行业科普
故障发生时,如何让根因定位有迹可循
在数字化业务成为企业核心竞争力的今天,系统稳定性直接关乎用户体验与商业信誉。作为运维工程师,你经历过这样的至暗时刻:凌晨三点,监控大屏瞬间被告警刷屏,电话铃声此起彼伏。大家手忙脚乱地在一堆日志、监控图表和拓扑图之间来回切换,却像盲人摸象般难以拼凑出完整的故障全貌。
视角割裂导致根因定位时间过长
这正是当前复杂 IT 系统运维的普遍痛点——数据孤岛、依赖关系不透明、根因定位耗时过长。微服务和云原生架构早已成为主流,一个业务请求往往需要穿越成百上千个服务节点。传统的监控工具擅长采集指标(Metric)、日志(Log)和链路(Trace),但这些数据往往是割裂的。
当故障来临时,我们面临的首要难题是视角割裂:负责网络的同学看交换机,负责应用的同学看服务监控,负责数据库的同学看慢查询,大家很难在短时间内达成共识。
此时,如果有一套机制能像侦探一样,把散落的线索串联成完整的证据链,是不是就能让真相水落石出?这就是 NebulaGraph 的用武之地。
传统运维的窘境:缺少关系
我们先看一个真实的困境。假设某电商平台在大促前夕出现“用户登录失败”的报错。监控系统同时触发了以下告警:
- 应用 A 的接口响应超时
- 数据库 C 的连接数飙高
- 物理机 H 的 CPU 负载突破阈值
- 网络交换机 S 有丢包记录
这些告警来自不同的监控系统,时间戳相近,但彼此之间没有显式关联。运维工程师需要打开四五个控制台,分别查看日志、链路、基础设施监控,再凭经验在大脑中手动拼接因果链。如果这位工程师恰好对这套系统不熟悉,排查时间就会被无限拉长。
