
开发日志
如何实现 NebulaGraph 与 PyG 高效集成?
交流图数据库技术?加入 Nebula 交流群请先填写下「你的 Nebula 名片」,Nebula 小助手会拉你进群~~
导读:开源之夏 2025 ,蔡锋泽同学成功中选「NebulaGraph PyG Integration」项目。本项目旨在实现 NebulaGraph 与 PyG(PyTorch Geometric)的高效集成,为图神经网络研究人员与开发者提供更便捷的大规模图数据训练支持。本文从蔡同学的技术视角回顾整个开发过程,重点分享架构设计及技术实现。

NebulaGraph PyG Integration
旨在简化图神经网络(GNN)任务从 NebulaGraph 读取和处理图数据的过程。通过封装底层图存储访问和数据转换,帮助用户便捷调用 NebulaGraph 数据,免去繁琐的数据预处理,使 GNN 的训练和推理更加高效便捷。
https://github.com/Fengzdadi/nebula-pyg (后续会捐赠给 Nebula Contrib)
一、架构设计
项目的整体设计参考了 KUZU 为 PyG 提供远程图数据适配的思路,并在其基础上结合 NebulaGraph 的特性做了诸多改进。
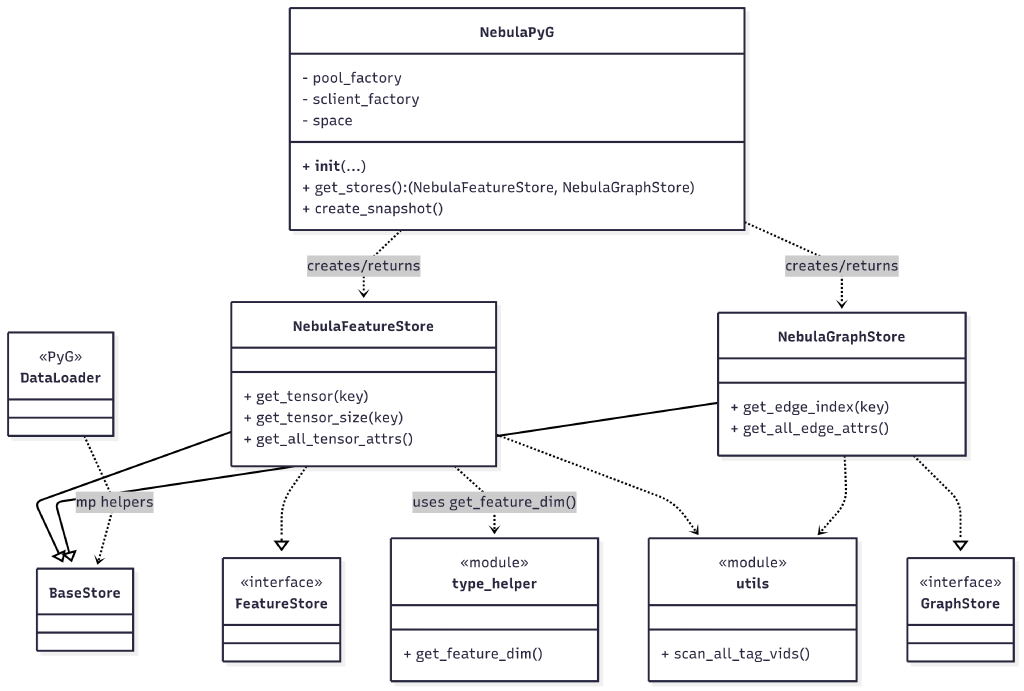
核心是实现 PyG 定义的 FeatureStore 和 GraphStore 接口。为了简化用户的使用流程,我们在上层封装了 NebulaPyG 类,提供一行代码初始化两个存储实例的能力。该类还提供了 create_snapshot() 方法,用于解决关键的 VID(Vertex ID)映射问题。
我们将一些通用工具模块化,放在 utils.py 和 type_helper.py 中,包括特征维度判断工具 get_feature_dim()、全局快照生成方法 scan_all_tag_vids() 等。此外,还引入了 base_store 作为基类,用于处理 PyG 的 DataLoader 在多进程环境中引发的资源竞争与同步问题。
以下是项目中的主要类关系图:
二、技术实现
(一)开发环境配置
- 环境管理
nebula-python 选用 pdm 作为包管理工具,主要看中其能严格锁定依赖版本的能力,适合多端协作,但由于我是独立开发,所以并未体会到便捷之处,反而踩了一些坑,比如在安装 torch 等相关库时仍遇到一些兼容性问题,需通过手动配置解决。
2.NebulaGraph 环境
目前社区版的 storaged 必须在与 Python 解释器相同的网络环境下运行,并且 NebulaGraph 仅能在指定的 Linux 环境下安装。
如果使用 nebula-pyg,有以下两种方式,更推荐前者:
在指定的 Linux 环境中本地安装 NebulaGraph 和 Python 环境;
使用 docker-compose 启动 NebulaGraph,并将 Python 解释器通过 SSH 连接至同一网络。
不推荐使用 WSL,经思为老师提醒,它在 I/O 性能方面存在已知问题,我们在测试阶段也确实遇到了 storaged崩溃及文件读写错误。
(二)VID 映射方案
NebulaGraph 支持 FIXED_STRING(N) 和 INT64 两种 VID 格式,而 PyG 要求节点索引必须为{0,……,num_nodes-1}。在 KUZU 的实现中,要求用户在导入数据时,index 必须满足 PyG 的要求,但考虑到工业级别中的图数据 ID 通常不符合该要求(如 UUID 或 Snowflake 算法生成的分布式 ID),并且在分布式数据库中,大部分情况不会是自增的int, 因此 VID 映射尤为必要。
听从思为老师的建议,我放弃了初期设想的 KV-Cache 方案,因其难以处理动态图中顶点删除后的序号连续性。最终采用了 Snapshot 机制,并使用 python 原生的 pickle 进行持久化。
Snapshot 产生的 pickle 文件 会包含有以下几个内容:
