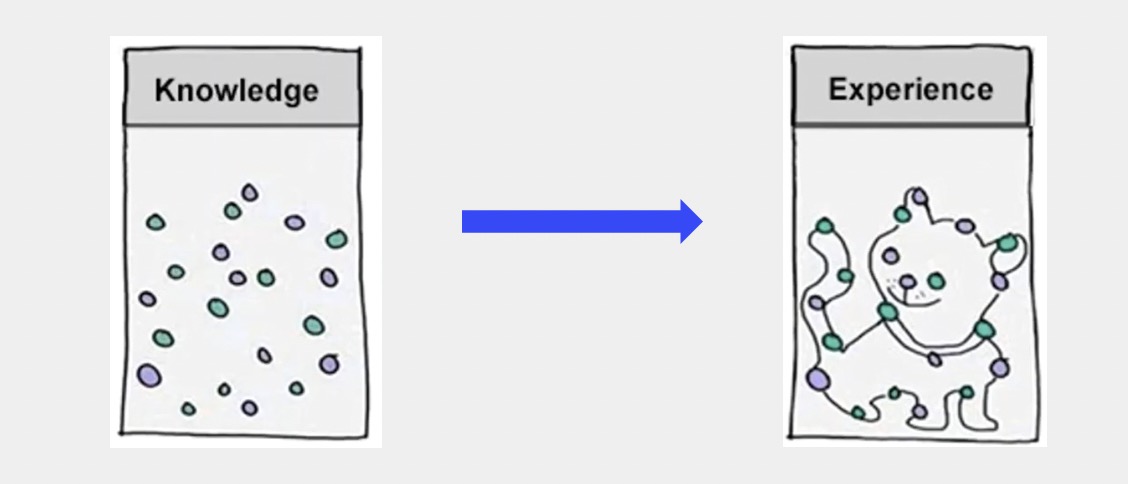
图的思想,哪怕这个术语出现的很晚,但是人类早就已经有这个概念了,或者早就已经有这个认知了。就是大家会发现其实光有这些零散的知识是不够的,需要把这些知识给关联起来,关联之后才能变成指导我们日常生活的经验。所以一个概念很早的时候就已经有了:"关联"是很重要的。
我刚才说图这个领域是非常非常的大,在 2020 年的时候,有一家公司GraphAware,他曾经尝试想把整个图领域里面的一些公司或者产品给列举一下,这其实是很难的,因为实在太多了。他大概做了一个分类,有基础设施的、应用的、开发者工具的,还有一些会议之类的。比如说在20年的时候,当时有NebulaGraph、GQL、DGL了,这些都是我们今天可以听到的。其实想把整个图完全整理出来是挺难的,我稍微做了一点点总结和浓缩。在图领域的话,大概有四个大的部分:基础设施、开发者工具、应用和信息资源。

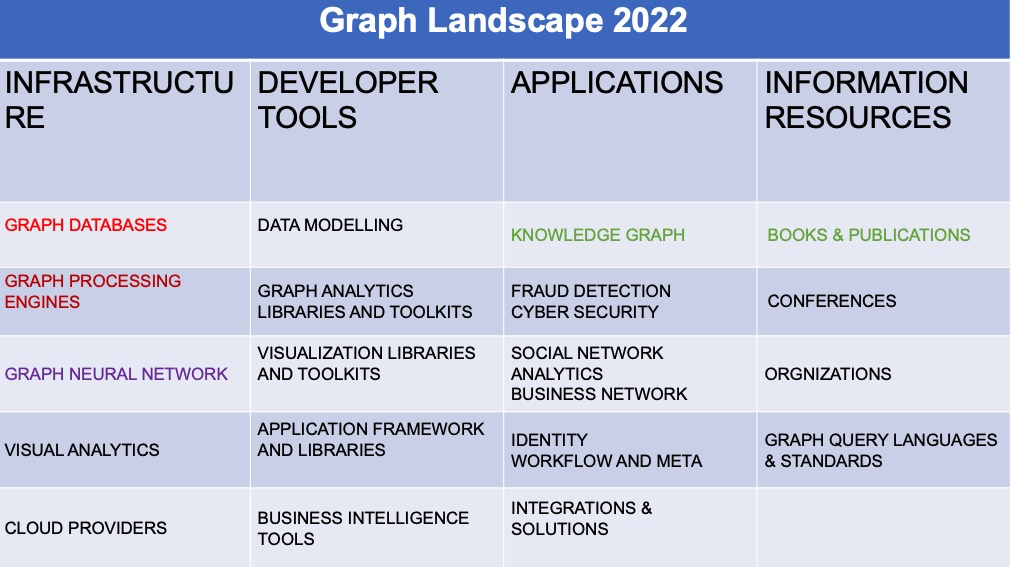
像基础设施的部分,比如说今天我们要谈的 Graph Database,还有一些可能会涉及到图 Processing 和 Computing 的系统。然后像图神经网络、可视化分析和云服务商,这些基本可以分类为整个图领域的基础设施部分,他们是基础设施的提供商。
然后接下来说开发者工具,一般主要是建模的工具,图分析和可视化的函数库、工具或者 SDK,还有一些 BI 场景的工具。当然还有其他的一些开发者工具,就不一一列举了。
还有应用领域,比如说图谱。图谱本身是一个很大的领域,图只是为图谱提供一些基础设施的服务。还有一些常见的,比如说欺诈检测、网络安全,或者是社交网络、商业网络的图。这些是图比较常见的一些应用领域。
还有一些是图领域的信息资源。比如会议、书籍、论文。九月份的时候,VLDB 的 Research Session,大概有 1/5 都是和图相关的;还有今天我们的 NUC,这也是图领域的一个会议。还有一些国际化的组织,比如说像国际化的 ISO、IEC,他们在为国际标准做一些努力。还有一些民间的组织或者第三方的组织,比如说 LDBC,可以为这个领域的发展做一些贡献。这些挺好地反映了图行业现在的成熟程度。
