
技术分享
使用 nebula-spark-connector 3.6 版本搭建备集群实践
看过我之前文章的读者可能知道我之前用 nebula-br 搭建过主备集群,具体实践过程不做赘述,有兴趣的小伙伴可以看下这个链接:nebula-br local-store 模式搭建主备集群实践 🔗
那么问题来了,为什么在已有 nebula-br 搭建集群的情况下,我又造了个“新轮子”,让 spark-connector 走上 nebula-br 的老路呢?在这里我来讲讲二者的优劣势:
!注意 文章内容仅代表个人观点,仅供参考。
主备集群搭建的选择
先从目前个人已知的可搭建备集群的开箱即用工具讲起,NebulaGraph 社区的相关搭建工具有:
- nebula-br
- nebula-spark-connector
- nebula-flink-connector
由于 nebula-flink-connector 和 nebula-spark-connector 实践原理较为相似,本文就不单独地讲述 nebula-flink-connector 如何搭建主备集群。
搭建备集群实践
nebula-br 主备集群是通过本地生成 snapshot 备份,然后传输到备集群进行恢复的方式。
优点:
- 搭建速度快;
缺点:
- 生成备份文件的时候会导致 Nebula 不可写,影响在线业务;
- 环境搭建麻烦,需要在主备集群上运行 Agent 和 BR,此外恢复时需要读取备份文件,这些文件要么通过 S3 或者 NTFS 共享,要么就手动拷贝;
- 从源集群备份还原到目标集群,目标集群将会被覆盖(也就是跟源集群保持一致,可以理解为目标集群将会被清空,然后还原源集群数据到目标集群)。
spark-connector 搭建集群的优劣势
nebula-spark-connector 主备集群是通过 nebula-client 去 scan nebula 的数据,然后生成 INSERT 语句在备集群进行重放。
优点:
- 开箱即用,针对小数据集群(低于 1 亿)基本上不需要任何开发直接使用;大数据集群(大于 1 亿)可能需要额外流量控制逻辑;
- 同步时对源集群的读写影响较小(前提是需要控制导出并发控制);
- 同步粒度更精细,可以指定同步 Space、Tag、Edge;
缺点:
- 导出导入的方式同步数据比较慢。就速度这点和官方交流了下,官方表示之前在某家公司业务上实测过速度,nebula-spark-connector 做同步是要比 nebula-br 快 3-5 倍。可能环境和参数有差异,如果读者你选择工具的时候,可以先测试下相关工具的性能数据。
- 需要 Spark 环境支持;
- 无法中断重启时接着上次 cursor 继续 scan;
这里稍微说下 nebula-flink-connector,个人感觉它跟 nebula-spark-connector 最大的区别在于 Spark 需要读完整个分区才会做 Write 操作,nebula-flink-connector 可以做到边读边写,理论上效率会高一点。
nebula-spark-connector 原理
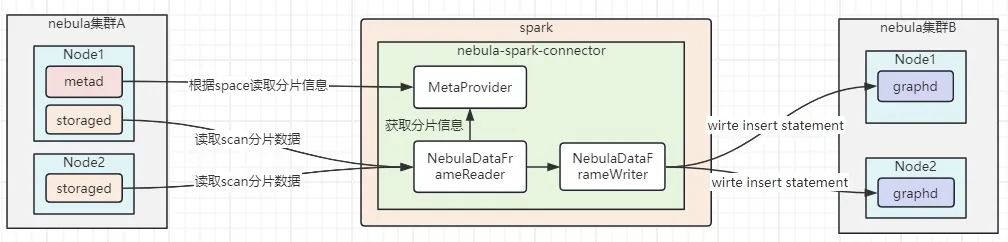
本图有任何理解错误的地方,麻烦在留言帮忙指出,感谢。
搭建备集群实践
nebula-spark-connector 的 GitHub 仓库地址:https://github.com/vesoft-inc/nebula-spark-connector,本文采用 nebula-spark-connector 的 release-3.6 分支,并以 Spark 3.x 为例。
首先,准备相关的运行环境:
`$ git clone -b release-3.6 https://github.com/vesoft-inc/nebula-spark-connector.git
$ cd nebula-spark-connector
$ mvn clean package -Dmaven.test.skip=true -Dgpg.skip -Dmaven.javadoc.skip=true -pl nebula-spark-connector_3.0,example -am -Pscala-2.12 -Pspark-3.0`
NebulaGraph 的导入导出可以直接使用 example 中的 Nebula2Nebula.scala 完成,通过上面 maven 打包命令后在 example 的 target 目录可得到 example-3.0-SNAPSHOT-jar-with-dependencies.jar 文件,提交 Spark 任务命令:
`spark-submit --master local \
--conf spark.driver.extraClassPath=./ \
--conf spark.executor.extraClassPath=./ \
--class com.vesoft.nebula.examples.connector.Nebula2Nebula \
example-3.0-SNAPSHOT-jar-with-dependencies.jar \
-sourceMeta "xxxxx:9559" -targetMeta "yyyyy:9559" -targetGraph "yyyy:9669" -sourceSpace "source" -targetSpace "target" -includeTag "user" -excludeTags "aa,bb" -excludeEdges "cc,dd" -limit 2 -batch 2 -p 8 -timeout 50000 -u root -passwd nebula`
参数解释:
- sourceMeta:源 nebula 服务 metad 地址(从哪里导出)
- targetMeta:目标 nebula 服务 metad 地址
- targetGraph:目标 nebula 服务 graphd 地址,多个地址以英文逗号隔开(导出数据重新组装 INSERT 语句将通过此地址进行提交)
- sourceSpace:源 nebula 的 Space,也就是要导出的 Space 名称
