用户案例
每月风控止损超百万元:携程酒店业务基于 NebulaGraph 的风控实践
交流图数据库技术?加入 Nebula 交流群请先填写下「你的 Nebula 名片」,Nebula 小助手会拉你进群~~
本文基于携程集团资深风控专家@费茉莉,在 NebulaGraph MeetUp 上的分享整理而成。
携程酒店业务每日承载海量用户交易,但也面临着持续的黑灰产团伙攻击:通过批量账号、设备、IP 等资源进行规模化套利,传统基于个体行为的风控手段难以有效识别。
使用 NebulaGraph 并对图计算进行相应优化升级后,每月可为平台带来数百万元的增量止损。本文将从技术选型、数据建模、算法演进、工程优化等方面,详细介绍我们基于 NebulaGraph 的实践历程。
携程酒店 BU 使用的是 NebulaGraph 3.x 开源版,图计算性能相对有限,在追求极致性能的业务需求下,结合实际情况进行二次了开发,希望本文能为社区用户带来一些启发。
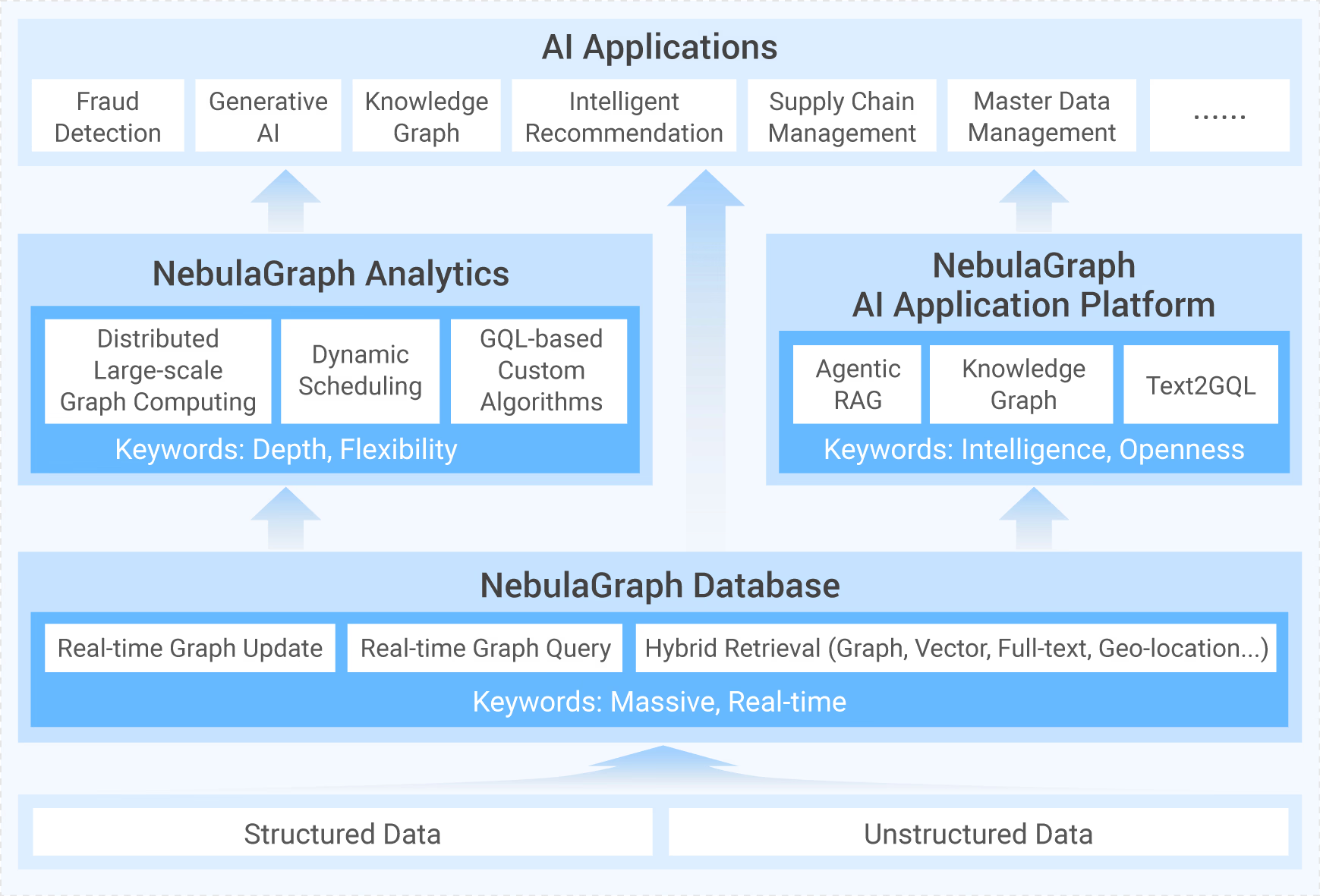