图这个话题还是挺大的,所以先看一点简单的历史。可能大家都听说过七桥问题,或者是西尔威斯特提出的矩阵和图论这两个名词,这都是历史上的概念,不是我们计算机学科要谈的。
一、“图”的一些历史
1960-1980s: 数据模型与数据系统的定义
计算机系统里面的图,有这么一个历史,在 60-80 年代的时候,其实大家的主要工作都是着重在图模型和数据系统该怎么定义上面。最早我能查到的是巴赫曼,1960 年的时候,当时他在 GE 的开关电器厂工作,发明了 IDS 系统。这个系统对后世所有的数据管理系统都有很大的影响。巴赫曼应该是最早的先驱,当时他所采用的模型后面被称为称为 Network Model 或者 Network Data Model。它本身的特点是把记录 record 通过Linkage 关联起来。比如上面这个例子,一个记录可以和很多其他的记录相互关联。这应该是在计算机系统里面最早实现的一个图模型系统。当然后来巴赫曼获得了图灵奖。


60年代的时候,大家重点工作是放在图或者网络模型上面。到70年代的时候,最著名的成果就是科德发明的关系模型了。从关系模型到关系代数,一路演变成了RDBMS的这一整套技术。科德在70年代发明的关系模型相比60年代的网络模型,他认为自己的进步在哪里:就是60年代的网络模型,或者说那个时候的图系统,只能够处理一系列确定主键的记录之间的关联;而他所发明的这个Relational Model,他可以对任意的值进行匹配。如果用数据库的话,就是value-based join。这样整个模型会更加地通用。因此在后来很长的一段时间,可能有三四十年的历史里面,RDBMS基本上主导了整个数据处理市场。
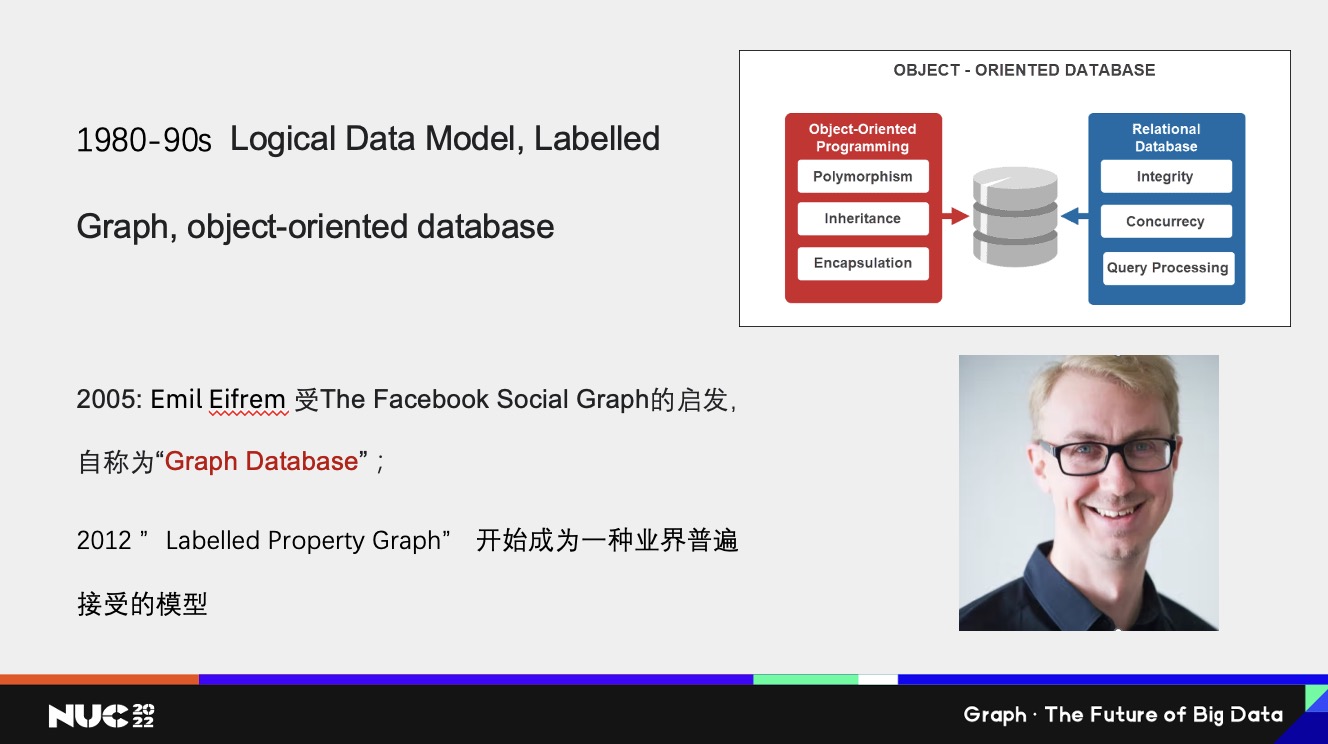
整个图相关的模型还在继续往前走,比如说到 80-90 年代的时候,有了Logical Data Model。再比如说标签图或者标签网络,这也是现在我们常用的 LPG(labelled property graph)概念中的一部分。因为 90 年代的时候面向对象很流行,也有人尝试想把面向对象的这个概念引入到数据库系统里面,比如说数据库原来已经有这些ACID的功能,尝试想把这种多态、继承或者封装功能引入到数据库系统里面。当然,其实多态或者继承本身也是带一定的图关系的,当然今天看有些探索并不是成功,但也是往前的一些进步。
