技术分享
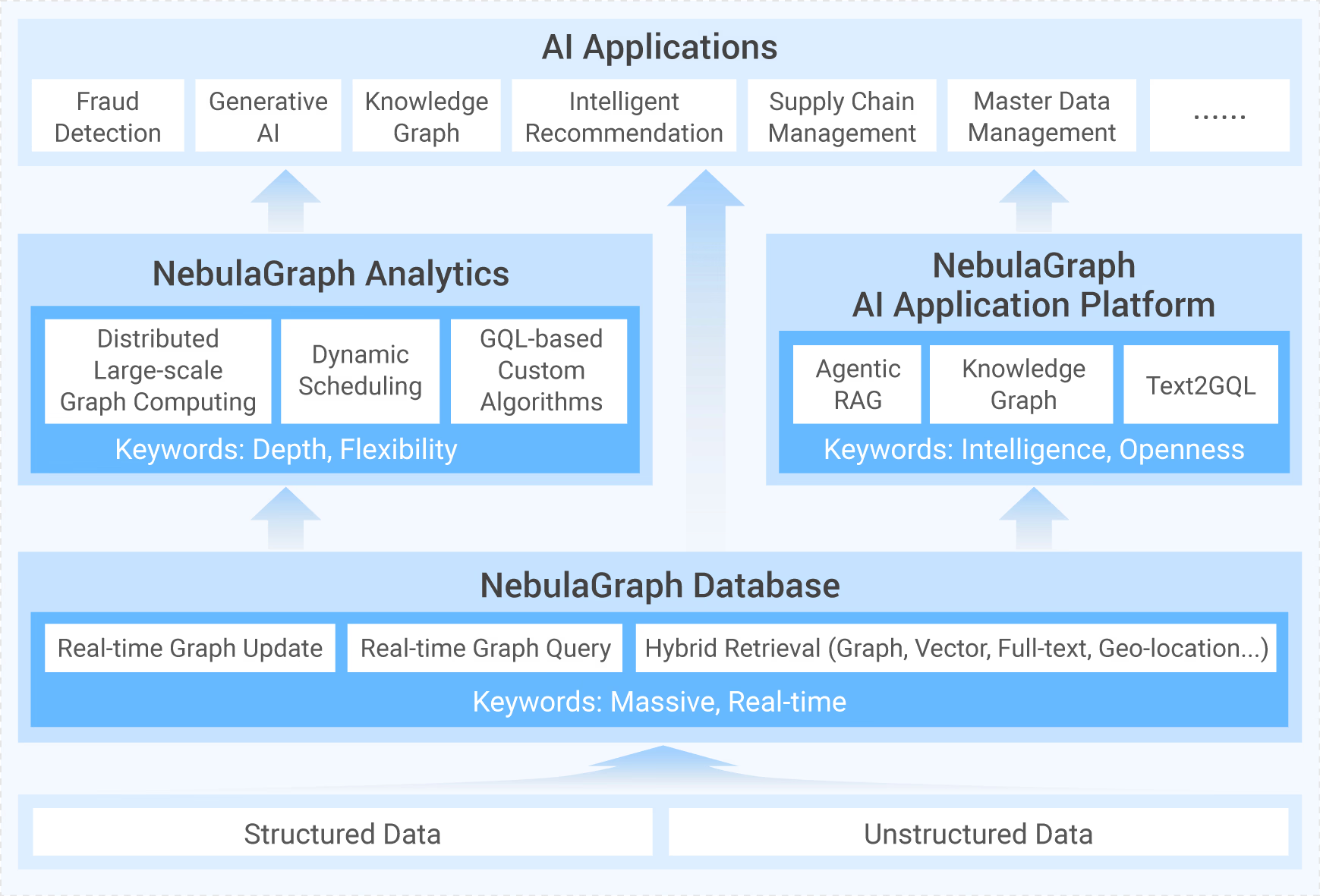
2026 图数据库指南|图数据库经典使用场景与 AI 时代的业务价值
交流图数据库技术?加入 Nebula 交流群请先填写下「你的 Nebula 名片」,Nebula 小助手会拉你进群~~
在过去的十年里,图数据库(Graph Database)经历了从理论探索到工业级爆发的数轮技术浪潮。
2012 年谷歌知识图谱(Knowledge Graph)掀起了关系资产化的序幕;2018 年前后,金融风控与反欺诈将多跳关联分析推向工业刚需;而到了 2025 年,随着 LLM、AI Agent 的大爆发,图数据库市场迎来了新一轮增长高峰。
与图数据库关联的关键词变成了:GraphRAG、本体论(Ontology)、Agent Memory,很多人认为这又是 AI 圈催生出的概念泡沫,但本质上,AI 只是撕开了数字世界的表象,让整个行业深刻意识到:现实世界是什么样,数据就该是什么样。而图数据库,正是最接近现实世界组织方式的数据系统。
一、看得懂世界:图数据库的直觉建模
要理解图数据库的价值,需要先看看传统数据库在面对现实世界时,遇到了怎样的认知鸿沟。
(一)表格里的现实:被强行拆解的关系
在传统的关系型数据库中,现实世界被强行平铺进一张张二维表格里。数据之间的关系,被隐式地埋藏在外键和复杂的索引中。
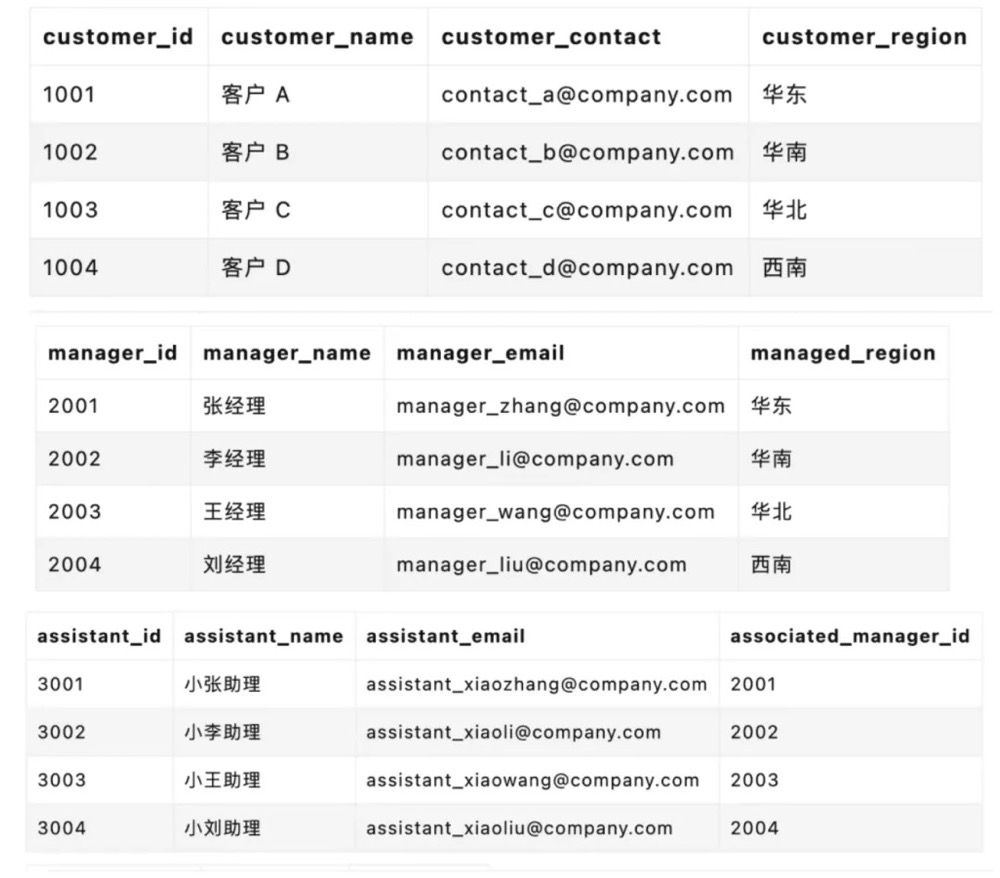
(关系型数据库中,维护客户关系数据,往往会创建三张表,分别代表三个不同的角色)
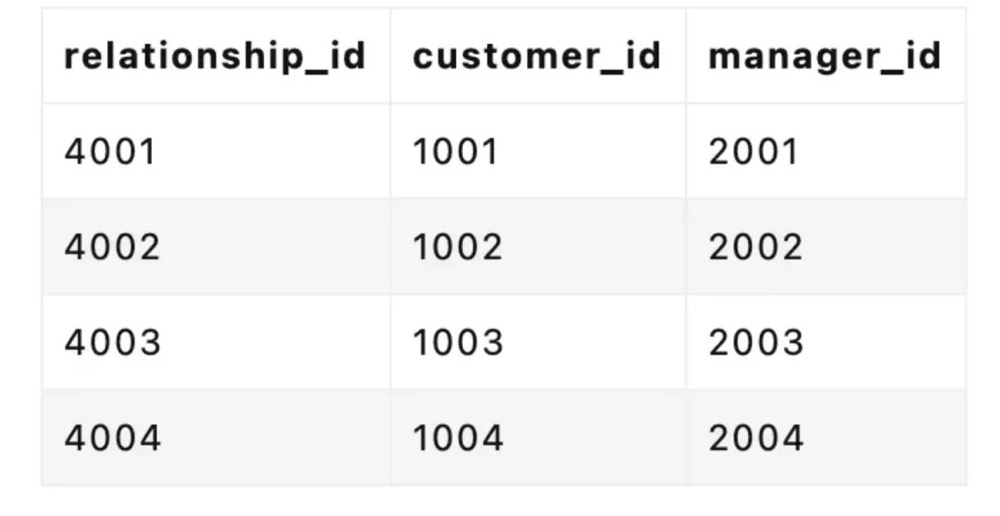