NebulaGraph 5.2.1(企业版)将图计算模块升级为图分析,支持在超大规模的图上运行复杂图算法,与开源版相比,仅需其 20% 资源,即可实现 5-10 倍的性能提升,同时支持 GQL 自定义算法、多种方式导入丰富的数据源,并提供可视化界面用于开发和管理分析作业,支持定时调度作业,实现图分析工作流自动化。
一、项目背景与挑战
风控的目标是研究和治理黑灰产,保障平台安全。
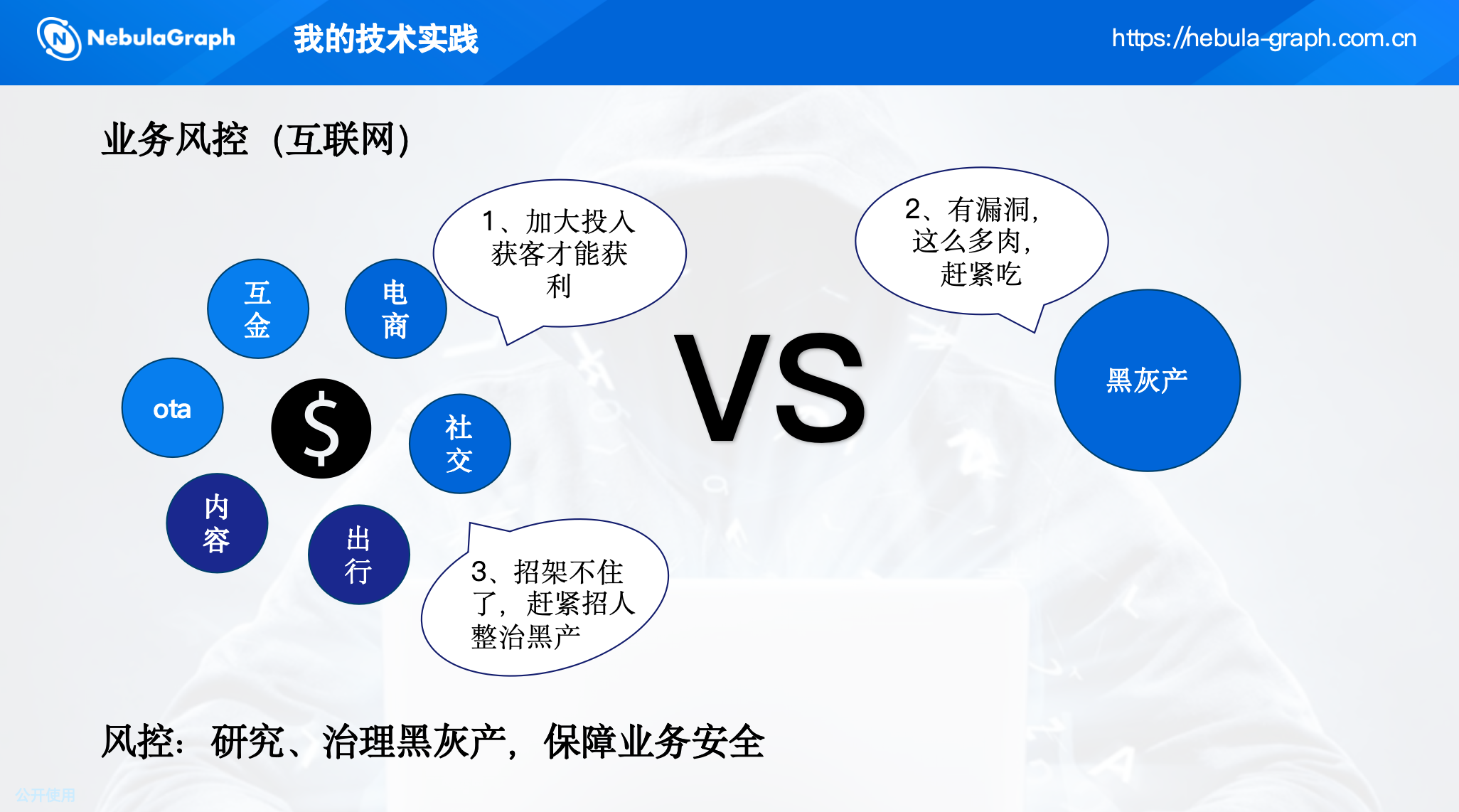
在携程酒店场景下,黑灰产呈现出明显的团伙化特征:他们利用大量账号协同操作,通过注册、抢优惠、虚假交易等方式牟利。单个账号的行为可能看似正常,但账号之间的关联关系(如共用设备、支付账户、手机号等)却能暴露其团伙属性。
传统的风控体系经历了从经验驱动(黑白名单、简单规则)到数据驱动(传统机器学习),再到 AI 驱动(深度学习、图计算)的演变。
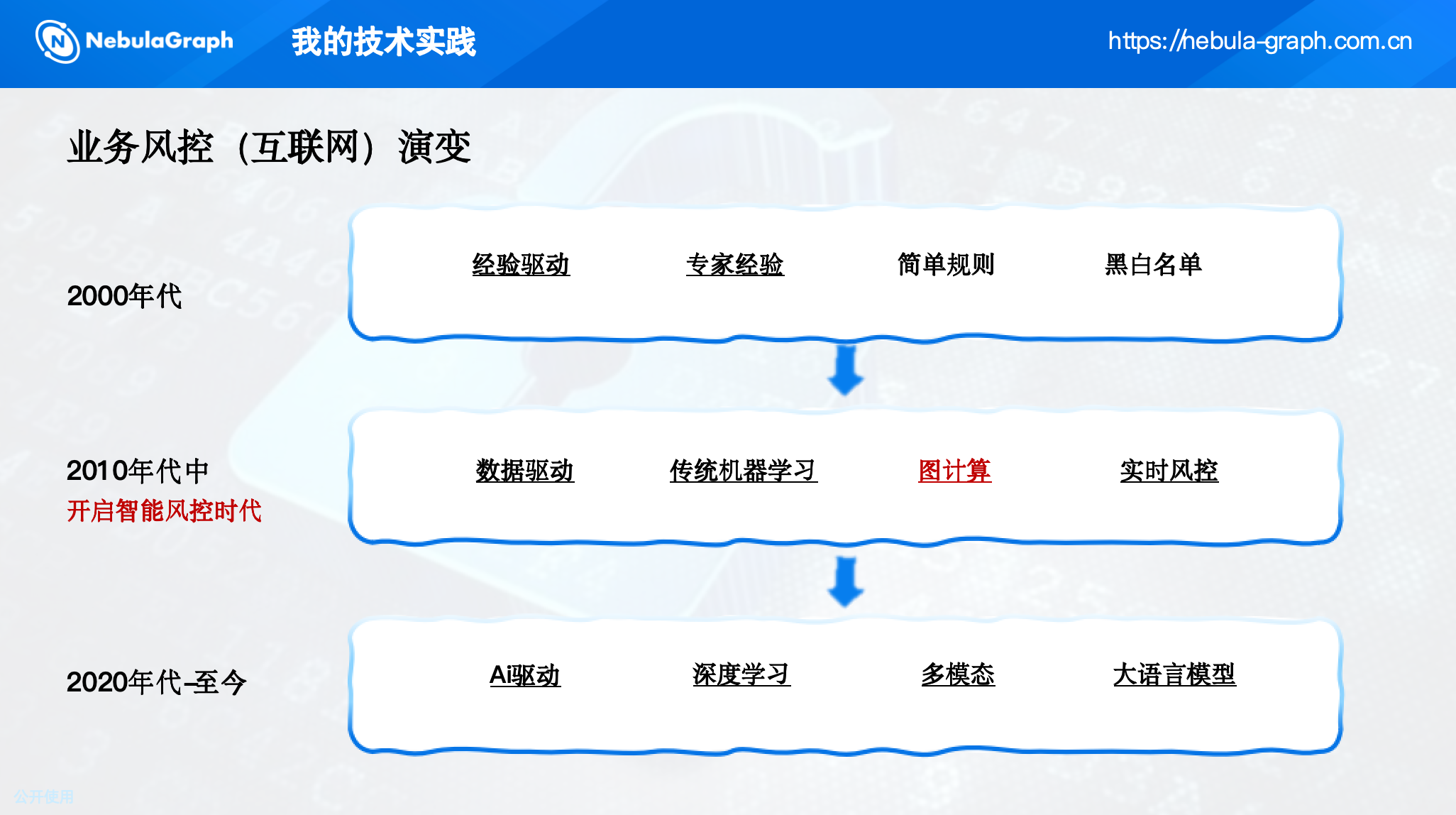
其中,图计算成为挖掘团伙的核心技术,因为它天然擅长刻画海量实体间的关联关系。携程酒店业务拥有千万亿级的用户行为数据,非常适合引入图技术进行团伙挖掘。
二、为什么选择 NebulaGraph
在项目初期,我们调研了市面上七八种图数据库,从数据导入性能、查询延迟、生态完备性等维度进行对比,最终选择了 NebulaGraph.