大约在05年的时候,后来的 Neo4j 首席执行官 Emil Eifrem 听说在哈佛有个软件挺流行的,叫 The Facebook Social Graph,然后他觉得自己正在做的一个媒体管理软件也是一个 Graph 结构。他当时在飞机上,突然就灵光一闪,自创了一个新的名词 Graph Database。这应该是我能查到的这个单词(Graph Database)最早的起源了,后来这个名词也是过了很久才慢慢为大家所知。
到12年的时候工业界大部分采用的是 Labelled Property Graph模型。相比基本的网络模型做了一些扩充,比如说 label 加上了,把 property 加上了,这个概念到今天为止也是在图数据库这个领域里面比较常见的模型之一。另外一个比较常见的模型就是 W3C 为 RDF 所做的这一套定义。这两种模型到目前为止还是比较常见的。
整个数据模型还在继续向前进步,大约到18年左右的时候,尝试为图或者网络的模型添加 streaming 或者 temporal 的时序能力。相关工作还在继续开展,也有一些论文再发布,能看到一些相关产品。
2010s: 图数据库与图计算系统的相互促进
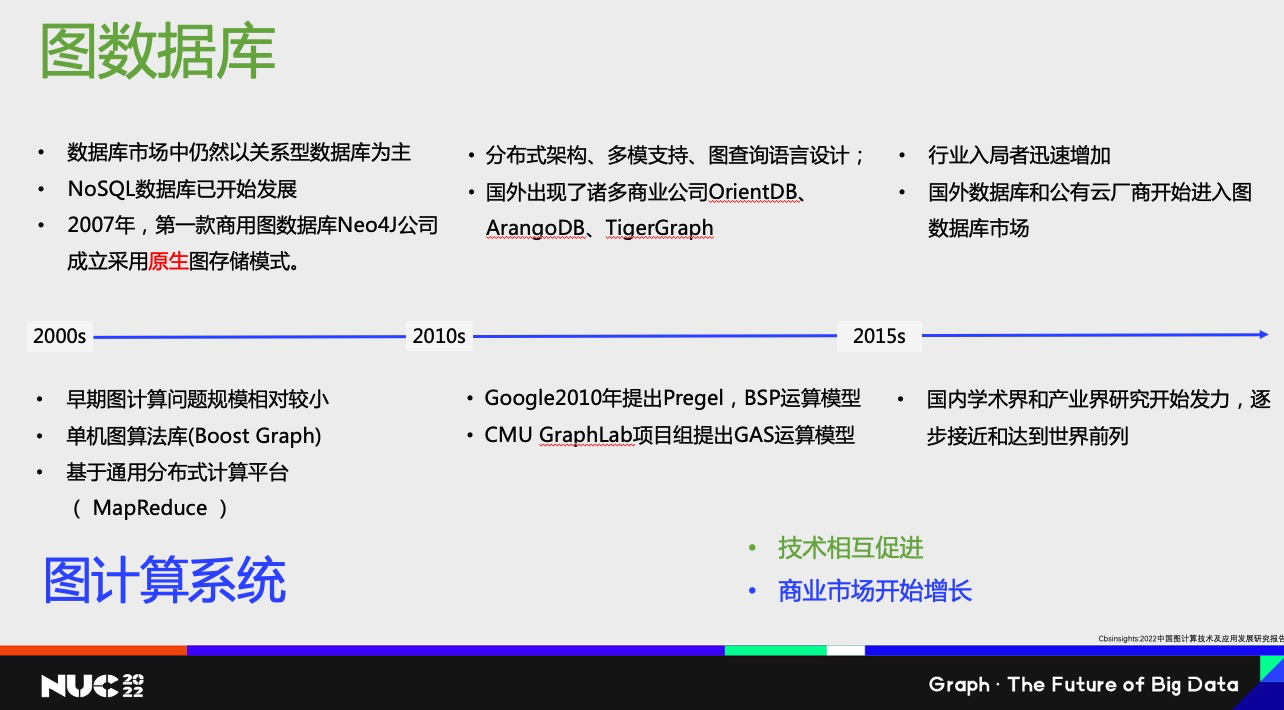
刚才提到的这些模型,可能是很久之前的历史了。大约在2010年前后开始,在图这个模型里面,出现了两个比较重要的分支,图数据库系统和图计算系统。这两个分支先是独立发展,之后是相互促进。虽然数据模型是一步步演进过来的,但是图数据库和图计算系统两种系统最初是各自独立发展的。
图数据库系统基本上和数据库系统的关系会更大一点。在 2000 年到2010 年之间,图数据库系统基本上还是 NoSQL 系统中的一种尝试。他们面对的还是想解决 RDBMS 中有些不好解决的一些小的细分领域问题。