(再使用外键或者维护一张关系表来做关系的对应)
当业务需要查询多层关联时,例如:探寻账户 A 是否通过多层中间人向风险账户 X 转账,系统必须执行多次极其高昂的 JOIN 操作。
这就像在好几个巨大的档案柜里来回翻找关联索引,随着关联层级(跳数)的加深,计算量呈几何级数爆炸,传统数据库的性能会迅速崩溃。
(二)图的直觉建模:像人类一样理解世界
图数据库采取了完全不同的思维方式:系统不需要在查询时临时拼接世界,而是在数据写入的那一刻,就把世界构造成网络。
图数据库用最符合人类直觉的方式,将世界抽象为两个核心元素:
- 节点(Vertex):代表现实中的实体(如一个用户、一部手机、一个 IP、一家公司)。
- 边(Edge) :代表实体间的关系(如持有、登录、转账、持股)。
在这种架构下,关系的查询变成了顺藤摸瓜,你想看一个人背后连接着怎样的设备、交易和风险社区,系统只需顺着「边」一路走下去。
如在 Web3 风控中,查询用户链上转出后的直接关联用户。GQL(国际标准图查询语言)如下:
USE `web3_risk_graph`
MATCH path=(u@`user`{`user_id`:"450055199805200521"})-[@`user_crypto_address`]->(src@`crypto_address`)-[@`transfer`]->(dst@`crypto_address`)<-[@`user_crypto_address`]-(peer@`user`)
RETURN path
对应的可视化页面如下:
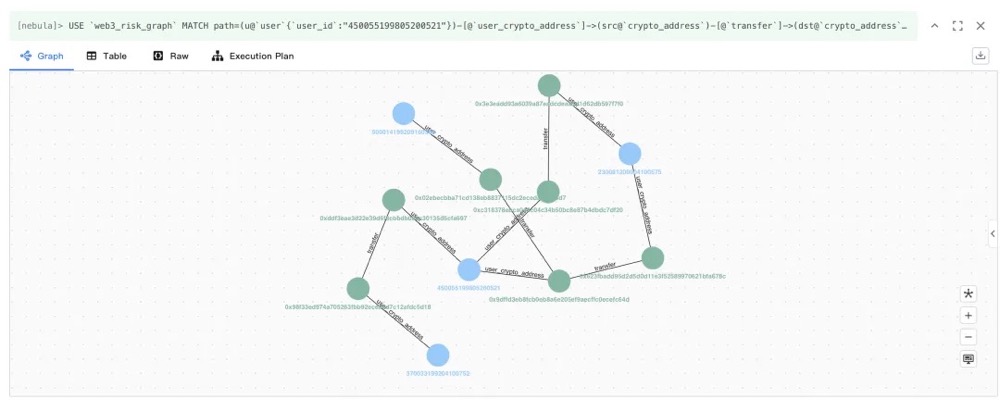