- targetSpace:目标 nebula 的 Space,也就是要导入的 Space 名称
- includeTag:指定导出的 Tag,不指定就全部 Tag 导出
- excludeTags:排除哪些 Tag 不进行导出同步
- excludeEdges:排除哪些 Edge 不进行导出同步
- limit:从源 nebula 导出时每次 scan 多少数据,值越大单次 scan 的数据量越大,对源 nebula 服务器的压力越大,在没有达到磁盘和网络 IO 的瓶颈前,理论上值越大导出更快
- batch:导出的数据多少一批打包成一条 INSERT 语句发送到目标 nebula 服务的 graphd 机器上进行执行
- p:也叫 writeParallel, 导出的数据拆分成多少个任务并行写,值越大速度越快,但是目标 nebula 服务器压力越大
- timeout:每次 scan 源数据的超时时间
优化改造
这里讲下为什么要做这些优化改造:
1.经我们线上验证,Nebula2Nebula 示例是一次所有 Partition 导出后才做导入操作,对于数据量非常大的情况下并不友好、效率太低,此外对 Spark 来说会占用太多的内存可能会导致内存不足;不过,官方表示他们不是所有的 Partition 导出之后才进行导入,而是边读边写,且消耗内存很小。因为我这边已经完成了相关的开发工作,边读边写的操作就留给读者你来实践了。
2.无法支持源 NebulaGraph storaged 地址为 127.0.0.1 的场景(一般属于单机场景),因为 Spark 任务导出的 storaged 地址是通过 metad 元数据获取,就会导致导出任务会请求 127.0.0.1 的 storaged;
3.缺少导出和导入统计,不知道当前已经导出多少数据量; 下面开始进入改造(解决上述问题)部分:
导出优化
本次的优化改造的导出优化:将 Partition 进行拆分,改成多线程的方式,每个线程处理一个 Partition。
Nebula2Nebula.scala 改造:增加 readParallel 参数,用于指定多少个线程可同时读取 nebula,控制读取速率,不然可能会对线上服务器照成影响:
`val readParallelOption = new Option("rp", "readParallelNum", true, "parallel for read data")
options.addOption(readParallelOption)
val readParallelNum: Int =
if (cli.hasOption("readParallelNum")) cli.getOptionValue("readParallelNum").toInt else partitions
for (partitionId <- 1 to readPartition) {
val task = new Runnable {
def run(): Unit = {
syncTagPartitionData(spark,
sourceConfig,
sourceSpace,
limit,
readPartition,
targetConfig,
targetSpace,
batch,
tag,
writeParallel,
user,
passwd,
overwrite,
partitionBatch,
eachScanWaitTime,
partitionId
)
}
}
threadPool.execute(task);
}`
NebulaOptions.scala 改造:增加参数可指定 Partition 读取,代码示例:
`var readPartitionId: Int = parameters.getOrElse(READ_PARTITION_ID, 0).toString.toInt`
SimpleScanBuilder.scala 改造:
`override def planInputPartitions(): Array[InputPartition] = {
//读取指定的分区
Array(NebulaPartitionBatch(Array(nebulaOptions.readPartitionId)))
}
case class NebulaPartitionBatch(partitions: Array[Int]) extends InputPartition`
NebulaPartitionReaderFactory.scala 改造:读取指定分区数据,代码示例:
`class NebulaPartitionReaderFactory(private val nebulaOptions: NebulaOptions,
private val schema: StructType)
extends PartitionReaderFactory {
private val LOG: Logger = LoggerFactory.getLogger(this.getClass)
override def createReader(inputPartition: InputPartition): PartitionReader[InternalRow] = {
val partitions = inputPartition.asInstanceOf[NebulaPartitionBatch].partitions
if (DataTypeEnum.VERTEX.toString.equals(nebulaOptions.dataType)) {
LOG.info(s"Create NebulaVertexPartitionReader partitions:${partitions}")
new NebulaVertexPartitionReader(partitions, nebulaOptions, schema)
} else {
LOG.info(s"Create NebulaEdgePartitionReader partitions:${partitions}")
new NebulaEdgePartitionReader(partitions, nebulaOptions, schema)
}
}
}`
支持本地地址