而图计算系统,它当时能解决的都是一些小规模的图。比如单机处理一个图计算的场景,或者是使用 Boost 里面的 Graph Library,或者MapReduce 来非常原始的方式来实现图计算。
从大概10年开始,两种系统都得到比较大的发展。图数据库对于分布式架构、多模支持和图查询语言设计这些方面都开始进入技术成熟阶段,也出现了很多新的商业公司开始进入这个领域。对于图计算系统来说,出现了两个比较重要的计算模型,BSP 模型和 GAS 模型,这两个模型使得大规模并行地分布式图计算变得可能。当然也产生了一系列图计算和分析为主要目的商业公司。
这两种系统在 15 年前后,技术开始相互促进和融合。商业公司会相互借鉴对方的技术,把对方技术引入自己的产品里,然后去服务更多的场景。在 15 年前后行业的入局者开始迅速地增加。不光光是国外,国内也出现了更多的公司。原有的数据库公司和云厂商也开始进入这个领域。国内的学术机构和产业界也有比较明显的进步。已经可以逐步接近和达到世界的前列。所以对 15 年之后的总结就是技术上相互促进,商业市场已经开始增长。
2018- Graph + AI 的快速兴起
然后在 18 年前后,在技术上又发生了一些变化。Graph+AI 的领域开始快速兴起,这里的 AI 比如说像连结主义为主的神经网络,或者是符号主义为主的 Knowledge Graph。
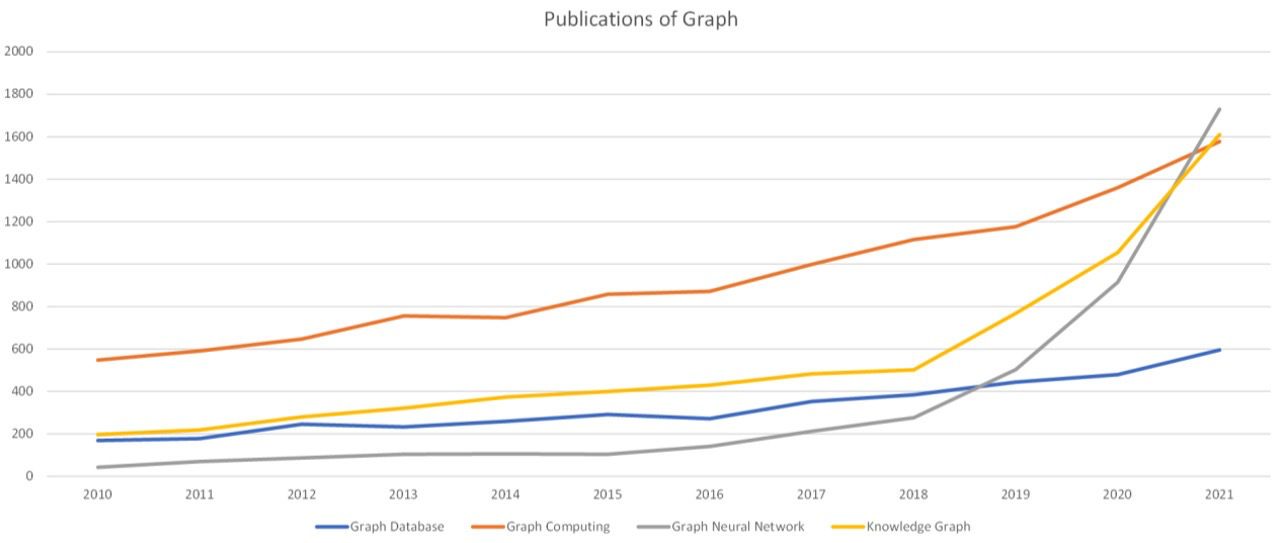
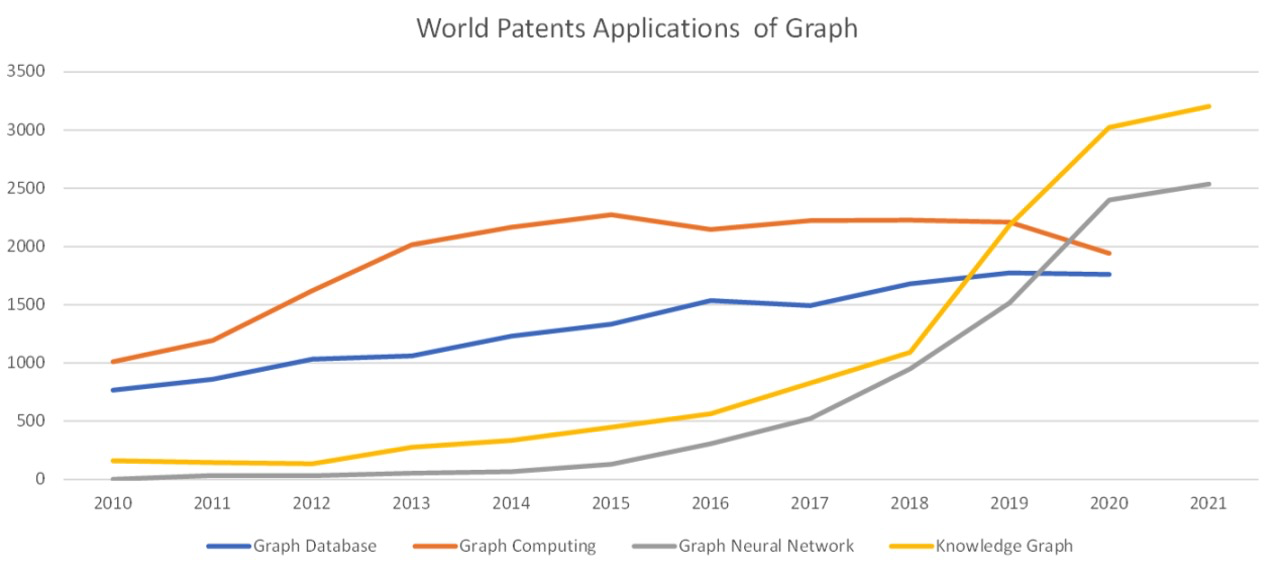
Graph和AI的结合使得这个领域出现了很多新的研究。有几个例子,一个是我从Web of Science拉了一下论文的情况。大约从10年到15年左右,Graph Database、Graph Computing、Graph Neural Network和Knowledge Graph总体来说都保持了一个相对平稳的增长,但是到18年左右,和 AI 相关的 Graph 的论文数量就发生了明显的提升,这说明了学术界研究热点的变化。还有一个是专利的情况,这是我从 WIPO 拉取的和 Graph 相关的专利申请情况。