通过可视化界面,可以直观看到从用户 450055199805200521 出发的完整资金流转路径:该用户持有的加密地址向另一个地址发起转账,而该接收地址又被其他用户所持有,从而形成了用户之间的间接资金关联。
总结而言,传统数据库优化的是数据本身的存储与检索,而图数据库优化的是认知方式。它让机器第一次具备了接近人类的直觉能力——快速看懂事物之间的来龙去脉。
二、装得下数据、跑得赢变局: 千亿点万亿边的毫秒级解决方案
真实世界的关系网络呈指数级膨胀。 全球金融交易网络、跨境供应链、企业级知识库,这些场景对应的往往是千亿级节点和万亿级边的海量数据。
如何做到装得下整个世界的同时,还能快得赢瞬息万变?这正是原生分布式图数据库的硬核价值所在。
以国内排名第一的图数据库代表 NebulaGraph 为例,通过云原生分布式架构,实现了在海量数据下的高并发与毫秒级响应:
- 存算分离,装得下数据:计算层负责解析和优化查询;存储层专为图结构设计,负责点边数据的分布式存储。这种架构允许两边独立扩展,系统能够海纳百川地吞吐万亿级的点边数据。
- **多模态融合,查得全数据:在 NebulaGraph AI 应用平台中,将向量索引、图索引、全文索引、融合图索引相结合,根据查询要求,自动选择最快的查询方式与路径,可在一个系统里同时处理 PDF、图片、Excel、PPT 等多模态数据的文档结构、实体关系、语义相似性。