下面开始支持导出 storaged 的地址为 127.0.0.1,示例代码参见:
Nebula2Nebula 改造:支持配置源 nebula 的 storaged 连接地址,示例代码见下:
`val sourceStorageOption =
new Option("sourceStorage", "sourceStorageAddress", true, "source nebulagraph storage address")
options.addOption(sourceStorageOption)
NebulaReader.scala 改造:替换原来的 StorageClient,示例代码见下:
this.storageClient = new SpecialStorageClient(nebulaOptions, address.asJava, nebulaOptions.timeout)`
增加 SpecialStorageClient.scala: 用于获取 storaged 地址的时候返回指定的 storageAddress,示例代码见下:
`class SpecialStorageClient(nebulaOptions: NebulaOptions, addresses: util.List[HostAddress], timeout: Int = 10000, connectionRetry: Int = 3,
executionRetry: Int = 3, enableSSL: Boolean = false, sslParam: SSLParam = null)
extends StorageClient(addresses, timeout, connectionRetry, executionRetry, enableSSL, sslParam) {
private val LOG: Logger = LoggerFactory.getLogger(this.getClass)
override def connect(): Boolean = {
val success = super.connect()
if (!success) {
return success
}
val storageAddress = nebulaOptions.getStorageAddress
if (storageAddress.isEmpty) {
return success
}
setStorageAddress(storageAddress)
LOG.info(s"Set special storage address:${storageAddress.asJava} | value:${nebulaOptions.storageAddress}")
success
}
private def setStorageAddress(storageAddress: ListBuffer[HostAddr]) = {
val clazz = this.getClass
var field = classOf[StorageClient].getDeclaredField("metaManager")
field.setAccessible(true)
var metaManager = new SpecialStorageMetaManager(addresses, timeout, connectionRetry, executionRetry, enableSSL, sslParam)
metaManager.setStorageAddress(storageAddress)
field.set(this, metaManager)
}
}
class SpecialStorageMetaManager(address: util.List[HostAddress], timeout: Int, connectionRetry: Int,
executionRetry: Int, enableSSL: Boolean, sslParam: SSLParam) extends
MetaManager(address, timeout, connectionRetry, executionRetry, enableSSL, sslParam) {
private val LOG: Logger = LoggerFactory.getLogger(this.getClass)
var storageAddress: ListBuffer[HostAddr] = null;
override def getPartsAlloc(spaceName: String): util.Map[Integer, util.List[HostAddr]] = {
val partMap: util.Map[Integer, util.List[HostAddr]] = getPartsAlloc(spaceName)
if (storageAddress != null && !storageAddress.isEmpty) {
partMap.keySet().forEach(partId => {
LOG.error(s"Storage partId:${partId} address replace fix value:${storageAddress.asJava}")
partMap.put(partId, storageAddress.asJava)
})
}
partMap
}
override def listHosts(): util.Set[HostAddr] = {
if (storageAddress != null && !storageAddress.isEmpty) {
LOG.error(s"[listHosts] Storage address replace fix value:${storageAddress.asJava}")
return storageAddress.toSet.asJava
}
super.listHosts()
}
override def getLeader(spaceName: String, part: Int): HostAddr = {
