
产品实践
星云实验室 part 1|用知识图谱+GraphRAG,构建垂直领域 AI 应用
导读:如何提升 RAG 的效果?如何把 NebulaGraph 和大模型相结合?我们将用五期「星云实验室」,手把手教大家围绕知识图谱+GraphRAG, 从 0 到 1 搭建一款垂直领域 AI 应用。
重点速览:
搭建 AI 环境
部署 NebulaGraph 图数据库

一、背景
“怎样提升 RAG 的效果?”、“为什么我做的 RAG 那么差?”、“检索不全啊,答非所问,怎么办?”……
从前端查询,到最后大模型的回答,其中的整个链路,充满变数与选择,传统意义的 RAG 非常容易做出来,但是能交付的,非常考究设计,而知识图谱便是重要一环。
知识图谱可以在一定程度上增强 RAG :
(一)找到的就是相关的
相似,不等于相关,比如我们做医疗 RAG 项目,心绞痛 ≠ 胆绞痛,二者虽有 2 个字相同,但是两个名词是完全不同概念。通过知识图谱查到的信息,找到的索引,它背后会通过相关的边,连接在一起。给大模型参照的信息中,还连带上多个节点形成的背景。
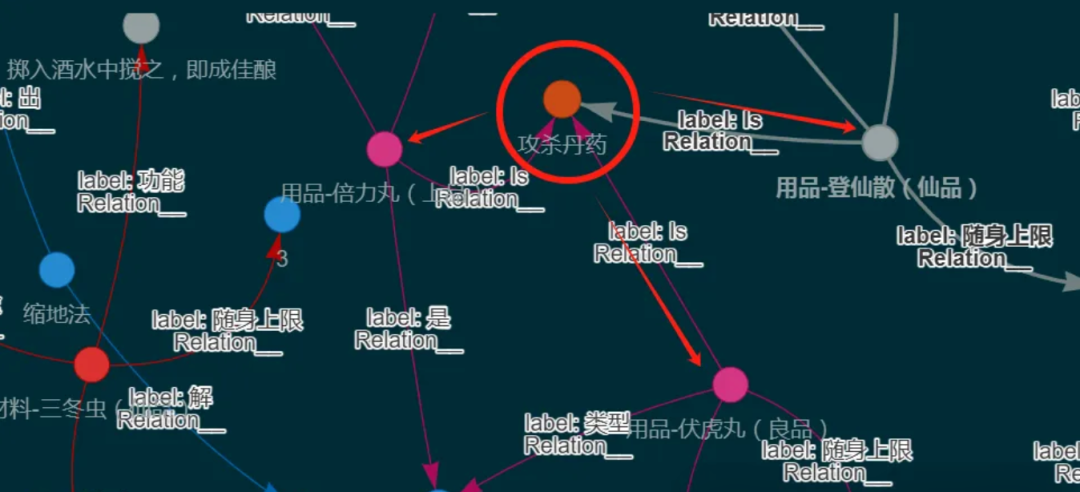
(二)提升巨量数据检索性能
面对巨量的数据,大概到千万 tokens,系统陷入困惑,性能开始下降。因为相似的 tokens 太多了,无法定位到文本块,当然,通过多种的处理策略:文本块标签、查询扩写编排等手段可以解决问题,但做过的朋友就知道,这有多烦 Orz
知识图谱在数据处理层面,每个命中的节点背后,跟的是对应的问题,甚至你可以通俗理解:知识图谱是一个大文本块的节点集合,是相关的,所以才准。
二、搭建开发环境
推荐搭建环境
操作系统:Linux 实操环境:miniconda/jupyter/docker cuda 版本:12.2及以上 PyTorch:2.3 开发语言:Python 3.10 及以上 知识图谱:NebulaGraph RAG 框架:LlamaIndex 或 LangChain 本地大模型:Qwen2-7B(高并发 VLLM 部署,灵活自定义) 嵌入索引模型:text2vec-large-chinese 算力要求:无要求,3090*24G(完整体验)或 API 供应商
(一)搭建 AI 环境
建议第一次使用 Linux 系统的同学,选择 win11+Ubuntu24 桌面版双系统,因为它们的系统交互逻辑是相似的,即使是没有用过 Linux 的朋友,也可快速上手。下载 Ubuntu 24.04.1 LTS 版本,安装时选择同步安装显卡驱动,因为已经安装了最新的驱动,所以下载后直接安装 cuda 即可,是匹配的,下载链接⬇️
https://ubuntu.com/download/desktop
部分依赖库,只有 Linux 版本,如果你不打算用 Linux 系统,必须在 WSL 环境下才能跑完全程。
1. cuda 安装
因为系统已经自带英伟达最新驱动,所以 cuda 安装就方便了,如果你没有选择安装驱动,处理比较麻烦,建议新手重新安装系统。
进入系统后,打开终端,执行以下命令安装 cuda,每一行就是一个执行命令:
# 先看看gcc是否正常安装
gcc --version
# 没装的先安装gcc,或者版本太低,都可以通过这个安装
sudo apt install gcc
# 更新Ubuntu
sudo apt update && sudo apt upgrade
# 安装cuda
sudo apt install nvidia-cuda-toolkit
# 安装完后,重启系统
reboot
# 查看是否安装成功
nvcc --version
2. 安装 miniconda
这是一个环境管理工具,每一个环境都是独立的,避免了不同环境的依赖冲突问题。同时这也是学习 AI 必须要会的工具,如果你习惯其他环境管理工具,可以用自己熟悉的,如果是刚开始学,建议跟着我们来实操。
# 创建一个文件夹,稍后存放下载的安装文件
mkdir -p ~/miniconda3
# 下载miniconda
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh -O ~/miniconda3/miniconda.sh
# 安装,需要一直点回车,看到输入yes/no时,输入yes,回车
bash ~/miniconda3/miniconda.sh -b -u -p ~/miniconda3
# 删除安装包
rm ~/miniconda3/miniconda.sh
3 安装 Python+PIP
推荐使用 Python3.11,至少 3.10 版本,便于后面 AI 环境的操作。
3.1 安装 Python 3.11
打开终端,依次执行
# 更新Ubuntu
sudo apt update && sudo apt upgrade
# 导入包含最新稳定版本的 Python 存储库
sudo add-apt-repository ppa:deadsnakes/ppa -y
# 更新Ubuntu
sudo apt update
# 安装3.11
sudo apt install python3.11
# 查看是否成功
python3.11 --version
# 安装所有Python附加功能(可选)
sudo apt install python3.11-full