主要原因如下:
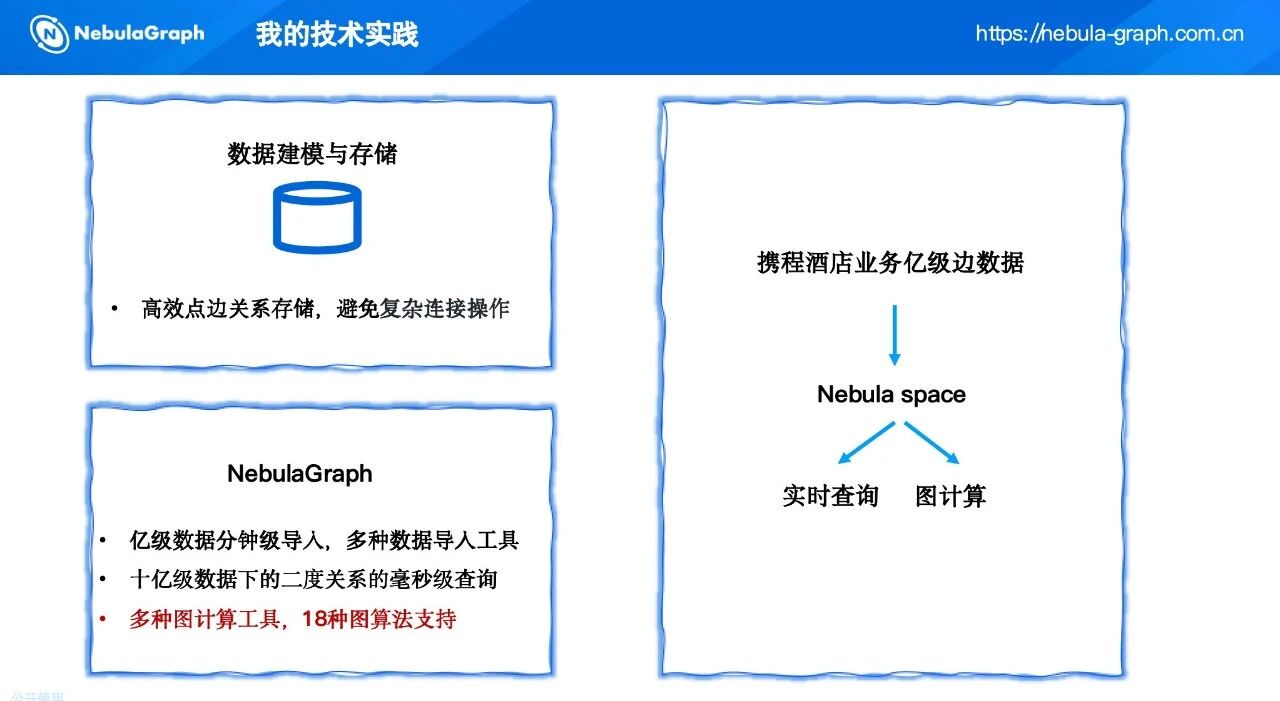
- 数据导入性能:携程酒店业务每天产生亿级行为数据,需要图数据库能够快速导入。NebulaGraph 的 Exchange 工具支持多种数据源(如 Hive、Kafka),实测可达到亿级数据分钟导入,满足我们离线批处理的需求。
- 查询性能:风控场景需要实时或近实时的图查询,例如查询一个账号的二度关联关系。NebulaGraph 在十亿级边规模下,二度关系查询可达毫秒级延迟,为未来实时风控提供了可能。
- 生态完善:NebulaGraph 内置了 18 种图算法,并提供了与图计算框架的衔接能力。我们可以直接调用内置的连通组件算法进行预计算,再结合外部分布式框架做精细划分,极大降低了开发成本。
- 分布式架构:NebulaGraph 原生支持分布式存储和计算,能够水平扩展,与携程的大数据基础设施匹配良好。
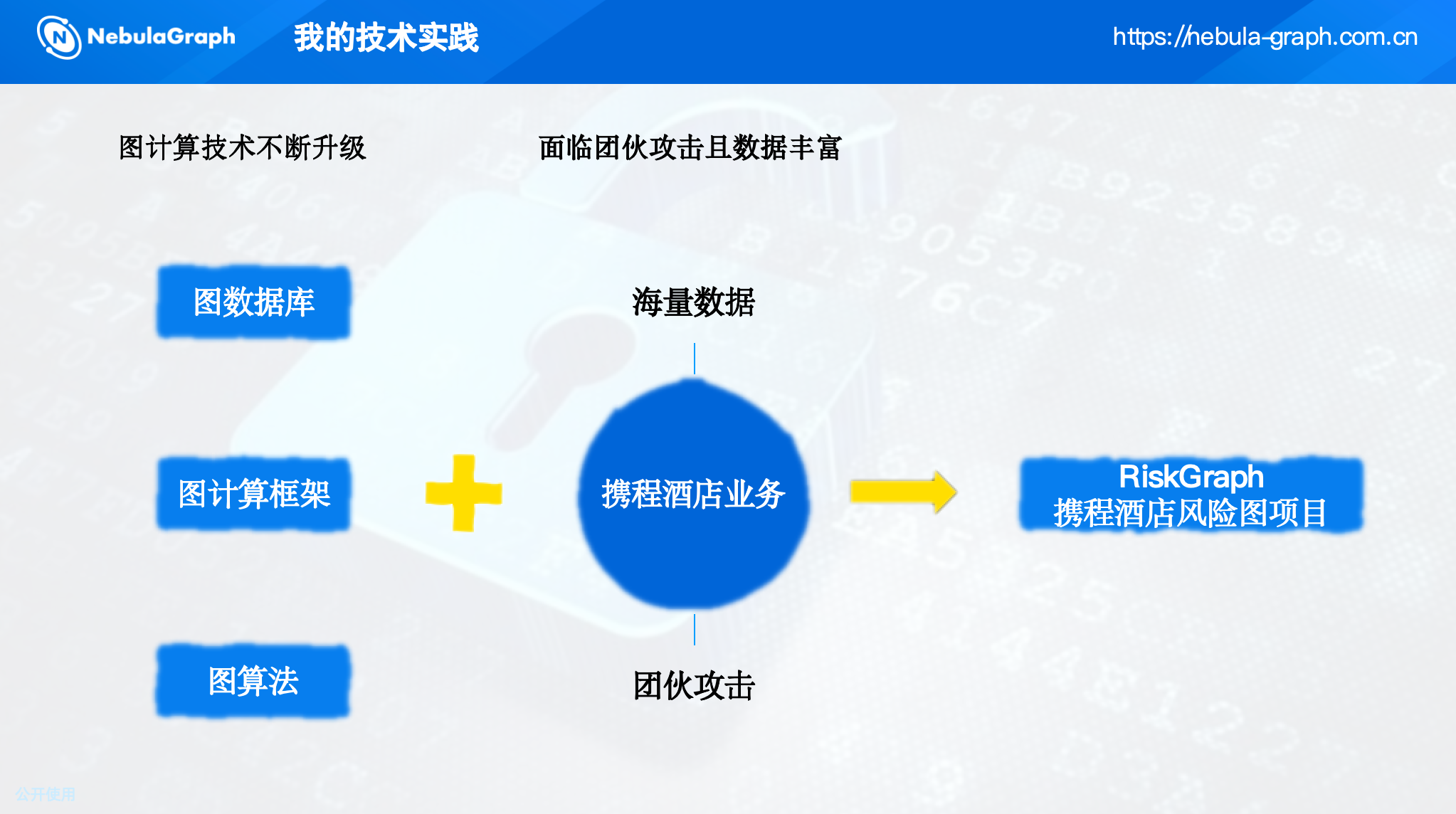
三、数据建模
为了全面刻画用户间的潜在关联,我们尽可能覆盖用户行为的全链路——从注册登录、酒店预订到履约售后,提取了多个维度的实体和关系。