问题的本质在于:数据有了,但数据之间的关系丢了。
用图数据库重构运维知识图谱
图数据库的核心优势在于处理关联数据。在运维场景中,系统本身就是一张巨大的网:物理机、宿主机、虚拟机、容器、应用服务、API、数据库……它们之间天然存在着“部署于”“调用”“依赖”等关系。
NebulaGraph 允许我们打破 CMDB、调用链、监控指标的数据壁垒,将这些实体作为节点(Vertex),关系作为边(Edge),构建出运维知识图谱。
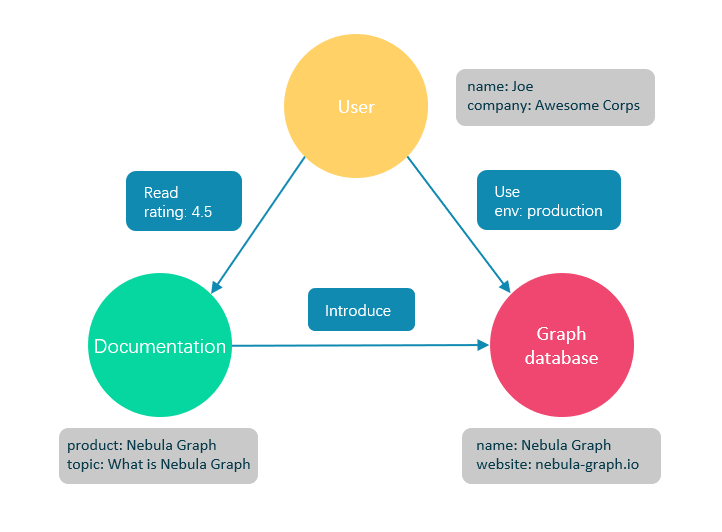
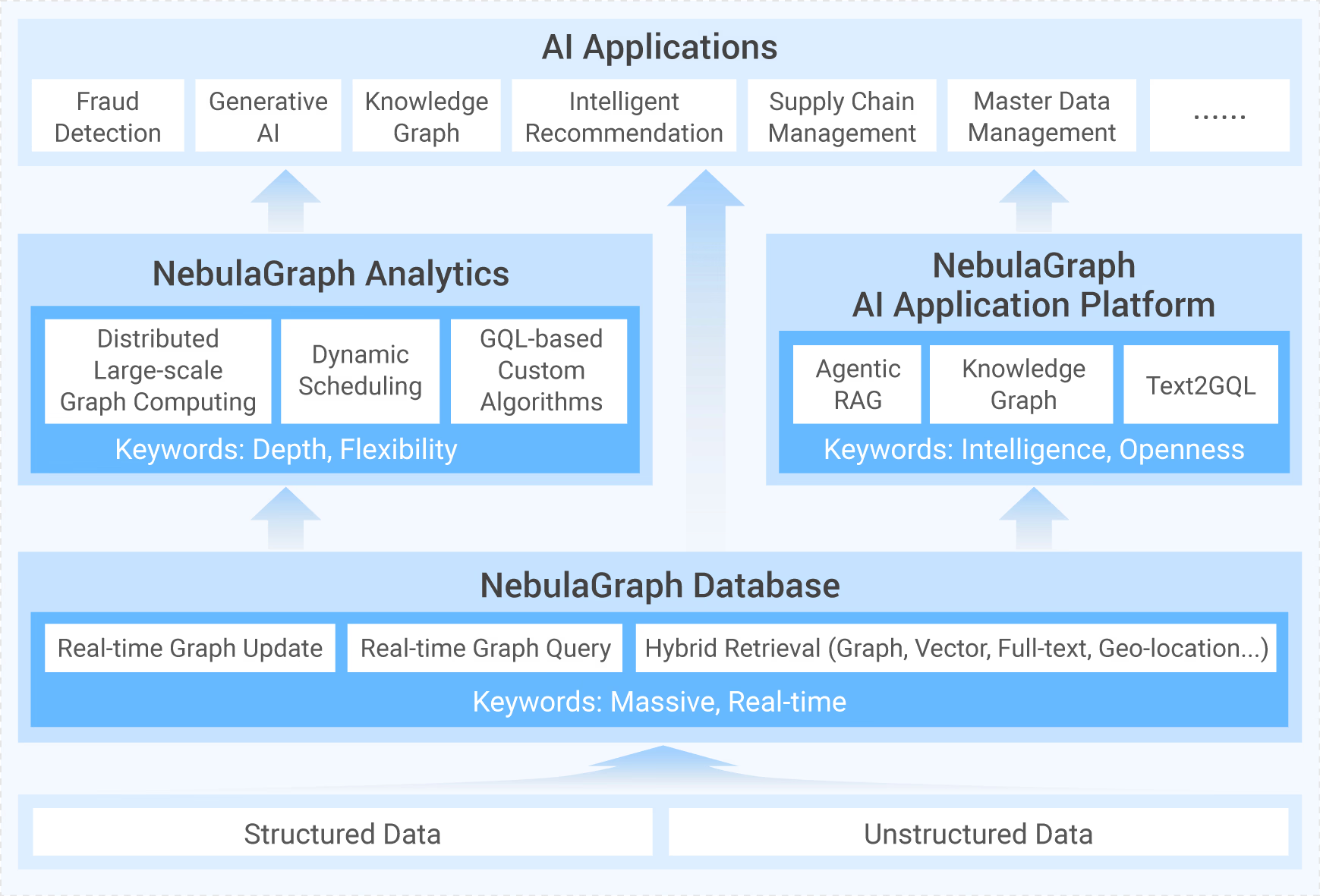
例如,我们可以清晰地建模出:
- 物理机 A 包含虚拟机 B
- 虚拟机 B 运行着微服务 C
- 微服务 C 调用了数据库 D
- 数据库 D 部署于物理机 E
有了这张图,我们就不再是只看到孤立的告警,而是能看到告警背后的传播路径。
而且,NebulaGraph 原生分布式架构支持千亿级节点和边的存储与查询,即便是在拥有数万台服务器的超大规模集群中,关系查询也能在毫秒级返回结果。这在运维场景中至关重要,因为故障的每一秒都意味着真金白银的损失。
故障处理流程的智能化改造
让我们结合 NebulaGraph 的能力,重新梳理一下高效的故障处理流程:
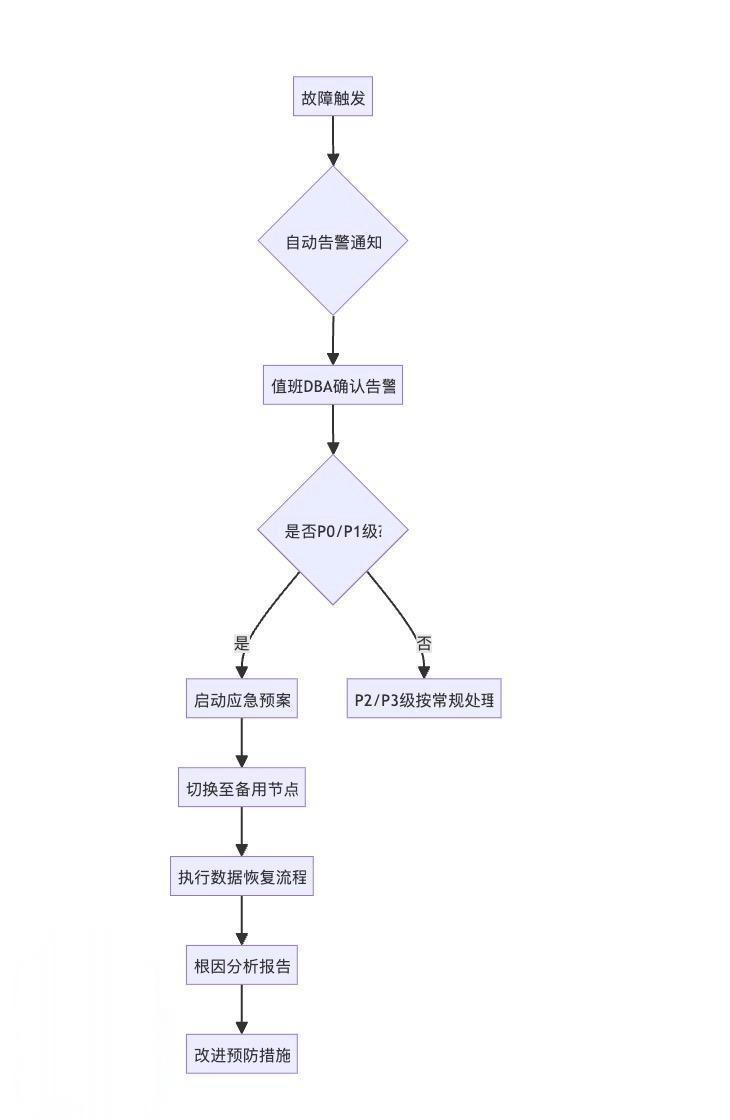
如图所示,当告警触发后,值班 DBA 或 SRE 确认等级。若为 P0/P1 级核心故障,传统的做法是“启动应急预案、切换备用节点、执行数据恢复”。 这个过程虽然能快速止损,但真正的难点在于事后的“根因分析报告”和“改进预防措施”。而这恰恰是图数据库最能发挥价值的地方。