3.2 安装 PIP
我们下载许多库和包,都需要用 PIP 下载,到手后,也必须安装的,打开终端:
# 直接安装
sudo apt install python3-pip
# 如果安装不成功,手动安装
# 手动下载
wget https://bootstrap.pypa.io/get-pip.py
# 手动安装
python3 get-pip.py
# 升级一下版本
python3 -m pip install --upgrade pip
# 查看是否安装成功
pip --version
搞定以上,我们开始搭建知识图谱环境。
(二)部署 NebulaGraph
知识图谱是一种使用图结构的数据模型或拓扑来集成数据的知识库。三元组是知识图谱的基本数据单元,而 NebulaGraph 图数据库可通过存储三元组来高效地存储和查询复杂的图数据,从而实现知识图谱的搭建。
以下有三种 NebulaGraph 的部署方式,可根据实际情况进行选择。
| 序号 | 应用场景及部署方式 | 系统平台 | 部署难度 | 性能评级 |
|---|---|---|---|---|
| 1 | 学习-快速部署 | 多系统通用 | ★ | ★★★ |
| 2 | 实践-单机部署 | Linux 系统 | ★★ | ★★★★ |
| 3 | 生产-集群部署 | Linux 系统 | ★★★★★ | ★★★★★ |
1. 学习-快速部署
docker 部署,主打快,0 代码部署,多平台支持,包含了 NebulaGraph 图数据库+ NebulaGraph Studio
下载地址⬇️
https://hub.docker.com/extensions/weygu/nebulagraph-dd-ext
本地点击 NebulaGraph Studio,即跳转到登录界面,填上本机 IP 即可登录,默认端口 9669,如未启用身份验证,填写默认用户名 root 和任意密码,如已启用,密码则为 nebula.

2. 实践-单机部署
本系列教程推荐单机部署,同样条件下,有不错的性能同时,部署还相对简单。
2.1 使用 tar.gz 文件安装 NebulaGraph
请参考 NebulaGraph 3.8.0 官方文档⬇️
https://docs.nebula-graph.com.cn/3.8.0/4.deployment-and-installation/2.compile-and-install-nebula-graph/4.install-nebula-graph-from-tar/
2.2 使用 RPM 或 DEB 包安装 NebulaGraph
请参考 NebulaGraph 3.8.0 官方文档⬇️
https://docs.nebula-graph.com.cn/3.8.0/4.deployment-and-installation/2.compile-and-install-nebula-graph/2.install-nebula-graph-by-rpm-or-deb/
3. 生产-集群部署
3.1 硬件要求
既然到了生产需求,不得不说硬件要求,我们要生产使用,所以必须要有一定硬件:
| 类型 | 要求 |
|---|---|
| CPU 架构 | x86_64 |
| CPU 核数 | 48 |
| 内存 | 256 GB |
| 硬盘 | 2 * 1.6 TB,NVMe SSD |
| GPU | 最低 3090 双卡(24G*2),两个 7B 左右模型一个做图谱,一个做 chat |
3.2 存储硬件
NebulaGraph 是针对 NVMe SSD 进行设计和实现的,所有默认参数都是基于 SSD 设备进行调优,要求极高的 IOPS 和极低的 Latency.
不建议使用 HDD;因为其 IOPS 性能差,随机寻道延迟高。
不要使用远端存储设备(如 NAS 或 SAN),不要外接基于 HDFS 或者 Ceph 的虚拟硬盘。
不建议配置独立磁盘冗余阵列(RAID)。NebulaGraph 本身提供多副本机制,配置 RAID,会造成资源浪费
使用本地 SSD 设备;或 AWS Provisioned IOPS SSD 或等价云产品。
以上,仅仅是知识图谱能应用于生产的基本要求,如果你还需要结合大模型来做生产,那这个硬件配置还需要往上走,所以,目前大模型的推理成本比较高,如果你没有确切的需求,建议先用 API 来测试,统计 tokens 吞吐数据,再规划算力平台。
3.3 使用 RPM/DEB 包部署 NebulaGraph 多机集群
请参考 NebulaGraph 3.8.0 官方文档⬇️
https://docs.nebula-graph.com.cn/3.8.0/4.deployment-and-installation/2.compile-and-install-nebula-graph/deploy-nebula-graph-cluster/
三、总结
本期「星云实验室」带领大家完成了 AI 环境的搭建和 NebulaGraph 的部署,下期我们将介绍如何在本地接入大模型和文本编码模型,并利用模型对现有文件生成知识图谱数据,并将知识图谱数据接入到 RAG 框架中提高回答准确性。
今天的“作业”完成了吗?欢迎在评论区“交作业”~
NebulaGraph 邀你参加开源之夏🌟⬇️