- 点(实体):主要包括用户账号、设备指纹、IP 地址、支付账号、手机号、邮箱等。
- 边(关系):基于业务行为构建了 7 种以上的边类型,例如:
- 登录关系(账号-设备)
- 支付关系(账号-支付账号)
- 预订关系(账号-订单)
- 通讯关系(账号-手机号)
- 赔付关系(账号-赔付记录)
- ……
不同关系对团伙挖掘的贡献度不同,例如设备共用的权重应高于偶尔的通讯。
因此我们引入了带权重的边,使关系强度更贴近实际业务。权重计算公式为:
边权重(W) = 介质类型基础权重 × 交互频率 × 时间衰减因子
其中,介质类型基础权重根据业务经验预设(如设备共用权重最高),交互频率指一段时间内关系出现的次数,时间衰减因子采用指数衰减(近期行为权重更高)。
通过这种方式,我们得到了一个包含亿级点、数十亿级边的异构属性图,存储在 NebulaGraph 的 Space 中。
四、算法模型演进
团伙挖掘本质上是社区发现问题,即将图中的节点划分为若干个内部紧密、外部稀疏的社区,每个社区可能对应一个黑灰产团伙。
1. Louvain 算法及其局限
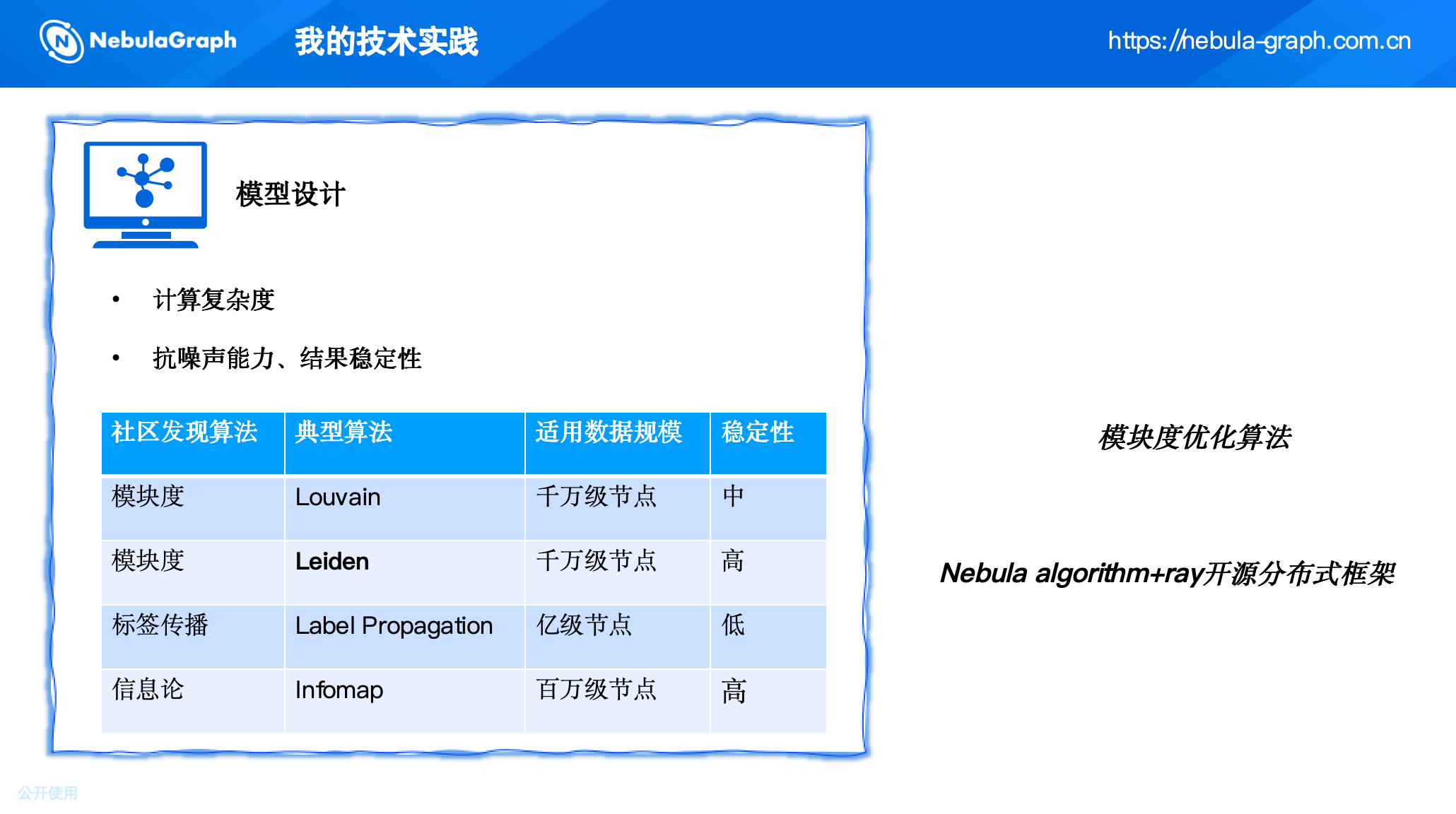
初期我们尝试了 NebulaGraph 内置的 Louvain 算法。