基于 NebulaGraph 的运维图谱平台,能够在故障处理的事中与事后两个阶段显著提效:
1. 告警收敛:
在 NebulaGraph 的运维图谱中,我们可以通过图查询语言直接定位“连接数最多”或“依赖路径最上游”的异常节点。
2. 根因路径可视化
过去,我们依赖“老兵”的经验直觉去猜根因。现在,通过将调用链数据、基础设施拓扑、变更事件统一导入 NebulaGraph,我们可以用图查询直接获取一条故障影响路径:
网卡丢包 → 物理机负载升高 → 数据库连接超时 → 订单服务不可用 → 用户端报错
这条路径在图上以节点和边的形式清晰呈现,每个节点都可以点击查看详细监控数据和日志。值班工程师不再需要在多个系统间跳转,一个控制台就能完成端到端的追踪。
3. 影响面分析
在实施切换至备用节点或重启服务等恢复措施前,运维人员需要知道“这一刀切下去会影响谁”。在图谱上执行一次依赖查询,几毫秒内就能圈定受影响的上游服务列表和相关业务线,帮助决策者更安全地操作,避免二次事故。
运维协同的图视角
除了系统层面的分析能力,NebulaGraph 还能优化人与人的协作效率。
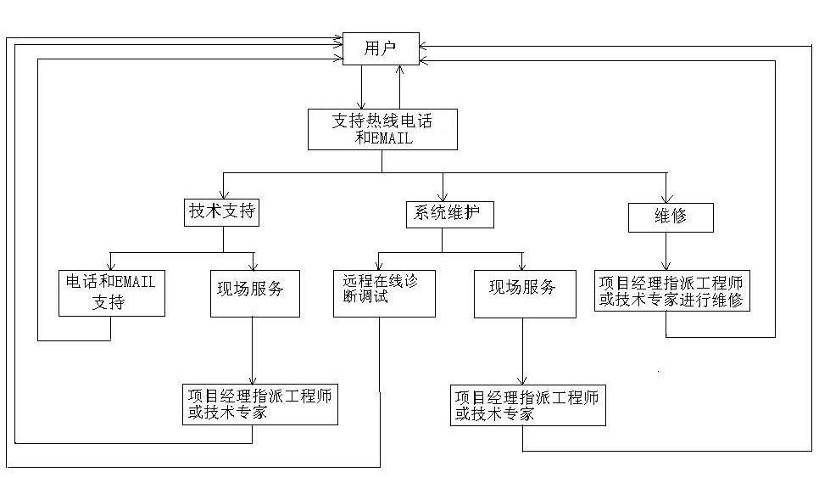
如图所示,在传统的支持模式中,从用户拨打热线或发送 Email 反馈问题,到项目经理指派工程师,再到现场或远程维修,信息传递链很长。当问题升级到需要技术专家介入时,专家往往是“空降”到故障现场,对前置的告警历史、变更记录、拓扑关系一无所知,需要重新花时间去了解上下文。