- 动态演进,跑得赢变局:NebulaGraph 支持灵活的 Schema 动态演进,无需迁移即可秒级扩展新的实体类型、关系边以及属性。这种设计天然适配本体(Ontology)的持续演化,满足语义网中的开放世界假设(Open World Assumption, OWA)——即系统承认知识是不完整的、动态新增的,AI 可以在不中断生产业务的前提下,随时将新发现的商业网络或知识关联插入图中。**
三、2026 年图数据库场景全景
(一)经典通用场景
在 AI 爆发之前,图数据库就已经是解决大规模、高并发复杂关联问题的绝对刚需。几乎所有涉及复杂系统的行业,最终其业务都会演化为一张图。
1. Web3 风控
将区块链地址、智能合约等建模为节点,资金转移或合约调用建模为边,构建完整的链上交易图谱。
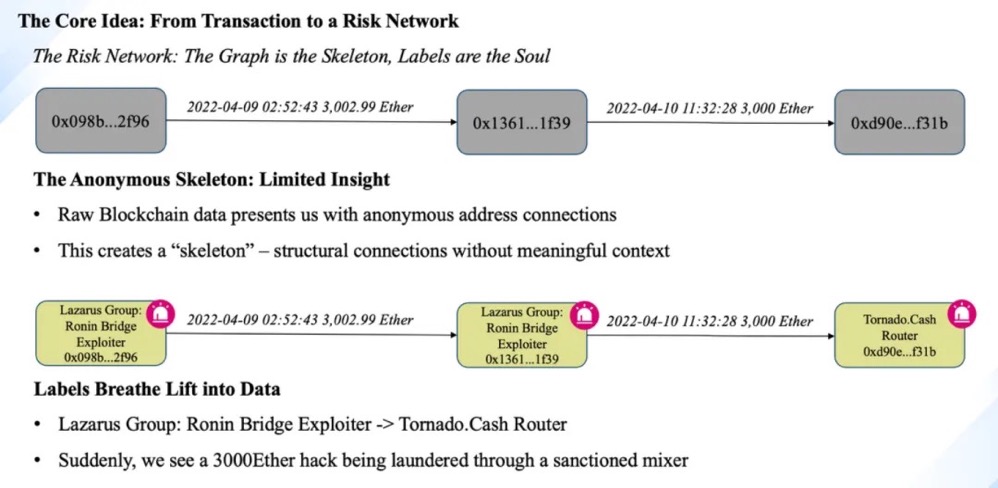
BlockSec 基于 NebulaGraph 构建了加密风控系统,通过给地址打标签,结合启发式算法量化风险。当检测到与制裁地址或黑客地址存在资金往来时,系统可在毫秒级内完成多跳路径追溯,即使资金经过混币器或多层跨链转移,也能还原完整的资金流转脉络。
2. 互联网金融反欺诈
在互联网金融信贷业务中,欺诈行为往往呈现团伙化、隐蔽化的特点。传统的基于规则或单一维度的风控系统难以发现隐藏在复杂关联中的风险。图数据库能够将用户、设备、证件、账户等实体以及它们之间的绑定关系构建为一张关联网络,并通过图算法和关联分析挖掘潜在欺诈团伙、识别风险传导路径。
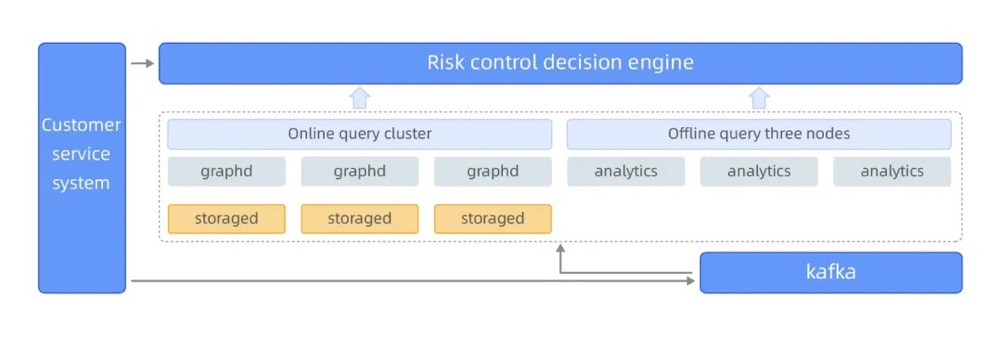
EasyCash 使用 NebulaGraph 企业版后,实现欺诈拦截率提升 240%,审核压力下降 70% 的业务收益。
3. 电商实时推荐引擎