在前期的时候,Graph Database 和Graph Computing 的专利申请会明显多一些。然后到18年左右开始的时候,和AI相关的Graph Neural Network和Knowledge Graph专利申请有明显的提升,这说明了工业界的变化。一般来说,工业界会更关注专利一些,学术界会更关注论文一些。可以说Graph+AI在最近这几年都得到极大的发展,不管是在学术界还是工业界。
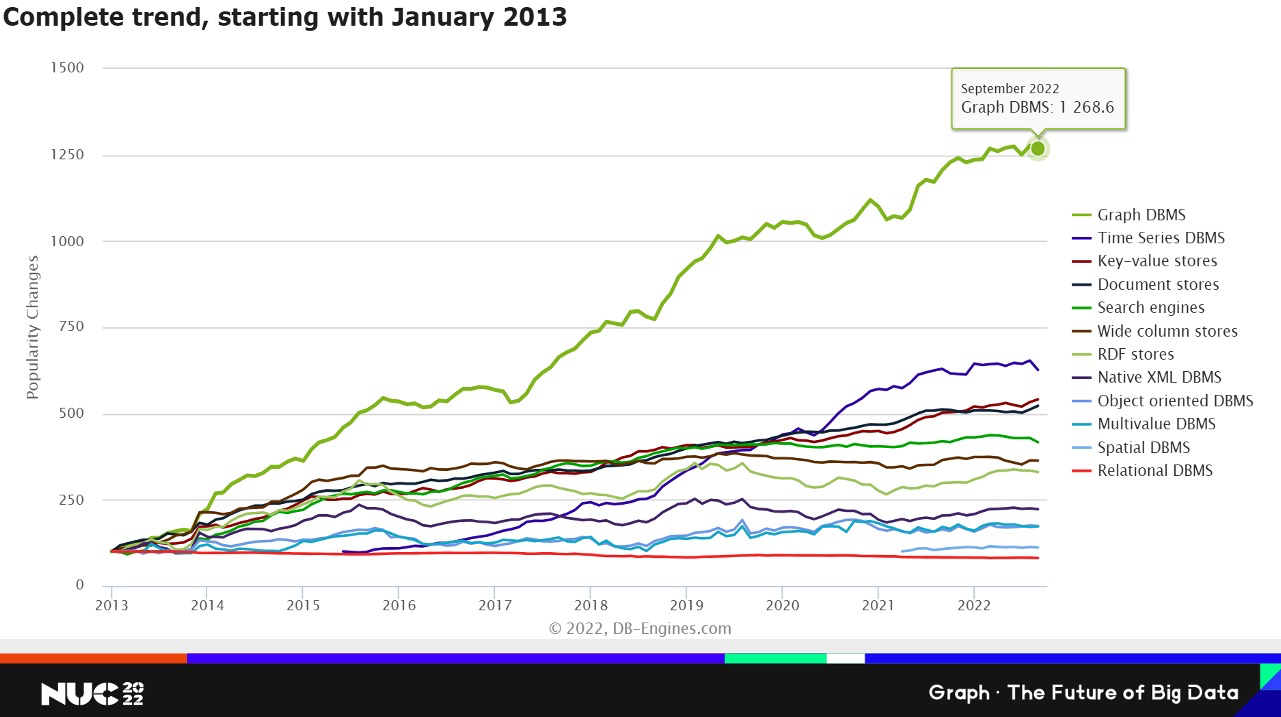
因为我们想谈的是 Graph Database,所以从 Database 领域来简单看一下。在 Database 领域有很多的分支,DB-engines 网站会对不同的分支品类统计流行情况,反应流行度的增长趋势。比如说 Relational DBMS(下面这个红色的曲线),他的基数已经很大,增长趋势不会很大。但是对于 Graph DBMS 来说,这么多年以来,都是增速最快的分支。所以从Database这个角度来看,Graph 领域也是增速最快的。
2013-2022:Hyper Cycle of Graph Databases
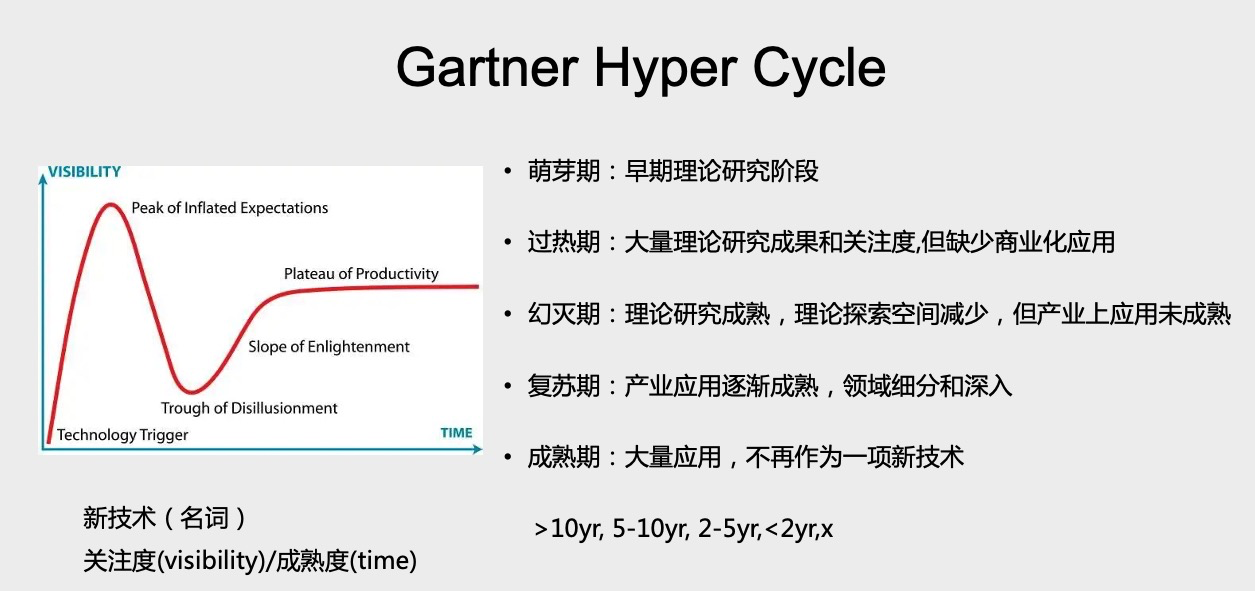
然后我还去找了一些研报或者三方研究机构对这个领域的一些看法。其中最著名的就是Gartner。Gartner从13年开始,每年都会去研究Graph这种领域的进展。它有一个非常著名的 Gartner Hyper Cycle 曲线。简单说一下,Gartner 认为一个技术会有两个 Cycle。第一个 Cycle 是从萌芽期进入过热期再进入幻灭期,这期间会有大量的智力和资本进入这个领域。然后第二个 Cycle 是从复苏期进入成熟期,这个技术成为整个商业日常运营的一部分,不再作为一个新的技术名词出现。
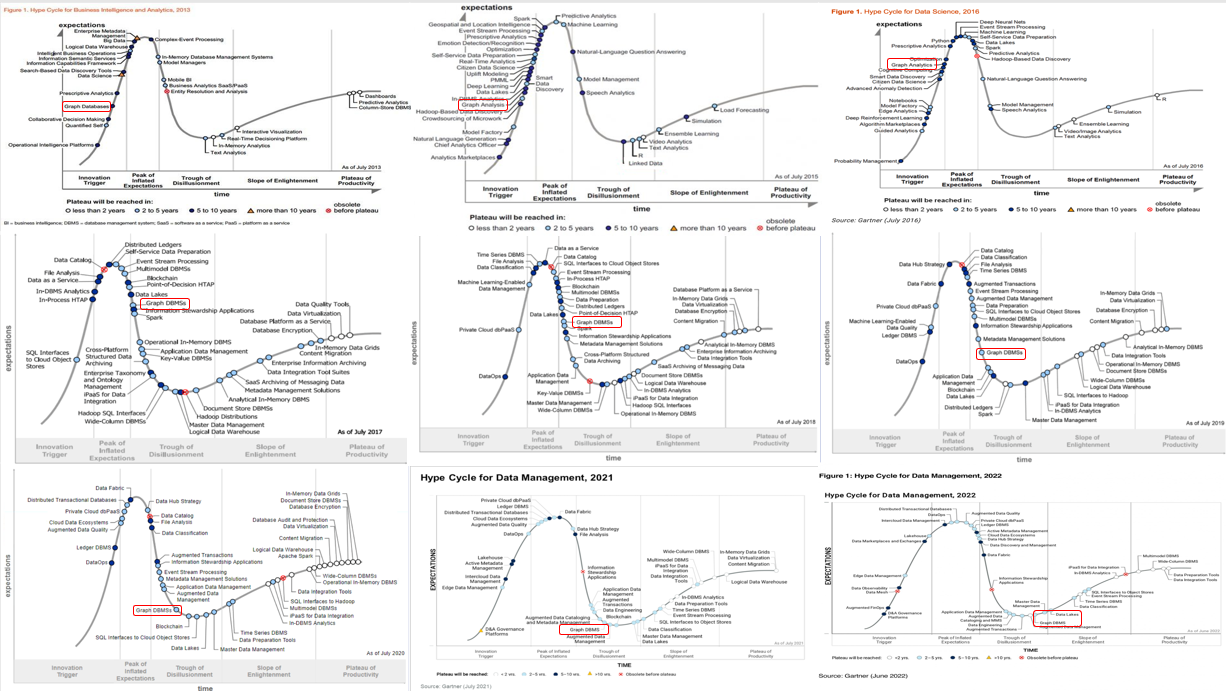
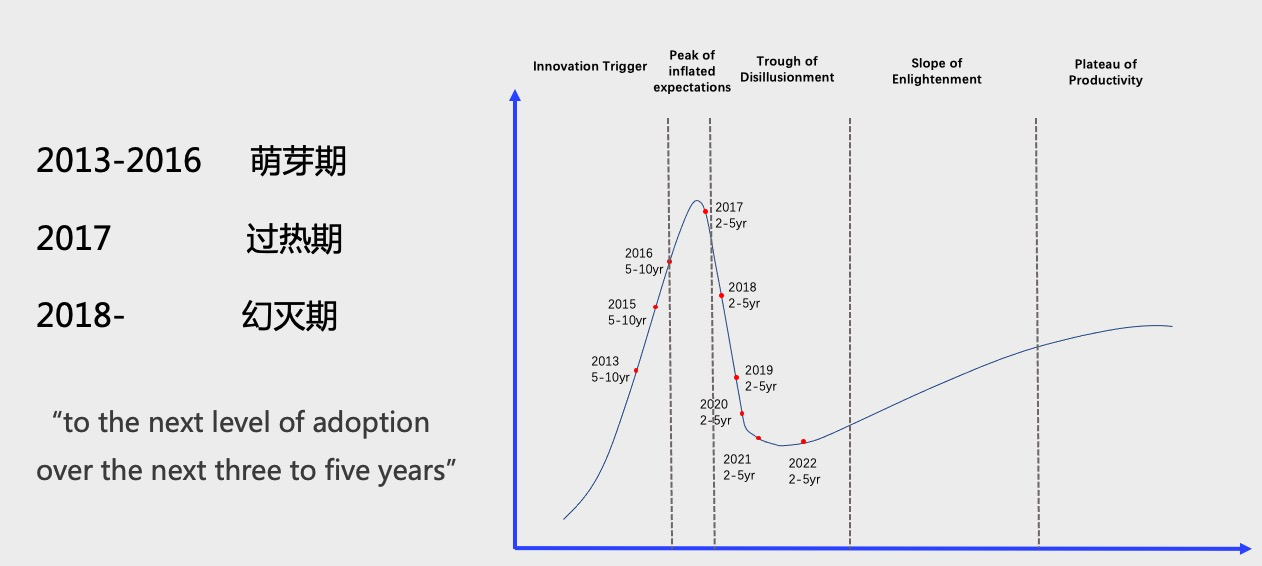