if (storageAddress != null && !storageAddress.isEmpty) {
LOG.error(s"[getLeader] Storage address replace fix value:${storageAddress.asJava}")
return storageAddress.last
}
super.getLeader(spaceName, part)
}
def setStorageAddress(storageAddress: ListBuffer[HostAddr]): Unit = {
this.storageAddress = storageAddress
}
}`
支持导入打印统计
新增导出导入统计打印,方便知道当前进度。
增加 ReadWriteStats.scala:用于统计,示例代码见下:
`object ReadWriteStats {
private var readCounter = new ConcurrentHashMap[String, Int]();
private var writeCounter = new ConcurrentHashMap[String, Int]();
def incrementReadCount(key: String, num: Int): Int = {
readCounter.compute(key, (_, count) => count + num)
}
def getReadCount(key: String): Int = {
readCounter.getOrDefault(key, 0)
}
def incrementWriteCount(key: String, num: Int): Int = {
writeCounter.compute(key, (_, count) => count + num)
}
def getWriteCount(key: String): Int = {
writeCounter.getOrDefault(key, 0)
}
}`
NebulaReader.scala 改造:增加 scan 读取统计数据输出,示例代码见下:
`protected def getRow(): InternalRow = {
......
val totalCount = ReadWriteStats.incrementReadCount(nebulaOptions.label, 1)
if (totalCount > 10000 && totalCount % 10000 == 0) {
LOG.info(s"Reader vertex:${nebulaOptions.label} , totalCount:${totalCount}")
}
mutableRow
}
protected def hasNextVertexRow: Boolean = {
.....
if (!hashNext) {
LOG.info(s"Finish read vertex:${nebulaOptions.label} , readTotalCount:${ReadWriteStats.getReadCount(nebulaOptions.label)}")
}
hashNext
}
protected def hasNextEdgeRow: Boolean = {
....
if (!hashNext) {
LOG.info(s"Finish read edge:${nebulaOptions.label} , readTotalCount:${ReadWriteStats.getReadCount(nebulaOptions.label)}")
}
hashNext
}`
NebulaVertexWriter.scala 改造:增加写入统计数据输出,示例代码见下:
`def execute(): Unit = {
val nebulaVertices = NebulaVertices(propNames, vertices.toList, policy)
val exec = nebulaOptions.writeMode match {
case WriteMode.INSERT =>
val vertexCount = nebulaVertices.values.length
val totalCount = ReadWriteStats.incrementWriteCount(nebulaOptions.label,vertexCount)
if (totalCount > nebulaOptions.printRWRowCount && totalCount % nebulaOptions.printRWRowCount == 0) {
LOG.info(s"Batch insert vertex:${nebulaOptions.label} , count: ${vertexCount} , totalCount:${totalCount}")
}
...
}
}
override def commit(): WriterCommitMessage = {
if (vertices.nonEmpty) {
execute()
}
LOG.error(s"Write vertex:${nebulaOptions.label} task finished. Haven write totalCount:${ReadWriteStats.getWriteCount(nebulaOptions.label)}")
.....
}`
改造完毕之后重新使用 maven 命令打包,再使用 Spark 命令提交任务即可。
这里打包了相关的代码:请点击阅读原文查看,如果你有需要可以拷贝到你的运行环境,自行替换。
以上,感谢你的阅读。
如果本文有任何技术错误,麻烦评论指出,谢谢你的反馈。
关于 NebulaGraph
NebulaGraph 是一款开源的分布式图数据库,自 2019 年开源以来,先后被美团、京东、360 数科、快手、众安金融等多家企业采用,应用在智能推荐、金融风控、数据治理、知识图谱等等应用场景。GitHub 地址:https://github.com/vesoft-inc/nebula