vid_to_idx
idx_to_vid
vid_to_tag:节点分类信息;
edge_type_groups:三元组信息
前两个正反两项映射的设计并非冗余—— dict 里面的 KV 对正向的查询更快,时间复杂度应该是 O(1),如果在想通过 idx 去找 vid 的时候仅仅用 vid_to_idx ,时间复杂度就会到达 O(n)。
(三)FeatureStore 的扫描策略
最初使用的是 scan_vertex_async 接口进行全图扫描,再过滤出所需顶点的属性。用NebulaGraph 提供的 basketballplayer 成功跑通了所有的测试,但却发现这种方法在大规模数据集上效率极低(如 ogbn-products 数据集读取超过 8 小时仍未有进展)。
我试图参考 KUZU 的实现方式:KUZU scan_vertex 函数中,有 indices 这个参数,能直接根据 indices(index) 直接从 storage 中获取指定 indice 的属性。那么在 NebulaGraph 中,只需要在 stroaged 中加入一个算子即可。
该方案被思为老师否决了,当时思为老师说的是 storaged 只适合做全图扫描,并不适合做条件查询。总结如下:
NebulaGraph 的 storaged 是基于 RocksDB,有天然的顺序读(iterator)方案,直接具有全图遍历的功能。
如果想实现这个功能,至少要做谓词求值、联合条件、选择最佳索引、回表取属性、聚合/去重/排序这些事情,从职责上来讲,这些都是 query 优化器的工作,最终还是应该由 graphd 来做。
最终我们采用 FETCH 语句查询,实测在 10 万级顶点的读取可在 1.2–1.5 秒内完成。
(四)get_tensor 中的 x,y 处理
PyG 要求将特征数据拼接为 data.x,标签数据作为 data.y。但 NebulaGraph 不支持 Vector 或复合类型。
我们引入了 Y_CANDIDATES 列表(包含 label、y、target、category 等常见标签名),自动将匹配列作为 data.y。
对于特征列,提供了两种模式:
x 模式:自动将所有特征列拼接为 data.x;
feats 模式:返回原始特征列,用户可自行拼接和消融。
(五)多进程处理
在引入查询机制后,当 DataLoader 的 num_workers 大于 1 时,出现了响应数据错位的问题。根本原因是 NebulaGraph 的 Session 不支持多进程共享,包括 session_pool 也不是进程安全的。
我们通过工厂函数 + 懒加载模式为每个进程创建独立 Session,详细方案可参考 Multi-process Description。值得注意的是,PyTorch 的 DataLoader 支持 fork 和 spawn 两种多进程模式,后者行为有所不同,但目前我们的方案是基于 fork 模式设计的。
三、致谢
本项目最终实现了一个功能完整、支持丰富的 NebulaGraph-PyG 适配器,在某些方面(如特征处理模式、Snapshot 机制),相比 KUZU 提供了更丰富的功能选项。
特别感谢思为老师对我的指导,如最开始提到的环境问题,我花了一周还没有搞定,思为老师知道后,直接和我开了视频会议,一边详细得和我解释 NebulaGraph 的架构和项目重点,一边花了 2 个小时远程帮我配好了开发环境。
另外,思为老师也让我充分感受到在开源社区中的平等协作。我在和思为老师的线上线下交流中,每次都会带“您”,但思为老师告诉我不必如此,我才意识到“您”带来的疏远感确实好强,这也让我想起我的朋友 iyear 曾告诉我的:在社区里,你身份地位是最不被 care 的,不论是地位,不论年龄,不论国籍,大家平等交流,用心解决问题。
写到这里已经凌晨四点了。原来热爱,从不觉困。
💡本文经过修改与删减,更多技术细节与开发故事见蔡同学博客
交流图数据库技术?加入 Nebula 交流群请先填写下「你的 Nebula 名片」,Nebula 小助手会拉你进群~~