Gartner 对于 Graph DBMS 从 2013 年开始一直有跟踪,我把它稍微重新整理了一下。在Gartner看来,整个Graph领域的情况是这样子的。大约从13年到16年,这是第一个Hyper Cycle的萌芽期,大家在尝试探索说哪些领域或者哪些新的技术可以被引入和使用。在17年左右的时候,这是第一个 Cycle 的高峰,之后的三年时间,进入第一个Cycle的幻灭期。从21年到22年开始进入第二个Cycle的爬升期。根据Gartner的预测,他认为在未来的3-5年内,Graph Database 这个领域会进入一个技术的成熟期。
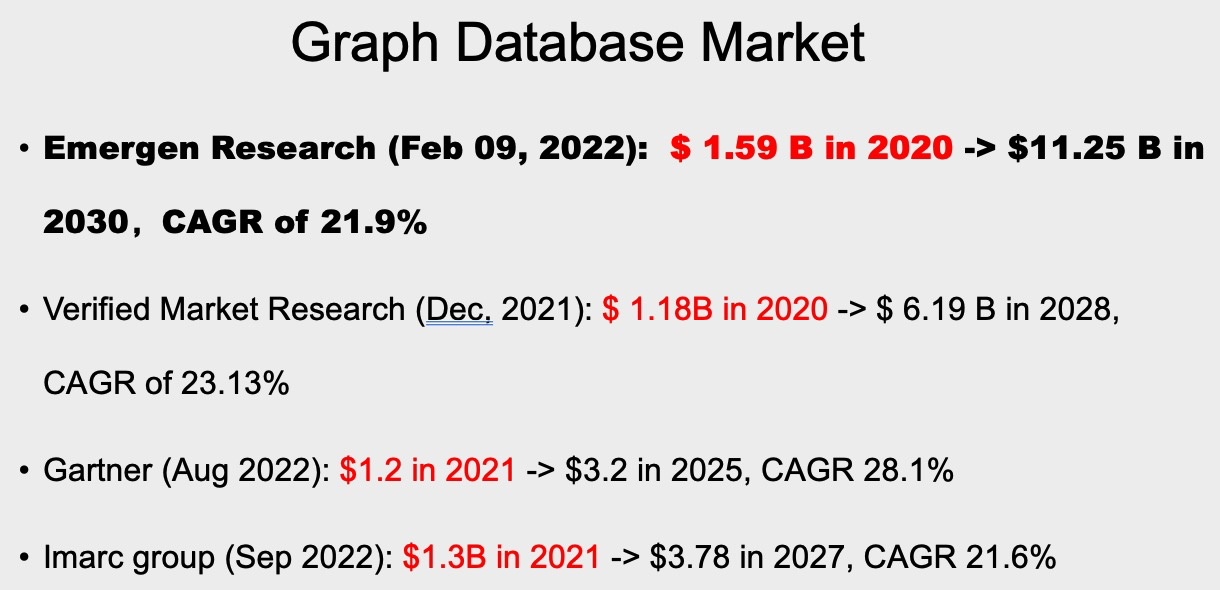
对于整个 Graph Database 的市场营收情况的一些预计,不同的研究机构给出的研报可能不太一样。但是大体上数据都是最近20 21这两年有十几亿美元的营收,并且大约保持 20%+ 的年复合增长率。这个增速大概我看了一下,略高于一点点 RDBMS 市场的增速。当然这是一个全球的情况,那如果看国内的情况,独立的研报比较少,但从我们内部拿到的数据和几家证券公司给的研报来看,国内的数据应该比国际数据的增速至少高一倍以上,内部能看到数据都是 50%~100%。所以国内会更乐观一些,大概可能的原因还是国内相对基数更小,导入和起步也更晚一点。
二、对于图数据库未来的猜想

最后一个部分是对未来做一些预测,当然预测还是很难的,所以我把它改一个名词,叫做猜想。猜想分为三个部分,一个技术部分,一个产品部分,还有一个产业部分。
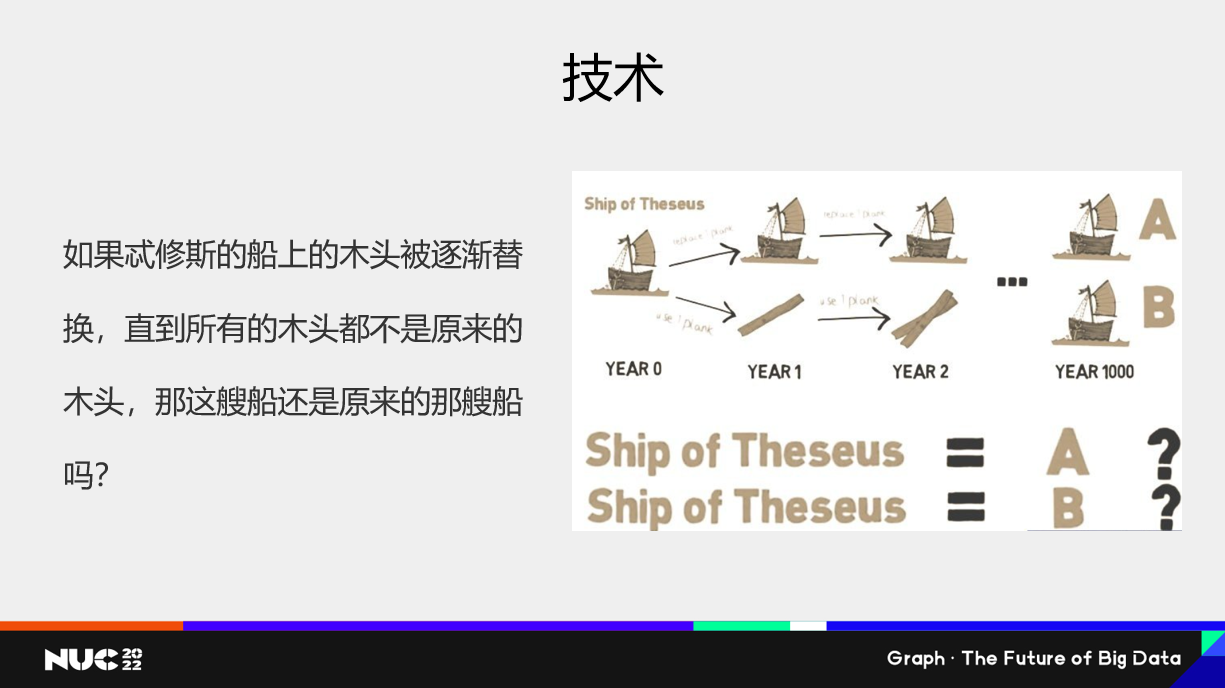
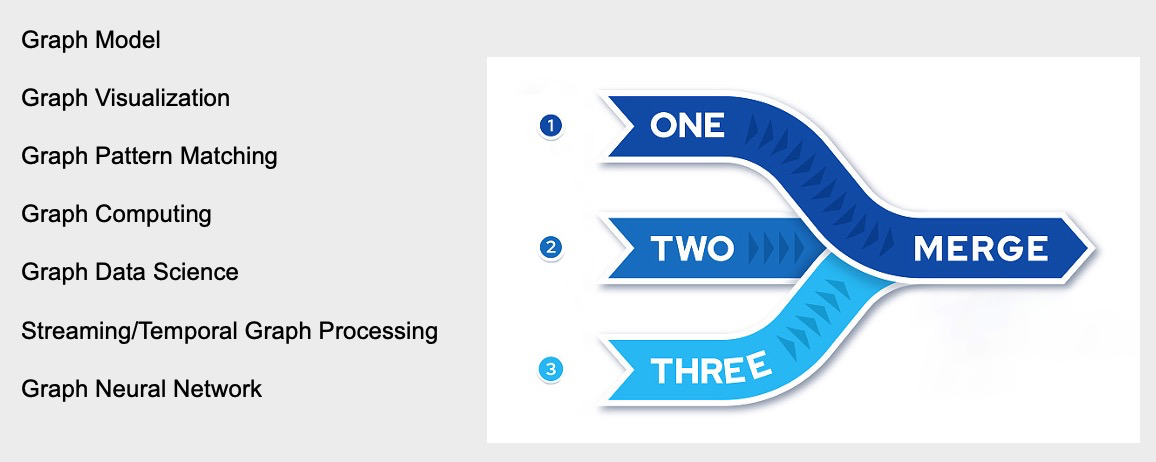
关于技术部分,Graph Database 这个名词本身其实已经出现快20年了。然后我想引用一个隐喻:一艘船它的木头逐渐被全部替代了之后,木头还是不是原来的木头,船还是不是原来的船?我想说就是 Graph Database从最初只是一个Graph Model 外加 Graph Visualization 的一个数据存储系统,到后面逐步增加图语言 Pattern Matching 能力、大规模的 Computing 能力,以及对于业务人员用的 Data Science 能力,加上时序、Neural Network 这些能力。是不是可以考虑为它创造一个新的技术名词了。