有了统一的运维知识图谱,当“项目经理指派工程师或技术专家”时,所指派的专家可以立即获得一张由 NebulaGraph 实时计算出的现场全景图:故障现场的网络拓扑、最近 1 小时的变更记录、上下游依赖关系、相关历史故障案例。
这样一来:
- 远程在线诊断调试的工程师,可以边看图谱边执行命令,不再需要反复电话确认“这个服务跑在哪台机器上”;
- 现场服务的工程师到达客户机房后,打开图谱即可获得与后方专家完全一致的视图,沟通效率大幅提升;
- 电话和 Email 支持的客服人员,也能通过简化版的图谱视图快速理解问题影响范围,准确转达给技术团队。
这大大减少了信息同步本身所消耗的宝贵时间——据我们客户的实测数据,在引入图数据库统一运维视图后,跨团队沟通成本降低了约40%。
更长远的价值:构建组织级的运维记忆
值得一提的是,NebulaGraph 运维图谱的价值不仅在于当下的故障处理,更在于它天然适合沉淀组织级的运维知识资产。
每一次故障处理完毕后,根因节点、影响路径、处理措施都可以作为新的边和属性写入图谱。数月之后,当类似的故障再次出现时,系统可以自动关联历史记录,帮助当值工程师快速参考先前的处理经验。过去只能靠人工的经验,现在变成了图谱里可查询、可追溯的“硬数据”。
结语
在智能运维实践中,仅仅收集数据是不够的,我们需要理解数据之间的关系。NebulaGraph 通过构建高可用的运维关系图谱,正在将人工救火转变为有序疏导。当关系被理清,复杂也就变得简单。让每一次故障排查都有迹可循,让每一次应急响应都更加从容。