Louvain 是一种基于模块度优化的快速社区发现算法,能够处理大规模图。但在业务验证中我们发现一个问题:Louvain 可能划分出非连通社区,即两个没有直接或间接边关联的节点被划为同一社区。
这在风控业务中意味着风险定性缺乏依据——如果两个账号没有任何关联,我们不能凭算法输出判定他们属于同一团伙。
2. 转向 Leiden 算法
为了解决非连通问题,我们引入了 Leiden 算法。Leiden 是对 Louvain 的改进,在迭代过程中保证社区内部的连通性,同时优化模块度。它能够产出完全连通的社区,更符合风控的业务逻辑。
然而,当时 Leiden 算法只有单机版本(如 Python 的 leidenalg 库),面对亿级图数据,单机串行计算耗时长达 2-3 小时,无法满足日常更新的时效要求。
五、分布式改造与增量更新
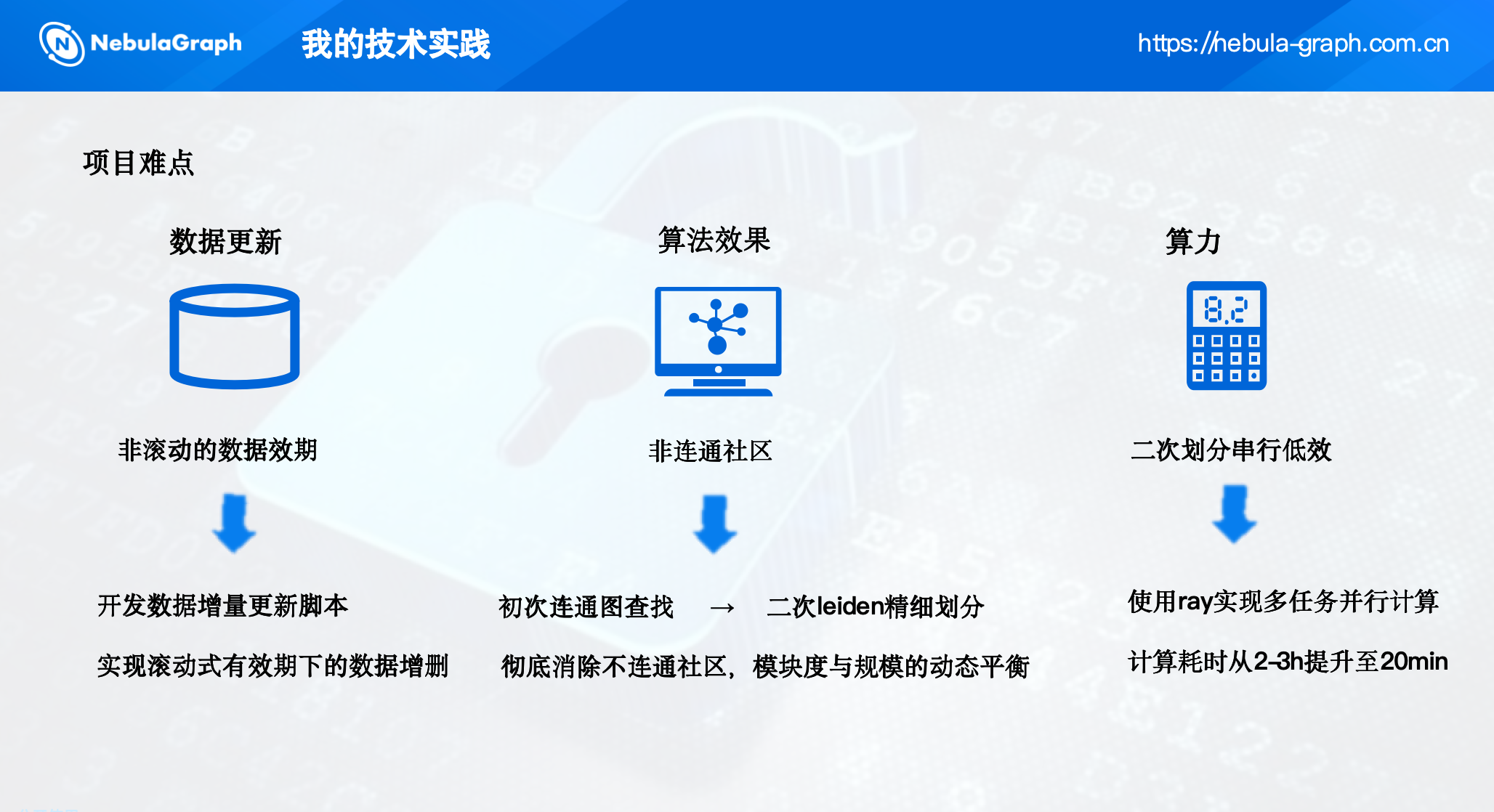
为了在保证结果连通性的同时提升计算效率,我们做了两个关键优化。
1. 利用 NebulaGraph 进行连通图预划分
Leiden 算法在整体图上运行效率低,但我们可以将大图拆解为多个互不连通的子图分别处理。