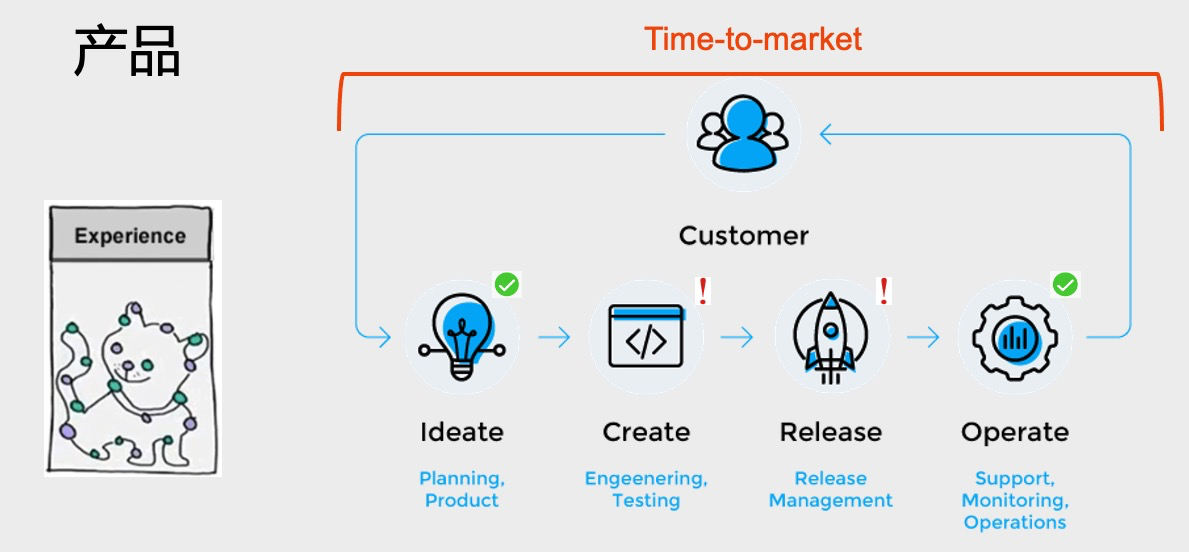
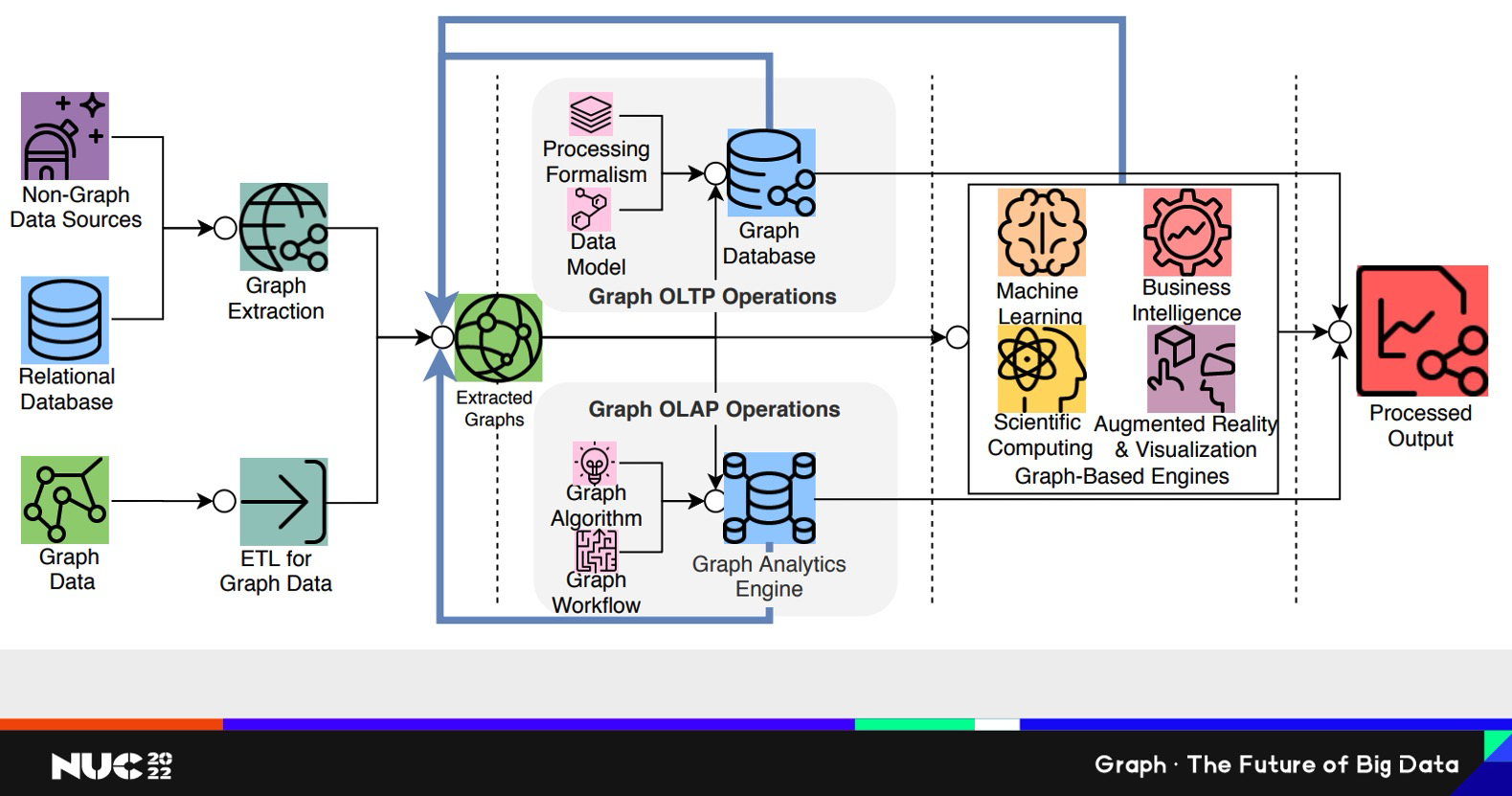
第二个是产品部分。关于Graph领域我觉得有一些问题。最前面说到要把知识串联起来才能变成经验。对于任何一个技术来说,都有这么一个Time to Market的过程。先有一个想法idea,然后要试一试这个想法行不行。如果这个想法行,再把它变成一个生产的部署,最后再进行运维;如果不行,我可以再返回再来一个循环。这整个过程Time-to-market其实速度是最重要的。其实Graph领域来说,它在idea这个阶段是最适合的,因为即使业务人员不懂技术,对他来说也是很容易理解的,所以可以非常快的产生一个新想法。但是Graph领域目前的问题是在Create到 Release这个阶段速度太慢。具体来说为什么速度太慢,就是整个Graph领域的技术对于用户暴露的细节还是太多。不管是从OLTP的这个角度(上面),比如整个数据流的流程很长,加工完数据(ETL)要反馈到前面。对于OLAP这种分析为目的流程,也一样有个抄长的流程。在这样的整个流程里面,任何一个环节即使技术上极大进步,进步1倍或者10倍,但对于整个流程,特别是对于整个Time to Market的流程,其实可能只提升了5%。
另外一个问题是人员,因为如果对于一些小型的公司来说,他需要有数据科学家,要有DBA,要有业务人员,对他们来说可能人力成本就太大。每个人那么多细节要学习,对于公司决策者来说就很不经济。这两个阶段的劣势就抵消了Idea这个阶段的优势。
所以我的期望是说会有一些集成度更好的、对用户更友好的产品。不管这些商业分析的用户,他想用哪种数据模型、想要哪些算法,产品可以更好的提取出来,把这些复杂度包装在后面,减轻用户的心智负担,让用户更快地去发现他所需要的商业价值,而不是把大量的精力都花在搭建一套甚至几套很复杂的图系统上面——这种事情只有大厂或者大型项目才做得到。技术目的应该是发现商业的价值。而这样一个复杂的流程降低了整个图技术在全市场普及的门槛。