将用户、商品、属性等实体作为异构图中的节点,购买、浏览、收藏等行为作为边,通过多跳路径查询找出与当前用户行为模式相似的其他用户所关联的商品。
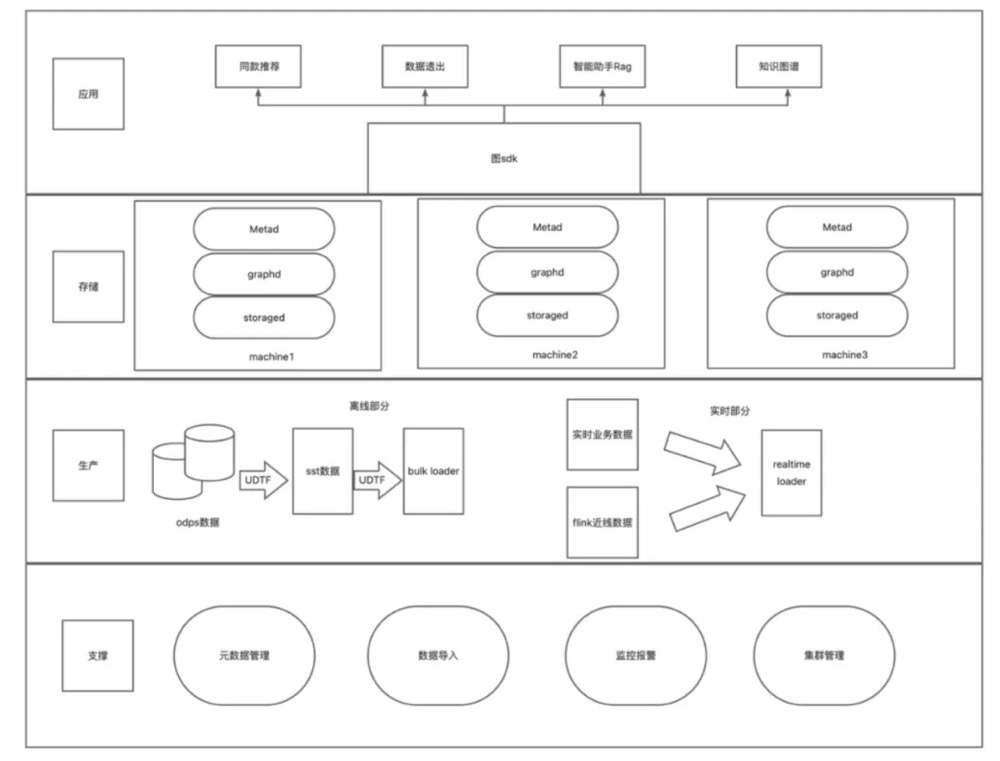
阿里妈妈基于 NebulaGraph 构建了百亿级实时营销推荐系统,在同款异常点检测场景中,通过 1 跳和 2 跳子图查询提取商品邻接信息,将离群点检测的 AB 实验效果提升了 2 个百分点。
(二)AI 时代催生的四大关键场景
图数据库凭借看得懂世界、装得下数据、跑得赢变局的核心优势,在 AI 时代不仅没有淡出,反而因为与大模型的深度互补,成为了企业构建 AI 基础设施的刚需。
1. GraphRAG:知识图谱与检索增强的融合
GraphRAG 是前两年图数据库最受关注的应用方向之一。
传统的 Vector RAG(向量检索增强生成)仅仅依赖文本片段的向量相似度匹配,切碎的文本块丢失了实体间的逻辑网络。在面临“请分析 A 公司的主要竞争对手在过去三年的供应链风险变化”这类需要跨文档、多实体联合推理的复杂长文本问题时,传统 RAG 极易给出拼凑的、似是而非的幻觉答案。
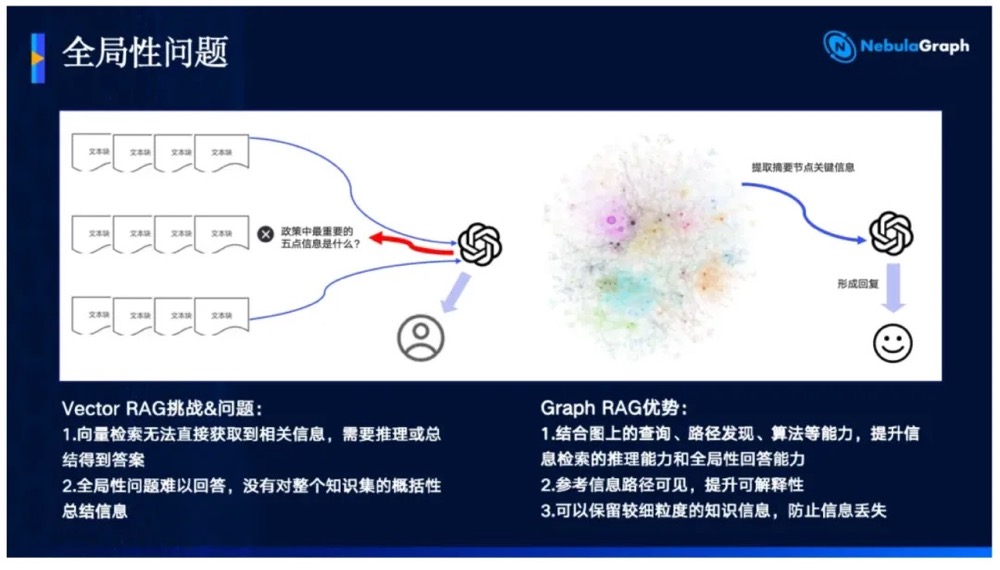
NebulaGraph 率先提出的 GraphRAG(图检索增强生成) 实现了结构化知识图谱与非结构化向量的完美融合:
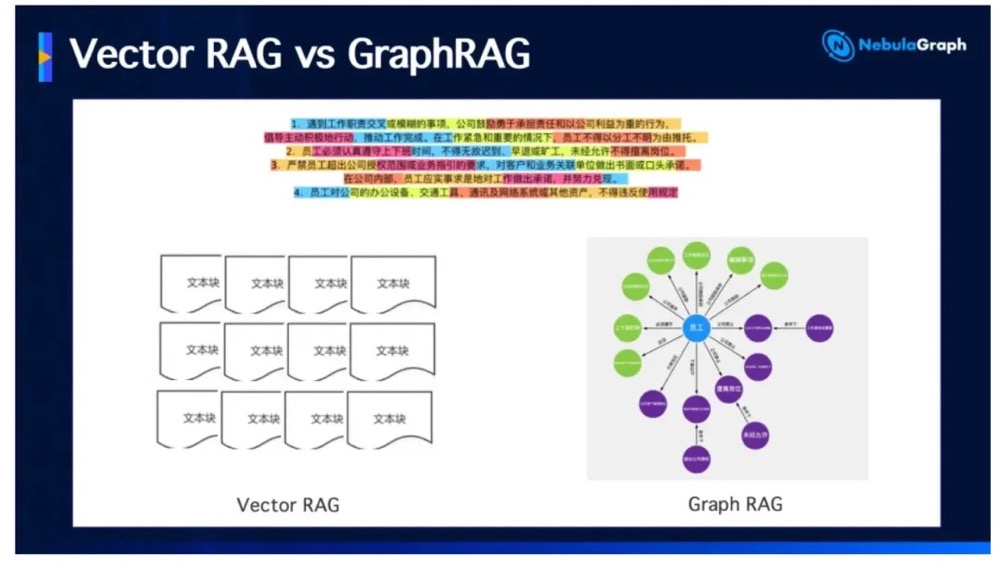
- 提取期:利用大模型异步从海量企业文档中提取出实体、关系及属性,写入图数据库,沉淀为高质量的企业知识图谱。