NebulaGraph 内置了连通组件算法,能够快速找出图中所有连通分量。我们首先在 NebulaGraph 上运行连通组件算法,将原始图拆分为若干连通子图(每个子图内部节点相互可达,子图之间无连接)。
这样,每个连通子图可以独立进行社区发现,且子图规模远小于原图,适合并行处理。
2. 引入 Ray 分布式框架并行计算
在连通子图划分完成后,我们需要对每个子图执行 Leiden 算法。
单机串行处理依然很慢,因此我们引入了 Ray 分布式计算框架。通过在公司内部跨团队沟通,我们借用了已有的 Ray 集群,将 Leiden 计算任务封装为 Ray 的远程任务,实现子图级别的并行处理。
具体实现上,我们使用 Ray 的 @ray.remote 装饰器将 Leiden 算法包装为分布式任务,将多个子图的数据分发到不同节点并行执行。得益于 Ray 的动态调度和容错机制,并行效率大幅提升。
💡@ray.remote 是 Ray 框架中的一个装饰器,用于将普通的 Python 函数或类转换为可在分布式环境中异步执行的“远程任务”或“远程 Actor”。
改造后,整体计算耗时从 2-3 小时降至 20 分钟,完全满足日常更新的时效要求。
3. 数据增量更新机制
业务数据具有时效性,例如用户关系会随时间变化,我们需要支持滚动周期的数据更新。为此,我们开发了一套基于 Python nebula3 客户端的增量更新脚本,实现以下功能:
- 新增数据:每日从数仓抽取新增的行为数据,通过 NebulaGraph 的 nGQL 语句插入新点和边。
- 过期数据:根据数据有效期(如 90 天),删除过期的点和边,保持图数据的时效性。
- 定时调度:将脚本部署在调度系统上,每日自动运行。
通过这种方式,我们实现了滚动式有效期下的数据增删,确保图数据始终反映最新业务状态。
4. 完整的模型链路
综上,我们构建了如下模型链路:
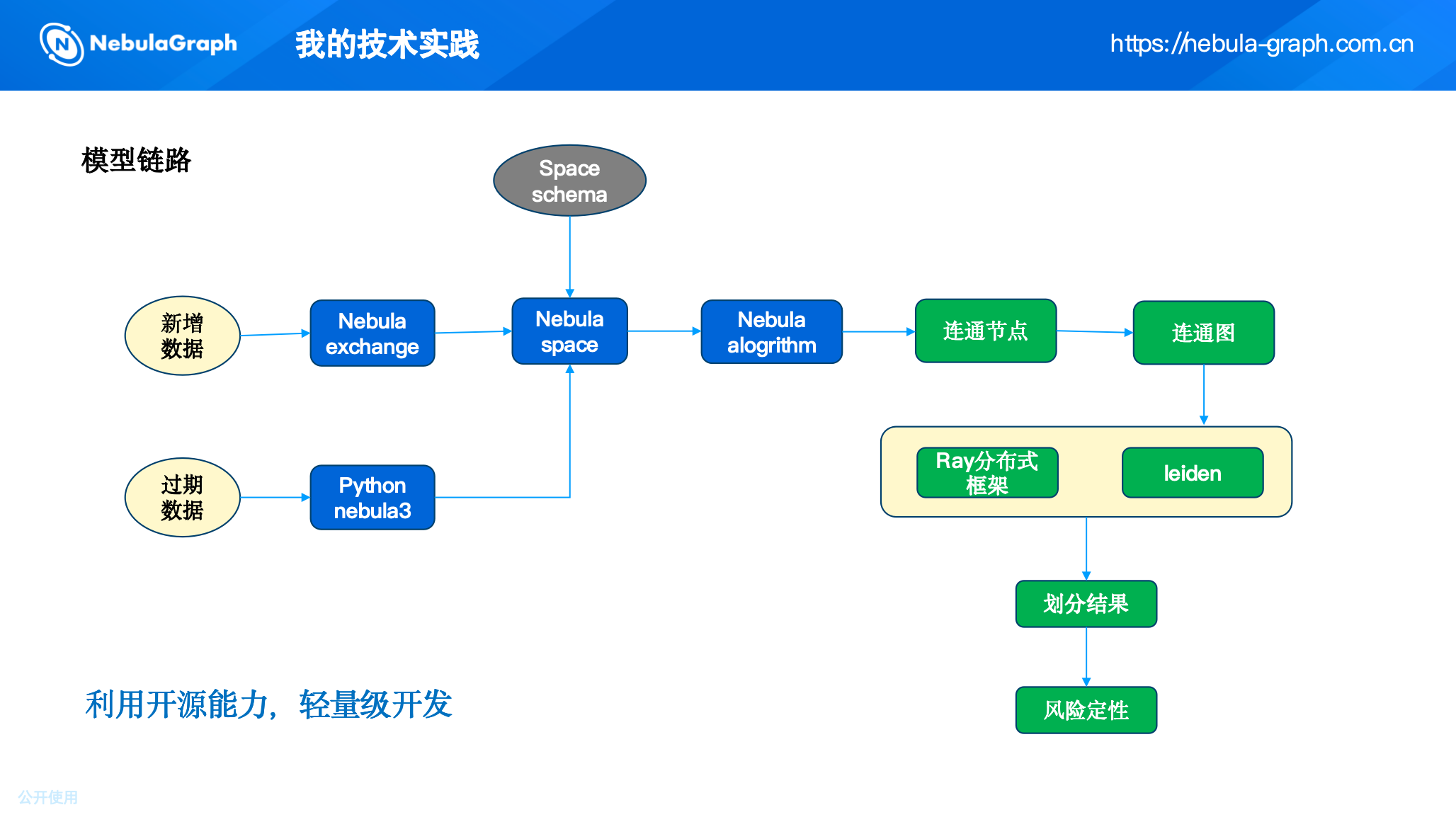
整个链路遵循轻量级开发原则:
一方面充分利用 NebulaGraph 提供的存储、查询和基础算法能力。
另一方面借助开源分布式框架 Ray 解决算力瓶颈,避免了从零开发分布式算法的复杂度。
六、项目成果
该风控图项目上线后取得了显著成效:
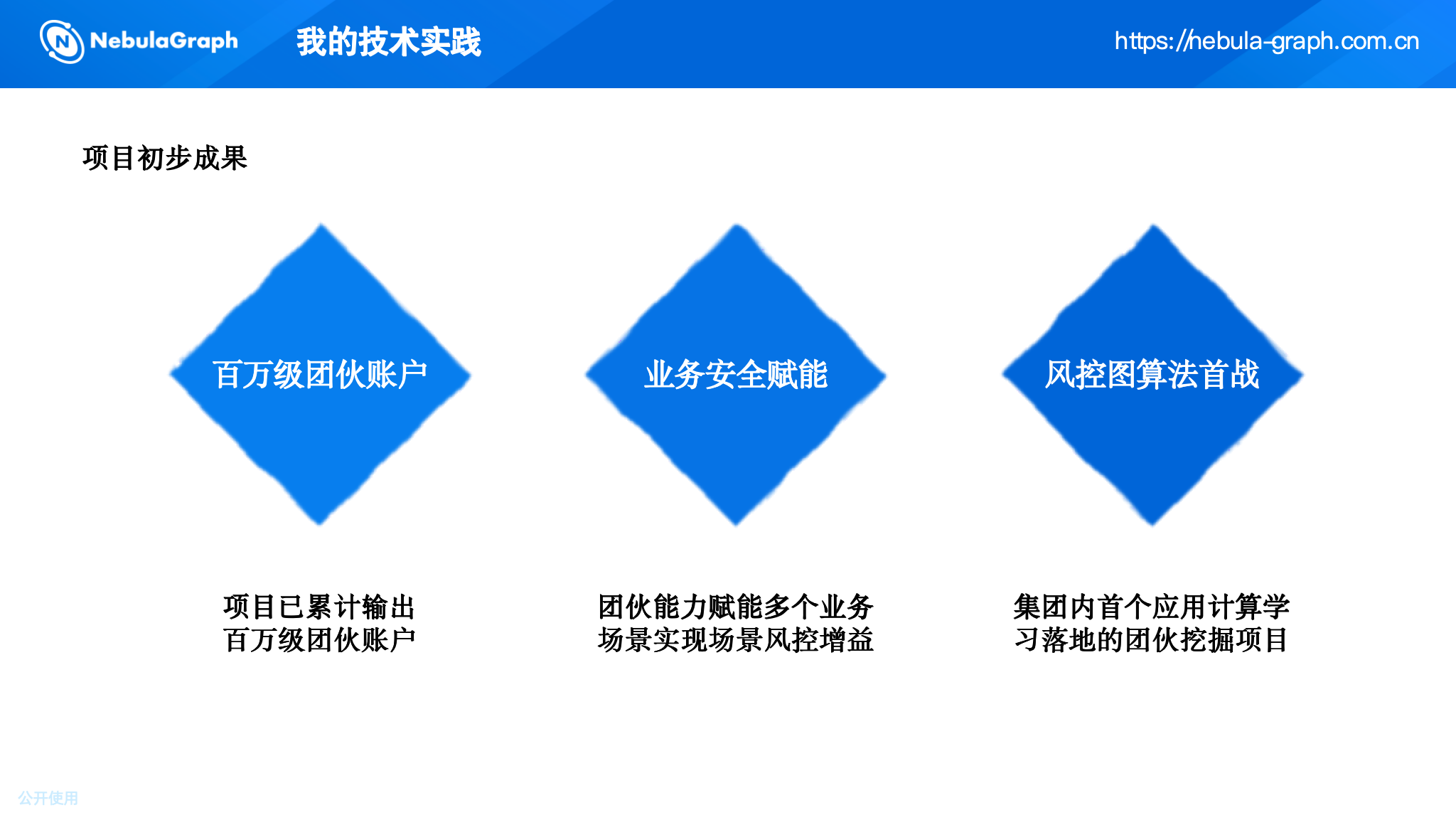
- 风险账户挖掘:累计识别并输出百万级风险账户,覆盖多个黑灰产团伙。