然后是关于标准化部分。标准化其实和整个行业是有些重大影响的,比如ISO-GQL其实是一个很好的事,因为这对于所有的行业的使用者来说,它可以不再去学习每一个不同的vendor所提供的语言,当然是一件非常好的事。当然图领域不只是一个语言,其实图领域有很多的算法,除了大家常见的那几个图算法之外,还有大量的长尾的图算法。而那些图算法,每个vendor给的接口、给的数据导入的方式,它的工作流都是千奇百怪的。对于整个领域的开发者来说,他必须得为这些 vendor 去适配自己的系统,这也是一个很大的成本。还有就是关于整个行业的 Benchmark 的情况,这对于甲方或者应用来说是有意义的。但现在整个行业的 Benchmark 还是非常的少,只能体现产品在非常少的几个场景下(比如社交、金融个别场景)的读或者写能力是个什么样子。这对于甲方的决策来说还是不够的,因为甲方需要有更贴近于他的业务场景的一些 Benchmark 供他参考。否则对于他来说,每个项目只能拉着 vendor 来一起设计 POC,对整个采购流程也有很大的阻碍,这里面就有很多商业运作的空间。所以我对于标准化的期望,就是能够有更多的工作能够使得整个行业的范式发生一个迁移。

最后一个部分是关于产业的,特别是关于中美市场。大家可以看到中美市场在第一个 Cycle 的时候,因为受益于理论部分的工作,两个市场对于技术的接受程度比较一致。但在第二个 Cycle,就是技术成熟商业化阶段,中美市场是不太一样的。因为两个市场的政治冲突,产业结构、市场化程度等等的差异性,会导致在第二个 Cycle 的时候,中美在整个图领域会走上分叉,可能会走上导致不同的技术和商业化的可能性,而且目前看技术与商业都分叉的趋势还是挺明显的。

这个世界充满不确定,最初开篇说到这里只是对于图这个行业的一个小小的观察和认识,所以希望上面这些内容能为大家提供更多的确定性,当然也有可能为大家提供了更多的不确定性。
NUC 2022 往期精彩内容回顾:
交流图数据库技术?加入 Nebula 交流群请先填写下你的 Nebula 名片,Nebula 小助手会拉你进群~~