- 检索期:采用混合检索(Hybrid Search)。首先通过向量召回相关上下文,再沿图数据库的拓扑结构进行多跳关系拓扑扩散,将完整的知识网络、上下游实体链作为精确的 Prompt 上下文喂给大模型。
2. Fusion GraphRAG:给大模型装上智能导航
面对多模态数据时代的新变化,NebulaGraph 在知识图谱之上,创新地增加了一层 Fusion Graph Index(融合图索引),将非结构化文档解析为层次化目录树结构,实现了文档物理结构与网状实体关系的深度统一:
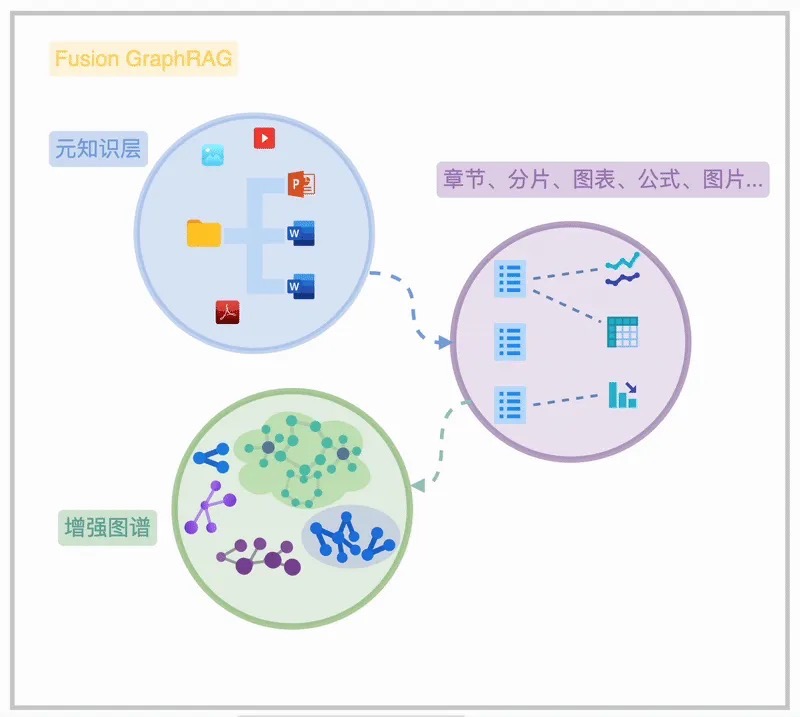
- 构建期:利用大模型将复杂的非结构化多模态文档(PDF、Excel、PPT 等)直接解析为层次化的目录树网络,并与底层图数据库的实体关系无缝交织。
- 推理期:采用动态结构推理。这层树状网络作为上下文内索引直接置于大模型的推理视野中,大模型得以像人类专家一样,根据用户意图智能导航,动态决定用何种检索方式、沿哪条章节脉络进行深度检索,彻底摆脱幻觉式召回。
3. Ontology:AI 理解业务世界的语义骨架
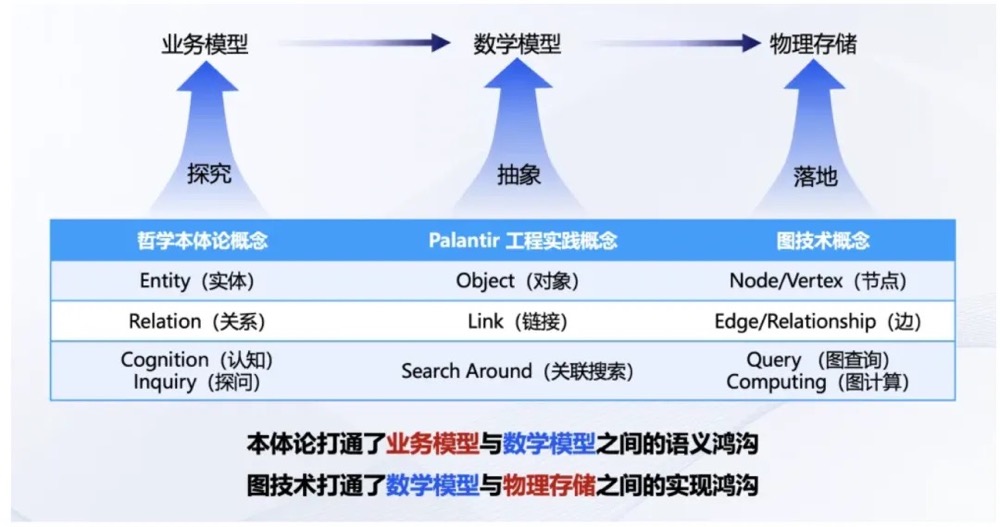
大模型虽然具备强大的通用理解力,但在面对特定企业复杂的内部运行机制(如:复杂的组织架构、交叉持股、特定工业设备的级联故障定义)时,依然缺乏常识。
Palantir 让 Ontology 从哲学概念走入 AI 工程。它通过对企业中对象–关系–行为的抽象建模,让数据与业务之间建立可操作、可推理的连接。基于本体的 Agent 模型能根据领域本体精准生成应用,而不是按照简单 prompt 做通用回应。有了 Ontology 这个骨架,基于本体的 Agent 模型就能精准、合规地生成特定领域的应用代码或业务决策。