- 业务增益:在多个业务场景(如预订风控、营销反作弊)落地后,带来约 10% 的风险用户识别增益,即原本漏过的风险用户被图模型成功捕获。经测算,每月可为平台带来数百万元的增量止损(拦截欺诈交易、优惠券套利等)。
- 集团内标杆:这是携程集团内首个完整落地的图算法风控项目,为后续图技术在更多场景的推广提供了可复用的框架和实践经验。
七、总结与展望
携程酒店风控图项目的成功,验证了图技术在黑灰产团伙挖掘中的巨大价值。
NebulaGraph 凭借其高性能存储查询、丰富的算法生态和良好的扩展性,成为我们构建图平台的核心组件。同时,通过结合 Ray 等分布式计算框架,我们解决了大规模图算法落地的工程挑战,实现了计算效率的量级提升。
未来,我们计划在以下方向继续探索:
- 实时图计算:将离线图挖掘升级为实时增量计算,更快响应新型团伙攻击。
- 多模态数据融合:引入更多数据源(如设备指纹、生物特征),丰富图特征。
- 图神经网络:探索 GNN 在风险预测中的应用,进一步提升团伙识别的准确率。
图技术在风控领域的潜力远未释放完毕,我们期待与 NebulaGraph 社区及同行们持续交流,共同推动图计算在业务安全中的深度应用。
交流图数据库技术?加入 Nebula 交流群请先填写下「你的 Nebula 名片」,Nebula 小助手会拉你进群~~