4. AI Agent 与长期记忆系统
2025 年是 AI Agent 走向全面工程化的分水岭。大模型在架构上天然缺乏长期记忆能力,频繁重传历史信息不仅推高了 Token 损耗,且无法沉淀出真正的可演进型智能体。
图结构是人类记忆网络的最佳数字孪生。通过图数据库构建 Agent 记忆系统,不仅能记录离散的事件(节点),更能编码时间戳、语义含义以及事件之间的因果与逻辑连接(边)。如 PolarDB PostgreSQL 版在探索 AI 长期记忆的方案中,就采用了向量数据库+图数据库的架构设计,以适配长期个性化服务的场景,如企业知识库、金融风控动态规则库等。
四、图数据选型之不完全指南
全球图数据库市场正在经历一轮爆发式的增长,2025 年全球图数据库市场规模为 28.5 亿美元,预计未来将从 2026 年的 36 亿美元增长到 2034 年的 202.9 亿美元,根据 ZDNet 及 Gartner 的联合报告,图数据库已成为整个数据库市场中增长最快的细分领域。
在 2026 年的工业语境下,企业想选型一款优秀的图数据库,建议深度参考以下指标:
1. 规模上限
是否具备原生分布式扩展能力?随着业务演进,图数据会呈指数级膨胀。选型时不能仅看 Demo 阶段的性能,必须考核系统在千亿节点、万亿条边的超大规模下,能否通过存算分离架构进行横向弹性扩展。
## 2. 检索维度
是否支持“图+向量+全文+融合图”的多维检索方式? 2026年的前沿智能化应用(如 Fusion GraphRAG、Agent 长期记忆),涵盖多模态数据,优秀的图数据库必须在一个系统中实现多模态智能检索,且具备动态推理能力。
3. 时效演进
是否支持动态 Schema?AI 时代的企业本体(Ontology)和业务场景日新月异,选型必须考察系统是否支持 Schema 的灵活动态演进。当需要新增一种实体类型或关系边时,系统必须做到秒级扩展,无需锁表,更无需进行痛苦的数据迁移。
4. 智能化图算法
是否具备可自定义图算法、支持 Text2GQL 的能力?当关系规模进入万亿时代,智能化、业务化的计算才是核心问题。需在算得快的基础上,进一步考察是否支持自定义图算法、能否实现输入自然语言自动转换为可运行的图算法。只有将业务人员从提交需求中解放出来,直接聚焦业务逻辑,才能大幅缩短开发周期,让业务真正贴近真实场景。
五、 热点会变,但现实的关系不会消失
从知识图谱、GraphRAG、本体论、AI Agent 长期记忆系统,到未来的图智能,技术的名词或许会随着周期的更迭而不断翻新,但这些概念的底层逻辑始终如一:它们都是现实世界图结构在不同 AI 演进阶段的具体工程化表现。
热点会变,但人类社会与商业运行中的错综关系永远不会消失。对于试图在 AI 时代构建长期技术护城河的企业而言,理解图、掌握图、布局原生分布式图基础设施,不是一个关于未来的选择,而是一个决定当下的必答题。
如果您的企业正面临万亿级深层风控穿透瓶颈,或正在重构基于多模态文档的 Fusion GraphRAG 架构,欢迎点击下方链接填写技术咨询问卷。 https://wj.qq.com/s2/15344088/w7ei/
交流图数据库技术?加入 Nebula 交流群请先填写下「你的 Nebula 名片」,Nebula 小助手会拉你进群~~